 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLESA: Learnable Stage-Aware Predictors for Diffusion Model Acceleration
Feb 24, 2026Diffusion models have achieved remarkable success in image and video generation tasks. However, the high computational demands of Diffusion Transformers (DiTs) pose a significant challenge to their practical deployment. While feature caching is a promising acceleration strategy, existing methods based on simple reusing or training-free forecasting struggle to adapt to the complex, stage-dependent dynamics of the diffusion process, often resulting in quality degradation and failing to maintain consistency with the standard denoising process. To address this, we propose a LEarnable Stage-Aware (LESA) predictor framework based on two-stage training. Our approach leverages a Kolmogorov-Arnold Network (KAN) to accurately learn temporal feature mappings from data. We further introduce a multi-stage, multi-expert architecture that assigns specialized predictors to different noise-level stages, enabling more precise and robust feature forecasting. Extensive experiments show our method achieves significant acceleration while maintaining high-fidelity generation. Experiments demonstrate 5.00x acceleration on FLUX.1-dev with minimal quality degradation (1.0% drop), 6.25x speedup on Qwen-Image with a 20.2% quality improvement over the previous SOTA (TaylorSeer), and 5.00x acceleration on HunyuanVideo with a 24.7% PSNR improvement over TaylorSeer. State-of-the-art performance on both text-to-image and text-to-video synthesis validates the effectiveness and generalization capability of our training-based framework across different models. Our code is included in the supplementary materials and will be released on GitHub.
Generalizable and Interpretable RF Fingerprinting with Shapelet-Enhanced Large Language Models
Feb 03, 2026Deep neural networks (DNNs) have achieved remarkable success in radio frequency (RF) fingerprinting for wireless device authentication. However, their practical deployment faces two major limitations: domain shift, where models trained in one environment struggle to generalize to others, and the black-box nature of DNNs, which limits interpretability. To address these issues, we propose a novel framework that integrates a group of variable-length two-dimensional (2D) shapelets with a pre-trained large language model (LLM) to achieve efficient, interpretable, and generalizable RF fingerprinting. The 2D shapelets explicitly capture diverse local temporal patterns across the in-phase and quadrature (I/Q) components, providing compact and interpretable representations. Complementarily, the pre-trained LLM captures more long-range dependencies and global contextual information, enabling strong generalization with minimal training overhead. Moreover, our framework also supports prototype generation for few-shot inference, enhancing cross-domain performance without additional retraining. To evaluate the effectiveness of our proposed method, we conduct extensive experiments on six datasets across various protocols and domains. The results show that our method achieves superior standard and few-shot performance across both source and unseen domains.
From PowerPoint UI Sketches to Web-Based Applications: Pattern-Driven Code Generation for GIS Dashboard Development Using Knowledge-Augmented LLMs, Context-Aware Visual Prompting, and the React Framework
Feb 12, 2025



Developing web-based GIS applications, commonly known as CyberGIS dashboards, for querying and visualizing GIS data in environmental research often demands repetitive and resource-intensive efforts. While Generative AI offers automation potential for code generation, it struggles with complex scientific applications due to challenges in integrating domain knowledge, software engineering principles, and UI design best practices. This paper introduces a knowledge-augmented code generation framework that retrieves software engineering best practices, domain expertise, and advanced technology stacks from a specialized knowledge base to enhance Generative Pre-trained Transformers (GPT) for front-end development. The framework automates the creation of GIS-based web applications (e.g., dashboards, interfaces) from user-defined UI wireframes sketched in tools like PowerPoint or Adobe Illustrator. A novel Context-Aware Visual Prompting method, implemented in Python, extracts layouts and interface features from these wireframes to guide code generation. Our approach leverages Large Language Models (LLMs) to generate front-end code by integrating structured reasoning, software engineering principles, and domain knowledge, drawing inspiration from Chain-of-Thought (CoT) prompting and Retrieval-Augmented Generation (RAG). A case study demonstrates the framework's capability to generate a modular, maintainable web platform hosting multiple dashboards for visualizing environmental and energy data (e.g., time-series, shapefiles, rasters) from user-sketched wireframes. By employing a knowledge-driven approach, the framework produces scalable, industry-standard front-end code using design patterns such as Model-View-ViewModel (MVVM) and frameworks like React. This significantly reduces manual effort in design and coding, pioneering an automated and efficient method for developing smart city software.
