 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Vision and Language: Codebook Anchored Visual Adaptation
Feb 23, 2026Large Vision-Language Models (LVLMs) use their vision encoders to translate images into representations for downstream reasoning, but the encoders often underperform in domain-specific visual tasks such as medical image diagnosis or fine-grained classification, where representation errors can cascade through the language model, leading to incorrect responses. Existing adaptation methods modify the continuous feature interface between encoder and language model through projector tuning or other parameter-efficient updates, which still couples the two components and requires re-alignment whenever the encoder changes. We introduce CRAFT (Codebook RegulAted Fine-Tuning), a lightweight method that fine-tunes the encoder using a discrete codebook that anchors visual representations to a stable token space, achieving domain adaptation without modifying other parts of the model. This decoupled design allows the adapted encoder to seamlessly boost the performance of LVLMs with different language architectures, as long as they share the same codebook. Empirically, CRAFT achieves an average gain of 13.51% across 10 domain-specific benchmarks such as VQARAD and PlantVillage, while preserving the LLM's linguistic capabilities and outperforming peer methods that operate on continuous tokens.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Benchmarking Low-Shot Robustness to Natural Distribution Shifts
Apr 21, 2023



Robustness to natural distribution shifts has seen remarkable progress thanks to recent pre-training strategies combined with better fine-tuning methods. However, such fine-tuning assumes access to large amounts of labelled data, and the extent to which the observations hold when the amount of training data is not as high remains unknown. We address this gap by performing the first in-depth study of robustness to various natural distribution shifts in different low-shot regimes: spanning datasets, architectures, pre-trained initializations, and state-of-the-art robustness interventions. Most importantly, we find that there is no single model of choice that is often more robust than others, and existing interventions can fail to improve robustness on some datasets even if they do so in the full-shot regime. We hope that our work will motivate the community to focus on this problem of practical importance.
Adapting Self-Supervised Vision Transformers by Probing Attention-Conditioned Masking Consistency
Jun 16, 2022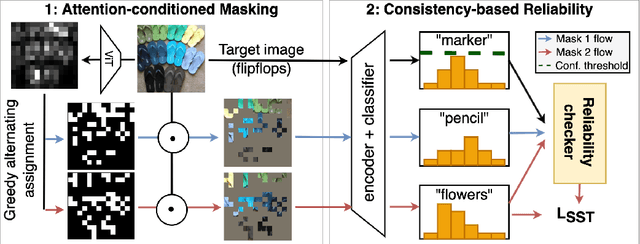
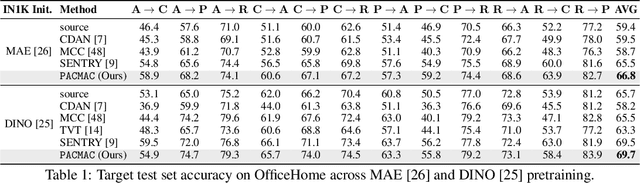
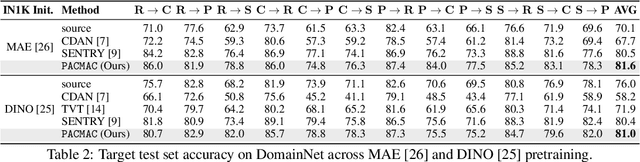
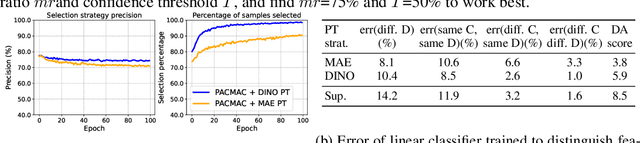
Visual domain adaptation (DA) seeks to transfer trained models to unseen, unlabeled domains across distribution shift, but approaches typically focus on adapting convolutional neural network architectures initialized with supervised ImageNet representations. In this work, we shift focus to adapting modern architectures for object recognition -- the increasingly popular Vision Transformer (ViT) -- and modern pretraining based on self-supervised learning (SSL). Inspired by the design of recent SSL approaches based on learning from partial image inputs generated via masking or cropping -- either by learning to predict the missing pixels, or learning representational invariances to such augmentations -- we propose PACMAC, a simple two-stage adaptation algorithm for self-supervised ViTs. PACMAC first performs in-domain SSL on pooled source and target data to learn task-discriminative features, and then probes the model's predictive consistency across a set of partial target inputs generated via a novel attention-conditioned masking strategy, to identify reliable candidates for self-training. Our simple approach leads to consistent performance gains over competing methods that use ViTs and self-supervised initializations on standard object recognition benchmarks. Code available at https://github.com/virajprabhu/PACMAC
SAFIN: Arbitrary Style Transfer With Self-Attentive Factorized Instance Normalization
May 20, 2021


