 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAGA: Terrain-aware Active Gaze Learning for Generalizable Agile Humanoid Locomotion
Jun 04, 2026Agile humanoid locomotion across diverse challenging terrain demands both wide perceptual coverage and precise local geometry understanding. Motivated by the way humans selectively look at relevant terrain during locomotion, we introduce TAGA, a Terrain-aware Active Gaze learning framework for Attention-based humanoid control. By fusing vision, proprioception, and motion commands, our framework guides the model to learn anticipatory cues and actively attend to specific areas of the height scan, selectively using these informative regions for the downstream network. This adaptively increases the information density of observations under tight onboard computational constraints, thus enabling fine-grained perceptive locomotion over larger-scale terrains. We find that such gaze behaviors can naturally emerge through reinforcement learning alone, without requiring additional supervision or explicit guidance, significantly improve training efficiency. As a result, the trained policy demonstrates robust and generalizable locomotion in simulation and on hardware, including reliable terrain-aware foothold selection, elevated-platform traversal, competitive sparse-foothold traversal, and the largest reported real-world gap traversal distance of 1.2m among perceptive humanoid locomotion systems, while maintaining stability under severe perceptual disturbances and environmental interference.
Efficient Retrieval Scaling with Hierarchical Indexing for Large Scale Recommendation
Apr 14, 2026The increase in data volume, computational resources, and model parameters during training has led to the development of numerous large-scale industrial retrieval models for recommendation tasks. However, effectively and efficiently deploying these large-scale foundational retrieval models remains a critical challenge that has not been fully addressed. Common quick-win solutions for deploying these massive models include relying on offline computations (such as cached user dictionaries) or distilling large models into smaller ones. Yet, both approaches fall short of fully leveraging the representational and inference capabilities of foundational models. In this paper, we explore whether it is possible to learn a hierarchical organization over the memory of foundational retrieval models. Such a hierarchical structure would enable more efficient search by reducing retrieval costs while preserving exactness. To achieve this, we propose jointly learning a hierarchical index using cross-attention and residual quantization for large-scale retrieval models. We also present its real-world deployment at Meta, supporting daily advertisement recommendations for billions of Facebook and Instagram users. Interestingly, we discovered that the intermediate nodes in the learned index correspond to a small set of high-quality data. Fine-tuning the model on this set further improves inference performance, and concretize the concept of "test-time training" within the recommendation system domain. We demonstrate these findings using both internal and public datasets with strong baseline comparisons and hope they contribute to the community's efforts in developing the next generation of foundational retrieval models.
Hierarchical Structured Neural Network for Retrieval
Aug 13, 2024



Embedding Based Retrieval (EBR) is a crucial component of the retrieval stage in (Ads) Recommendation System that utilizes Two Tower or Siamese Networks to learn embeddings for both users and items (ads). It then employs an Approximate Nearest Neighbor Search (ANN) to efficiently retrieve the most relevant ads for a specific user. Despite the recent rise to popularity in the industry, they have a couple of limitations. Firstly, Two Tower model architecture uses a single dot product interaction which despite their efficiency fail to capture the data distribution in practice. Secondly, the centroid representation and cluster assignment, which are components of ANN, occur after the training process has been completed. As a result, they do not take into account the optimization criteria used for retrieval model. In this paper, we present Hierarchical Structured Neural Network (HSNN), a deployed jointly optimized hierarchical clustering and neural network model that can take advantage of sophisticated interactions and model architectures that are more common in the ranking stages while maintaining a sub-linear inference cost. We achieve 6.5% improvement in offline evaluation and also demonstrate 1.22% online gains through A/B experiments. HSNN has been successfully deployed into the Ads Recommendation system and is currently handling major portion of the traffic. The paper shares our experience in developing this system, dealing with challenges like freshness, volatility, cold start recommendations, cluster collapse and lessons deploying the model in a large scale retrieval production system.
BusTr: Predicting Bus Travel Times from Real-Time Traffic
Jul 02, 2020
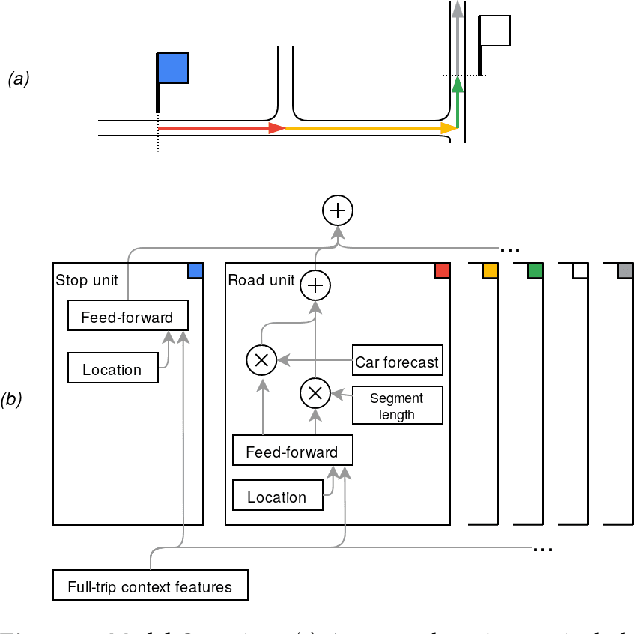

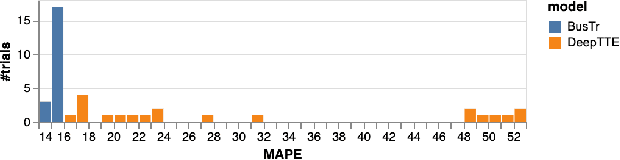
We present BusTr, a machine-learned model for translating road traffic forecasts into predictions of bus delays, used by Google Maps to serve the majority of the world's public transit systems where no official real-time bus tracking is provided. We demonstrate that our neural sequence model improves over DeepTTE, the state-of-the-art baseline, both in performance (-30% MAPE) and training stability. We also demonstrate significant generalization gains over simpler models, evaluated on longitudinal data to cope with a constantly evolving world.