Explainable AI for Multivariate Time Series Pattern Exploration: Latent Space Visual Analytics with Temporal Fusion Transformer and Variational Autoencoders in Power Grid Event Diagnosis
Dec 24, 2024Detecting and analyzing complex patterns in multivariate time-series data is crucial for decision-making in urban and environmental system operations. However, challenges arise from the high dimensionality, intricate complexity, and interconnected nature of complex patterns, which hinder the understanding of their underlying physical processes. Existing AI methods often face limitations in interpretability, computational efficiency, and scalability, reducing their applicability in real-world scenarios. This paper proposes a novel visual analytics framework that integrates two generative AI models, Temporal Fusion Transformer (TFT) and Variational Autoencoders (VAEs), to reduce complex patterns into lower-dimensional latent spaces and visualize them in 2D using dimensionality reduction techniques such as PCA, t-SNE, and UMAP with DBSCAN. These visualizations, presented through coordinated and interactive views and tailored glyphs, enable intuitive exploration of complex multivariate temporal patterns, identifying patterns' similarities and uncover their potential correlations for a better interpretability of the AI outputs. The framework is demonstrated through a case study on power grid signal data, where it identifies multi-label grid event signatures, including faults and anomalies with diverse root causes. Additionally, novel metrics and visualizations are introduced to validate the models and evaluate the performance, efficiency, and consistency of latent maps generated by TFT and VAE under different configurations. These analyses provide actionable insights for model parameter tuning and reliability improvements. Comparative results highlight that TFT achieves shorter run times and superior scalability to diverse time-series data shapes compared to VAE. This work advances fault diagnosis in multivariate time series, fostering explainable AI to support critical system operations.
Automating Bibliometric Analysis with Sentence Transformers and Retrieval-Augmented Generation (RAG): A Pilot Study in Semantic and Contextual Search for Customized Literature Characterization for High-Impact Urban Research
Oct 08, 2024

Bibliometric analysis is essential for understanding research trends, scope, and impact in urban science, especially in high-impact journals, such Nature Portfolios. However, traditional methods, relying on keyword searches and basic NLP techniques, often fail to uncover valuable insights not explicitly stated in article titles or keywords. These approaches are unable to perform semantic searches and contextual understanding, limiting their effectiveness in classifying topics and characterizing studies. In this paper, we address these limitations by leveraging Generative AI models, specifically transformers and Retrieval-Augmented Generation (RAG), to automate and enhance bibliometric analysis. We developed a technical workflow that integrates a vector database, Sentence Transformers, a Gaussian Mixture Model (GMM), Retrieval Agent, and Large Language Models (LLMs) to enable contextual search, topic ranking, and characterization of research using customized prompt templates. A pilot study analyzing 223 urban science-related articles published in Nature Communications over the past decade highlights the effectiveness of our approach in generating insightful summary statistics on the quality, scope, and characteristics of papers in high-impact journals. This study introduces a new paradigm for enhancing bibliometric analysis and knowledge retrieval in urban research, positioning an AI agent as a powerful tool for advancing research evaluation and understanding.
GenAI-powered Multi-Agent Paradigm for Smart Urban Mobility: Opportunities and Challenges for Integrating Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) with Intelligent Transportation Systems
Aug 31, 2024

Leveraging recent advances in generative AI, multi-agent systems are increasingly being developed to enhance the functionality and efficiency of smart city applications. This paper explores the transformative potential of large language models (LLMs) and emerging Retrieval-Augmented Generation (RAG) technologies in Intelligent Transportation Systems (ITS), paving the way for innovative solutions to address critical challenges in urban mobility. We begin by providing a comprehensive overview of the current state-of-the-art in mobility data, ITS, and Connected Vehicles (CV) applications. Building on this review, we discuss the rationale behind RAG and examine the opportunities for integrating these Generative AI (GenAI) technologies into the smart mobility sector. We propose a conceptual framework aimed at developing multi-agent systems capable of intelligently and conversationally delivering smart mobility services to urban commuters, transportation operators, and decision-makers. Our approach seeks to foster an autonomous and intelligent approach that (a) promotes science-based advisory to reduce traffic congestion, accidents, and carbon emissions at multiple scales, (b) facilitates public education and engagement in participatory mobility management, and (c) automates specialized transportation management tasks and the development of critical ITS platforms, such as data analytics and interpretation, knowledge representation, and traffic simulations. By integrating LLM and RAG, our approach seeks to overcome the limitations of traditional rule-based multi-agent systems, which rely on fixed knowledge bases and limited reasoning capabilities. This integration paves the way for a more scalable, intuitive, and automated multi-agent paradigm, driving advancements in ITS and urban mobility.