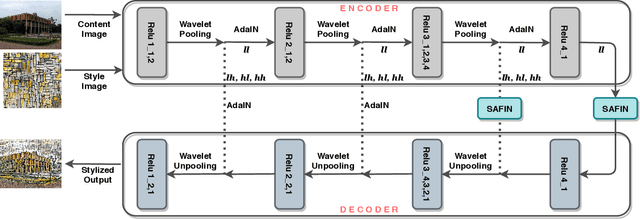
Artistic style transfer aims to transfer the style characteristics of one image onto another image while retaining its content. Existing approaches commonly leverage various normalization techniques, although these face limitations in adequately transferring diverse textures to different spatial locations. Self-Attention-based approaches have tackled this issue with partial success but suffer from unwanted artifacts. Motivated by these observations, this paper aims to combine the best of both worlds: self-attention and normalization. That yields a new plug-and-play module that we name Self-Attentive Factorized Instance Normalization (SAFIN). SAFIN is essentially a spatially adaptive normalization module whose parameters are inferred through attention on the content and style image. We demonstrate that plugging SAFIN into the base network of another state-of-the-art method results in enhanced stylization. We also develop a novel base network composed of Wavelet Transform for multi-scale style transfer, which when combined with SAFIN, produces visually appealing results with lesser unwanted textures.
An End-to-End Network for Emotion-Cause Pair Extraction
Mar 03, 2021
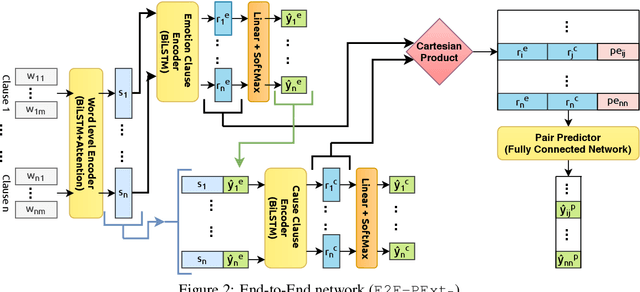

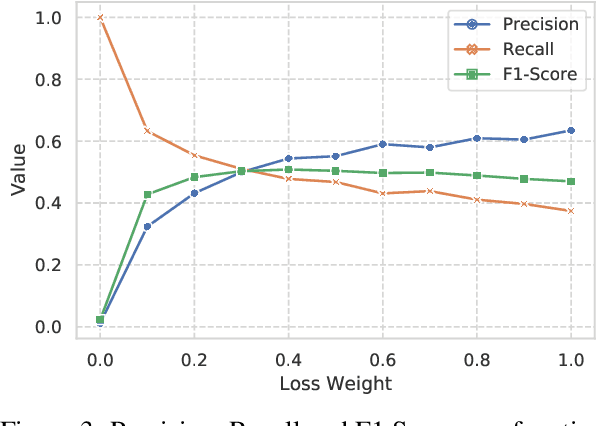
The task of Emotion-Cause Pair Extraction (ECPE) aims to extract all potential clause-pairs of emotions and their corresponding causes in a document. Unlike the more well-studied task of Emotion Cause Extraction (ECE), ECPE does not require the emotion clauses to be provided as annotations. Previous works on ECPE have either followed a multi-stage approach where emotion extraction, cause extraction, and pairing are done independently or use complex architectures to resolve its limitations. In this paper, we propose an end-to-end model for the ECPE task. Due to the unavailability of an English language ECPE corpus, we adapt the NTCIR-13 ECE corpus and establish a baseline for the ECPE task on this dataset. On this dataset, the proposed method produces significant performance improvements (~6.5 increase in F1 score) over the multi-stage approach and achieves comparable performance to the state-of-the-art methods.