 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Model Design on Recommender Systems
Nov 12, 2024The increasing popularity of deep learning models has created new opportunities for developing AI-based recommender systems. Designing recommender systems using deep neural networks requires careful architecture design, and further optimization demands extensive co-design efforts on jointly optimizing model architecture and hardware. Design automation, such as Automated Machine Learning (AutoML), is necessary to fully exploit the potential of recommender model design, including model choices and model-hardware co-design strategies. We introduce a novel paradigm that utilizes weight sharing to explore abundant solution spaces. Our paradigm creates a large supernet to search for optimal architectures and co-design strategies to address the challenges of data multi-modality and heterogeneity in the recommendation domain. From a model perspective, the supernet includes a variety of operators, dense connectivity, and dimension search options. From a co-design perspective, it encompasses versatile Processing-In-Memory (PIM) configurations to produce hardware-efficient models. Our solution space's scale, heterogeneity, and complexity pose several challenges, which we address by proposing various techniques for training and evaluating the supernet. Our crafted models show promising results on three Click-Through Rates (CTR) prediction benchmarks, outperforming both manually designed and AutoML-crafted models with state-of-the-art performance when focusing solely on architecture search. From a co-design perspective, we achieve 2x FLOPs efficiency, 1.8x energy efficiency, and 1.5x performance improvements in recommender models.
* Accepted in ACM Transactions on Recommender Systems. arXiv admin note: substantial text overlap with arXiv:2207.07187
Can Dense Connectivity Benefit Outlier Detection? An Odyssey with NAS
Jun 04, 2024



Recent advances in Out-of-Distribution (OOD) Detection is the driving force behind safe and reliable deployment of Convolutional Neural Networks (CNNs) in real world applications. However, existing studies focus on OOD detection through confidence score and deep generative model-based methods, without considering the impact of DNN structures, especially dense connectivity in architecture fabrications. In addition, existing outlier detection approaches exhibit high variance in generalization performance, lacking stability and confidence in evaluating and ranking different outlier detectors. In this work, we propose a novel paradigm, Dense Connectivity Search of Outlier Detector (DCSOD), that automatically explore the dense connectivity of CNN architectures on near-OOD detection task using Neural Architecture Search (NAS). We introduce a hierarchical search space containing versatile convolution operators and dense connectivity, allowing a flexible exploration of CNN architectures with diverse connectivity patterns. To improve the quality of evaluation on OOD detection during search, we propose evolving distillation based on our multi-view feature learning explanation. Evolving distillation stabilizes training for OOD detection evaluation, thus improves the quality of search. We thoroughly examine DCSOD on CIFAR benchmarks under OOD detection protocol. Experimental results show that DCSOD achieve remarkable performance over widely used architectures and previous NAS baselines. Notably, DCSOD achieves state-of-the-art (SOTA) performance on CIFAR benchmark, with AUROC improvement of $\sim$1.0%.
CSCO: Connectivity Search of Convolutional Operators
Apr 26, 2024



Exploring dense connectivity of convolutional operators establishes critical "synapses" to communicate feature vectors from different levels and enriches the set of transformations on Computer Vision applications. Yet, even with heavy-machinery approaches such as Neural Architecture Search (NAS), discovering effective connectivity patterns requires tremendous efforts due to either constrained connectivity design space or a sub-optimal exploration process induced by an unconstrained search space. In this paper, we propose CSCO, a novel paradigm that fabricates effective connectivity of convolutional operators with minimal utilization of existing design motifs and further utilizes the discovered wiring to construct high-performing ConvNets. CSCO guides the exploration via a neural predictor as a surrogate of the ground-truth performance. We introduce Graph Isomorphism as data augmentation to improve sample efficiency and propose a Metropolis-Hastings Evolutionary Search (MH-ES) to evade locally optimal architectures and advance search quality. Results on ImageNet show ~0.6% performance improvement over hand-crafted and NAS-crafted dense connectivity. Our code is publicly available.