Towards Next-Generation Urban Decision Support Systems through AI-Powered Generation of Scientific Ontology using Large Language Models -- A Case in Optimizing Intermodal Freight Transportation
May 29, 2024The incorporation of Artificial Intelligence (AI) models into various optimization systems is on the rise. Yet, addressing complex urban and environmental management problems normally requires in-depth domain science and informatics expertise. This expertise is essential for deriving data and simulation-driven for informed decision support. In this context, we investigate the potential of leveraging the pre-trained Large Language Models (LLMs). By adopting ChatGPT API as the reasoning core, we outline an integrated workflow that encompasses natural language processing, methontology-based prompt tuning, and transformers. This workflow automates the creation of scenario-based ontology using existing research articles and technical manuals of urban datasets and simulations. The outcomes of our methodology are knowledge graphs in widely adopted ontology languages (e.g., OWL, RDF, SPARQL). These facilitate the development of urban decision support systems by enhancing the data and metadata modeling, the integration of complex datasets, the coupling of multi-domain simulation models, and the formulation of decision-making metrics and workflow. The feasibility of our methodology is evaluated through a comparative analysis that juxtaposes our AI-generated ontology with the well-known Pizza Ontology employed in tutorials for popular ontology software (e.g., prot\'eg\'e). We close with a real-world case study of optimizing the complex urban system of multi-modal freight transportation by generating anthologies of various domain data and simulations to support informed decision-making.
Leveraging Generative AI for Smart City Digital Twins: A Survey on the Autonomous Generation of Data, Scenarios, 3D City Models, and Urban Designs
May 29, 2024The digital transformation of modern cities by integrating advanced information, communication, and computing technologies has marked the epoch of data-driven smart city applications for efficient and sustainable urban management. Despite their effectiveness, these applications often rely on massive amounts of high-dimensional and multi-domain data for monitoring and characterizing different urban sub-systems, presenting challenges in application areas that are limited by data quality and availability, as well as costly efforts for generating urban scenarios and design alternatives. As an emerging research area in deep learning, Generative Artificial Intelligence (AI) models have demonstrated their unique values in data and code generation. This survey paper aims to explore the innovative integration of generative AI techniques and urban digital twins to address challenges in the realm of smart cities in various urban sectors, such as transportation and mobility management, energy system operations, building and infrastructure management, and urban design. The survey starts with the introduction of popular generative AI models with their application areas, followed by a structured review of the existing urban science applications that leverage the autonomous capability of the generative AI techniques to facilitate (a) data augmentation for promoting urban monitoring and predictive analytics, (b) synthetic data and scenario generation, (c) automated 3D city modeling, and (d) generative urban design and optimization. Based on the review, this survey discusses potential opportunities and technical strategies that integrate generative AI models into the next-generation urban digital twins for more reliable, scalable, and automated management of smart cities.
