 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal State Nudging: Reducing Skill Atrophy from AI Assistance
May 19, 2026Skill atrophy, the gradual decline of human capability under AI assistance, poses a safety risk in shared-control of semi-autonomous systems, where operators may be unable to distinguish their own inputs from autonomous corrections. We propose Proximal State Nudging (PSN), a shared autonomy algorithm that jointly optimizes for skill development and task performance by nudging users toward states estimated to be most learnable. We first show that PSN outperforms existing shared autonomy baselines in balancing student improvement in unassisted reward with overall shared performance, using simulated students in the classic LunarLander environment. We then present, to the best of our knowledge, the first human subject studies of a planner incorporating learning-compatible shared autonomy: across two driving tasks in the CARLA simulator (High Performance Racing and Parallel Parking, n = 60), PSN produces up to 7x larger gains in unassisted skill than standard blended shared autonomy, while incurring 50% fewer collisions than unassisted self-practice.
STORY2GAME: Generating (Almost) Everything in an Interactive Fiction Game
May 06, 2025



We introduce STORY2GAME, a novel approach to using Large Language Models to generate text-based interactive fiction games that starts by generating a story, populates the world, and builds the code for actions in a game engine that enables the story to play out interactively. Whereas a given set of hard-coded actions can artificially constrain story generation, the ability to generate actions means the story generation process can be more open-ended but still allow for experiences that are grounded in a game state. The key to successful action generation is to use LLM-generated preconditions and effects of actions in the stories as guides for what aspects of the game state must be tracked and changed by the game engine when a player performs an action. We also introduce a technique for dynamically generating new actions to accommodate the player's desire to perform actions that they think of that are not part of the story. Dynamic action generation may require on-the-fly updates to the game engine's state representation and revision of previously generated actions. We evaluate the success rate of action code generation with respect to whether a player can interactively play through the entire generated story.
Ambient Adventures: Teaching ChatGPT on Developing Complex Stories
Aug 03, 2023

Imaginative play is an area of creativity that could allow robots to engage with the world around them in a much more personified way. Imaginary play can be seen as taking real objects and locations and using them as imaginary objects and locations in virtual scenarios. We adopted the story generation capability of large language models (LLMs) to obtain the stories used for imaginary play with human-written prompts. Those generated stories will be simplified and mapped into action sequences that can guide the agent in imaginary play. To evaluate whether the agent can successfully finish the imaginary play, we also designed a text adventure game to simulate a house as the playground for the agent to interact.
Feature Interaction Interpretability: A Case for Explaining Ad-Recommendation Systems via Neural Interaction Detection
Jun 19, 2020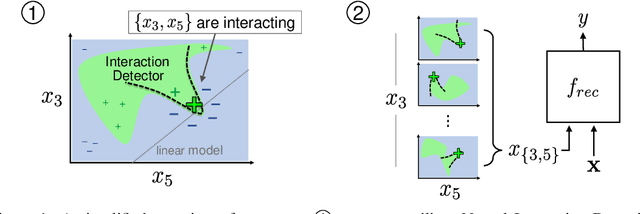
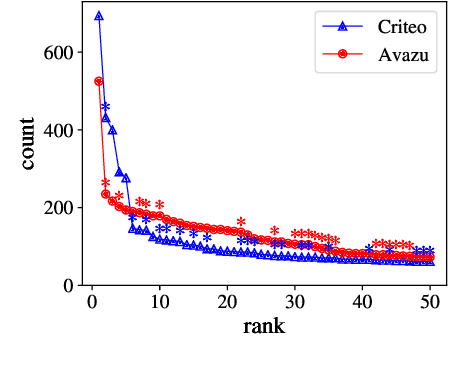