Peeking Behind the Curtains of Residual Learning
Feb 13, 2024The utilization of residual learning has become widespread in deep and scalable neural nets. However, the fundamental principles that contribute to the success of residual learning remain elusive, thus hindering effective training of plain nets with depth scalability. In this paper, we peek behind the curtains of residual learning by uncovering the "dissipating inputs" phenomenon that leads to convergence failure in plain neural nets: the input is gradually compromised through plain layers due to non-linearities, resulting in challenges of learning feature representations. We theoretically demonstrate how plain neural nets degenerate the input to random noise and emphasize the significance of a residual connection that maintains a better lower bound of surviving neurons as a solution. With our theoretical discoveries, we propose "The Plain Neural Net Hypothesis" (PNNH) that identifies the internal path across non-linear layers as the most critical part in residual learning, and establishes a paradigm to support the training of deep plain neural nets devoid of residual connections. We thoroughly evaluate PNNH-enabled CNN architectures and Transformers on popular vision benchmarks, showing on-par accuracy, up to 0.3% higher training throughput, and 2x better parameter efficiency compared to ResNets and vision Transformers.
DistDNAS: Search Efficient Feature Interactions within 2 Hours
Nov 01, 2023



Search efficiency and serving efficiency are two major axes in building feature interactions and expediting the model development process in recommender systems. On large-scale benchmarks, searching for the optimal feature interaction design requires extensive cost due to the sequential workflow on the large volume of data. In addition, fusing interactions of various sources, orders, and mathematical operations introduces potential conflicts and additional redundancy toward recommender models, leading to sub-optimal trade-offs in performance and serving cost. In this paper, we present DistDNAS as a neat solution to brew swift and efficient feature interaction design. DistDNAS proposes a supernet to incorporate interaction modules of varying orders and types as a search space. To optimize search efficiency, DistDNAS distributes the search and aggregates the choice of optimal interaction modules on varying data dates, achieving over 25x speed-up and reducing search cost from 2 days to 2 hours. To optimize serving efficiency, DistDNAS introduces a differentiable cost-aware loss to penalize the selection of redundant interaction modules, enhancing the efficiency of discovered feature interactions in serving. We extensively evaluate the best models crafted by DistDNAS on a 1TB Criteo Terabyte dataset. Experimental evaluations demonstrate 0.001 AUC improvement and 60% FLOPs saving over current state-of-the-art CTR models.
Farthest Greedy Path Sampling for Two-shot Recommender Search
Oct 31, 2023Weight-sharing Neural Architecture Search (WS-NAS) provides an efficient mechanism for developing end-to-end deep recommender models. However, in complex search spaces, distinguishing between superior and inferior architectures (or paths) is challenging. This challenge is compounded by the limited coverage of the supernet and the co-adaptation of subnet weights, which restricts the exploration and exploitation capabilities inherent to weight-sharing mechanisms. To address these challenges, we introduce Farthest Greedy Path Sampling (FGPS), a new path sampling strategy that balances path quality and diversity. FGPS enhances path diversity to facilitate more comprehensive supernet exploration, while emphasizing path quality to ensure the effective identification and utilization of promising architectures. By incorporating FGPS into a Two-shot NAS (TS-NAS) framework, we derive high-performance architectures. Evaluations on three Click-Through Rate (CTR) prediction benchmarks demonstrate that our approach consistently achieves superior results, outperforming both manually designed and most NAS-based models.