Efficient Dynamic Graph Representation Learning at Scale
Dec 14, 2021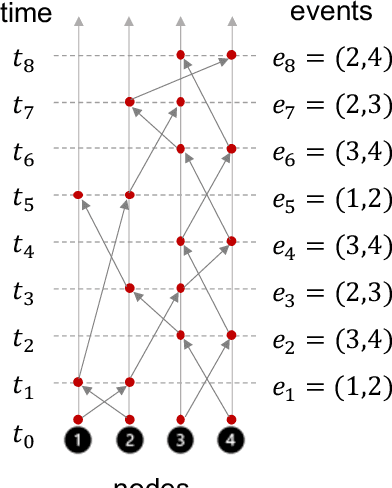
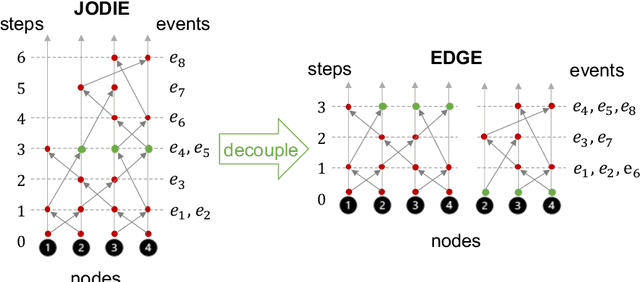
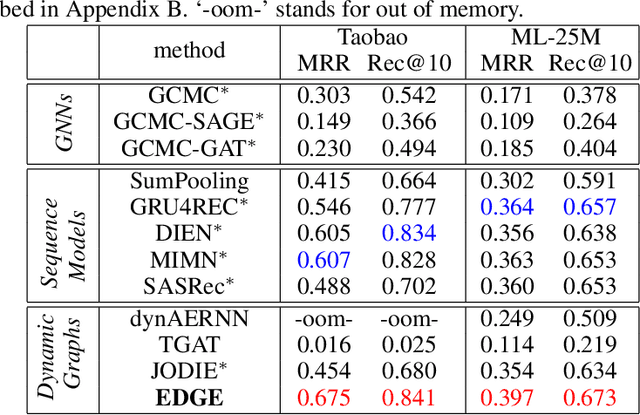
Dynamic graphs with ordered sequences of events between nodes are prevalent in real-world industrial applications such as e-commerce and social platforms. However, representation learning for dynamic graphs has posed great computational challenges due to the time and structure dependency and irregular nature of the data, preventing such models from being deployed to real-world applications. To tackle this challenge, we propose an efficient algorithm, Efficient Dynamic Graph lEarning (EDGE), which selectively expresses certain temporal dependency via training loss to improve the parallelism in computations. We show that EDGE can scale to dynamic graphs with millions of nodes and hundreds of millions of temporal events and achieve new state-of-the-art (SOTA) performance.
On the Necessity and Effectiveness of Learning the Prior of Variational Auto-Encoder
May 31, 2019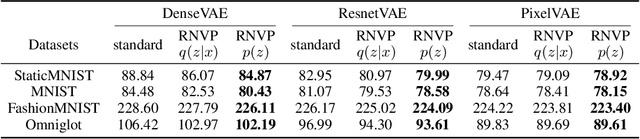


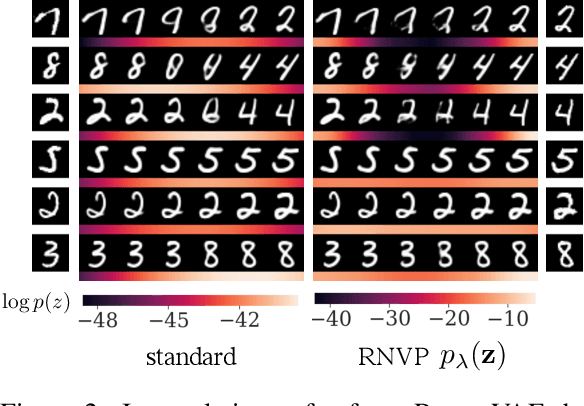
Using powerful posterior distributions is a popular approach to achieving better variational inference. However, recent works showed that the aggregated posterior may fail to match unit Gaussian prior, thus learning the prior becomes an alternative way to improve the lower-bound. In this paper, for the first time in the literature, we prove the necessity and effectiveness of learning the prior when aggregated posterior does not match unit Gaussian prior, analyze why this situation may happen, and propose a hypothesis that learning the prior may improve reconstruction loss, all of which are supported by our extensive experiment results. We show that using learned Real NVP prior and just one latent variable in VAE, we can achieve test NLL comparable to very deep state-of-the-art hierarchical VAE, outperforming many previous works with complex hierarchical VAE architectures.