Recommendation is a prevalent application of machine learning that affects many users; therefore, it is important for recommender models to be accurate and interpretable. In this work, we propose a method to both interpret and augment the predictions of black-box recommender systems. In particular, we propose to interpret feature interactions from a source recommender model and explicitly encode these interactions in a target recommender model, where both source and target models are black-boxes. By not assuming the structure of the recommender system, our approach can be used in general settings. In our experiments, we focus on a prominent use of machine learning recommendation: ad-click prediction. We found that our interaction interpretations are both informative and predictive, e.g., significantly outperforming existing recommender models. What's more, the same approach to interpret interactions can provide new insights into domains even beyond recommendation, such as text and image classification.
ShadowSync: Performing Synchronization in the Background for Highly Scalable Distributed Training
Mar 07, 2020
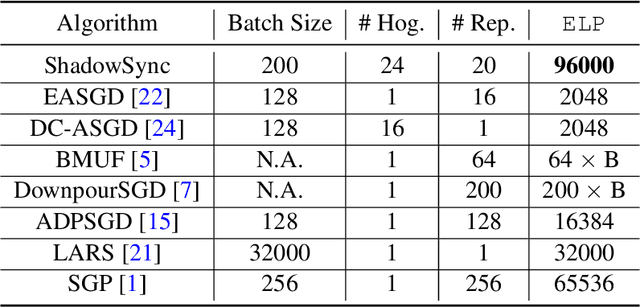
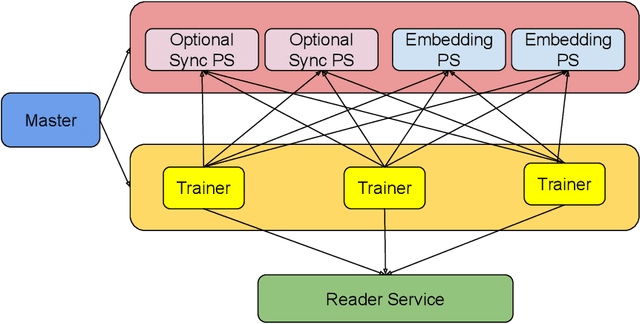
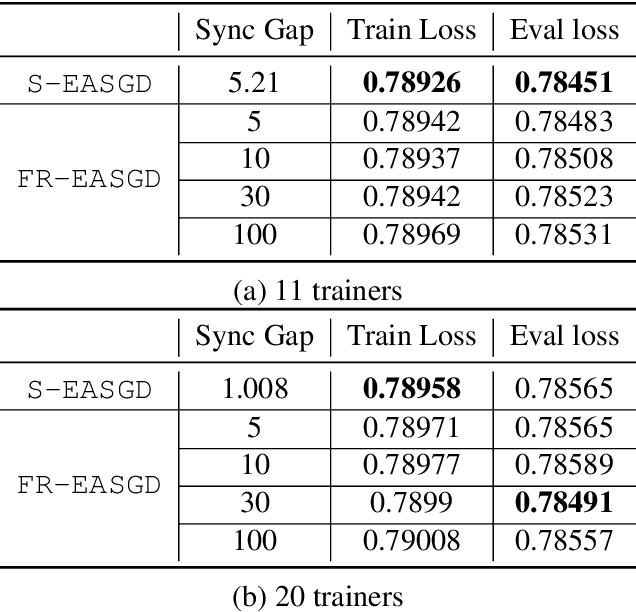
Distributed training is useful to train complicated models to shorten the training time. As each of the workers only sees a small fraction of data, workers need to synchronize on the parameter updates. One of the central questions in distributed training is how to parsimoniously synchronize parameters while preserving model quality. To address this problem, we propose the \textbf{ShadowSync} framework, in which we isolate synchronization from training and run it in the background. In contrast to common strategies including synchronous stochastic gradient descent (SGD), asynchronous SGD, and model averaging on independently trained sub-models, where synchronization happens in the foreground, ShadowSync synchronization is neither part of the backward pass, nor happens every $k$ iterations. Our framework is generic to host various types of synchronization algorithms, and we propose 3 approaches under this theme. The superiority of ShadowSync is confirmed by experiments on training deep neural networks for click-through-rate prediction. Our methods all succeed in making the training throughput linearly scale with the number of trainers. Comparing to their foreground counterparts, our methods exhibit neutral to better model quality and better scalability when we keep the number of parameter servers the same. In our training system which expresses both replication and Hogwild parallelism, ShadowSync also accomplishes the highest example level parallelism number comparing to the prior arts.