LISSNAS: Locality-based Iterative Search Space Shrinkage for Neural Architecture Search
Jul 06, 2023



Search spaces hallmark the advancement of Neural Architecture Search (NAS). Large and complex search spaces with versatile building operators and structures provide more opportunities to brew promising architectures, yet pose severe challenges on efficient exploration and exploitation. Subsequently, several search space shrinkage methods optimize by selecting a single sub-region that contains some well-performing networks. Small performance and efficiency gains are observed with these methods but such techniques leave room for significantly improved search performance and are ineffective at retaining architectural diversity. We propose LISSNAS, an automated algorithm that shrinks a large space into a diverse, small search space with SOTA search performance. Our approach leverages locality, the relationship between structural and performance similarity, to efficiently extract many pockets of well-performing networks. We showcase our method on an array of search spaces spanning various sizes and datasets. We accentuate the effectiveness of our shrunk spaces when used in one-shot search by achieving the best Top-1 accuracy in two different search spaces. Our method achieves a SOTA Top-1 accuracy of 77.6\% in ImageNet under mobile constraints, best-in-class Kendal-Tau, architectural diversity, and search space size.
PIDS: Joint Point Interaction-Dimension Search for 3D Point Cloud
Nov 28, 2022The interaction and dimension of points are two important axes in designing point operators to serve hierarchical 3D models. Yet, these two axes are heterogeneous and challenging to fully explore. Existing works craft point operator under a single axis and reuse the crafted operator in all parts of 3D models. This overlooks the opportunity to better combine point interactions and dimensions by exploiting varying geometry/density of 3D point clouds. In this work, we establish PIDS, a novel paradigm to jointly explore point interactions and point dimensions to serve semantic segmentation on point cloud data. We establish a large search space to jointly consider versatile point interactions and point dimensions. This supports point operators with various geometry/density considerations. The enlarged search space with heterogeneous search components calls for a better ranking of candidate models. To achieve this, we improve the search space exploration by leveraging predictor-based Neural Architecture Search (NAS), and enhance the quality of prediction by assigning unique encoding to heterogeneous search components based on their priors. We thoroughly evaluate the networks crafted by PIDS on two semantic segmentation benchmarks, showing ~1% mIOU improvement on SemanticKITTI and S3DIS over state-of-the-art 3D models.
NASRec: Weight Sharing Neural Architecture Search for Recommender Systems
Jul 14, 2022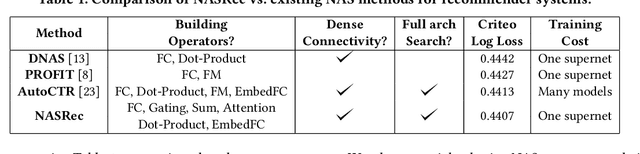
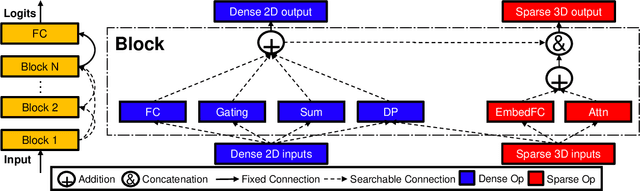
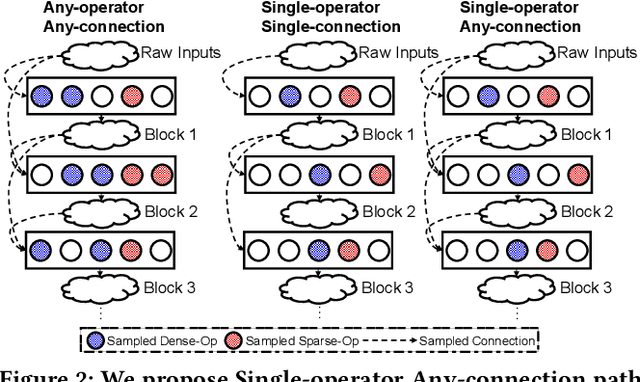

The rise of deep neural networks provides an important driver in optimizing recommender systems. However, the success of recommender systems lies in delicate architecture fabrication, and thus calls for Neural Architecture Search (NAS) to further improve its modeling. We propose NASRec, a paradigm that trains a single supernet and efficiently produces abundant models/sub-architectures by weight sharing. To overcome the data multi-modality and architecture heterogeneity challenges in recommendation domain, NASRec establishes a large supernet (i.e., search space) to search the full architectures, with the supernet incorporating versatile operator choices and dense connectivity minimizing human prior for flexibility. The scale and heterogeneity in NASRec impose challenges in search, such as training inefficiency, operator-imbalance, and degraded rank correlation. We tackle these challenges by proposing single-operator any-connection sampling, operator-balancing interaction modules, and post-training fine-tuning. Our results on three Click-Through Rates (CTR) prediction benchmarks show that NASRec can outperform both manually designed models and existing NAS methods, achieving state-of-the-art performance.
Towards Collaborative Intelligence: Routability Estimation based on Decentralized Private Data
Mar 30, 2022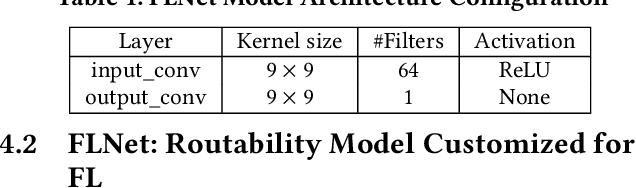
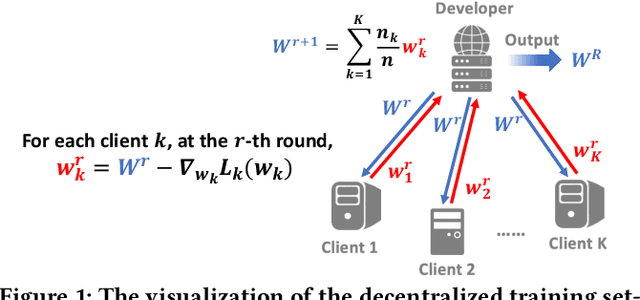
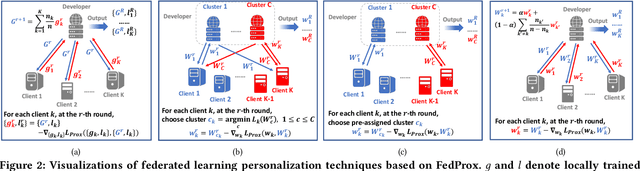
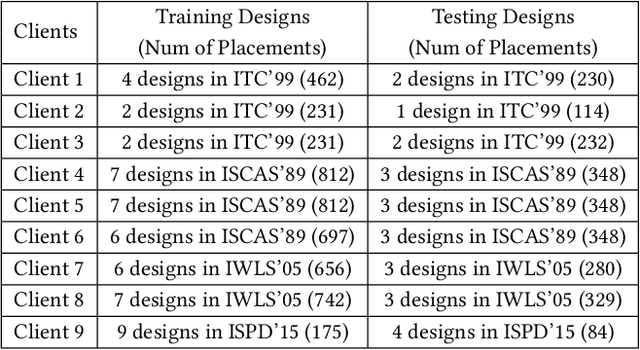
Applying machine learning (ML) in design flow is a popular trend in EDA with various applications from design quality predictions to optimizations. Despite its promise, which has been demonstrated in both academic researches and industrial tools, its effectiveness largely hinges on the availability of a large amount of high-quality training data. In reality, EDA developers have very limited access to the latest design data, which is owned by design companies and mostly confidential. Although one can commission ML model training to a design company, the data of a single company might be still inadequate or biased, especially for small companies. Such data availability problem is becoming the limiting constraint on future growth of ML for chip design. In this work, we propose an Federated-Learning based approach for well-studied ML applications in EDA. Our approach allows an ML model to be collaboratively trained with data from multiple clients but without explicit access to the data for respecting their data privacy. To further strengthen the results, we co-design a customized ML model FLNet and its personalization under the decentralized training scenario. Experiments on a comprehensive dataset show that collaborative training improves accuracy by 11% compared with individual local models, and our customized model FLNet significantly outperforms the best of previous routability estimators in this collaborative training flow.