 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffSpectra: Molecular Structure Elucidation from Spectra using Diffusion Models
Jul 09, 2025Molecular structure elucidation from spectra is a foundational problem in chemistry, with profound implications for compound identification, synthesis, and drug development. Traditional methods rely heavily on expert interpretation and lack scalability. Pioneering machine learning methods have introduced retrieval-based strategies, but their reliance on finite libraries limits generalization to novel molecules. Generative models offer a promising alternative, yet most adopt autoregressive SMILES-based architectures that overlook 3D geometry and struggle to integrate diverse spectral modalities. In this work, we present DiffSpectra, a generative framework that directly infers both 2D and 3D molecular structures from multi-modal spectral data using diffusion models. DiffSpectra formulates structure elucidation as a conditional generation process. Its denoising network is parameterized by Diffusion Molecule Transformer, an SE(3)-equivariant architecture that integrates topological and geometric information. Conditioning is provided by SpecFormer, a transformer-based spectral encoder that captures intra- and inter-spectral dependencies from multi-modal spectra. Extensive experiments demonstrate that DiffSpectra achieves high accuracy in structure elucidation, recovering exact structures with 16.01% top-1 accuracy and 96.86% top-20 accuracy through sampling. The model benefits significantly from 3D geometric modeling, SpecFormer pre-training, and multi-modal conditioning. These results highlight the effectiveness of spectrum-conditioned diffusion modeling in addressing the challenge of molecular structure elucidation. To our knowledge, DiffSpectra is the first framework to unify multi-modal spectral reasoning and joint 2D/3D generative modeling for de novo molecular structure elucidation.
EC-Flow: Enabling Versatile Robotic Manipulation from Action-Unlabeled Videos via Embodiment-Centric Flow
Jul 08, 2025



Current language-guided robotic manipulation systems often require low-level action-labeled datasets for imitation learning. While object-centric flow prediction methods mitigate this issue, they remain limited to scenarios involving rigid objects with clear displacement and minimal occlusion. In this work, we present Embodiment-Centric Flow (EC-Flow), a framework that directly learns manipulation from action-unlabeled videos by predicting embodiment-centric flow. Our key insight is that incorporating the embodiment's inherent kinematics significantly enhances generalization to versatile manipulation scenarios, including deformable object handling, occlusions, and non-object-displacement tasks. To connect the EC-Flow with language instructions and object interactions, we further introduce a goal-alignment module by jointly optimizing movement consistency and goal-image prediction. Moreover, translating EC-Flow to executable robot actions only requires a standard robot URDF (Unified Robot Description Format) file to specify kinematic constraints across joints, which makes it easy to use in practice. We validate EC-Flow on both simulation (Meta-World) and real-world tasks, demonstrating its state-of-the-art performance in occluded object handling (62% improvement), deformable object manipulation (45% improvement), and non-object-displacement tasks (80% improvement) than prior state-of-the-art object-centric flow methods. For more information, see our project website at https://ec-flow1.github.io .
Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing
Jun 11, 2025



As textual reasoning with large language models (LLMs) has advanced significantly, there has been growing interest in enhancing the multimodal reasoning capabilities of large vision-language models (LVLMs). However, existing methods primarily approach multimodal reasoning in a straightforward, text-centric manner, where both reasoning and answer derivation are conducted purely through text, with the only difference being the presence of multimodal input. As a result, these methods often encounter fundamental limitations in spatial reasoning tasks that demand precise geometric understanding and continuous spatial tracking-capabilities that humans achieve through mental visualization and manipulation. To address the limitations, we propose drawing to reason in space, a novel paradigm that enables LVLMs to reason through elementary drawing operations in the visual space. By equipping models with basic drawing operations, including annotating bounding boxes and drawing auxiliary lines, we empower them to express and analyze spatial relationships through direct visual manipulation, meanwhile avoiding the performance ceiling imposed by specialized perception tools in previous tool-integrated reasoning approaches. To cultivate this capability, we develop a three-stage training framework: cold-start training with synthetic data to establish basic drawing abilities, reflective rejection sampling to enhance self-reflection behaviors, and reinforcement learning to directly optimize for target rewards. Extensive experiments demonstrate that our model, named VILASR, consistently outperforms existing methods across diverse spatial reasoning benchmarks, involving maze navigation, static spatial reasoning, video-based reasoning, and multi-view-based reasoning tasks, with an average improvement of 18.4%.
VersaVid-R1: A Versatile Video Understanding and Reasoning Model from Question Answering to Captioning Tasks
Jun 10, 2025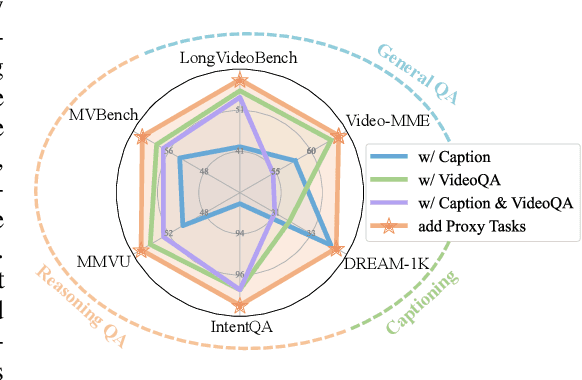

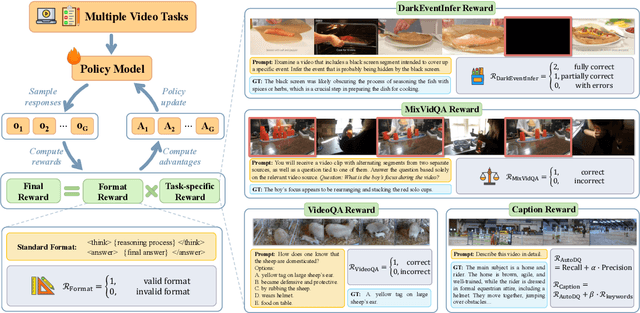

Recent advancements in multimodal large language models have successfully extended the Reason-Then-Respond paradigm to image-based reasoning, yet video-based reasoning remains an underdeveloped frontier, primarily due to the scarcity of high-quality reasoning-oriented data and effective training methodologies. To bridge this gap, we introduce DarkEventInfer and MixVidQA, two novel datasets specifically designed to stimulate the model's advanced video understanding and reasoning abilities. DarkEventinfer presents videos with masked event segments, requiring models to infer the obscured content based on contextual video cues. MixVidQA, on the other hand, presents interleaved video sequences composed of two distinct clips, challenging models to isolate and reason about one while disregarding the other. Leveraging these carefully curated training samples together with reinforcement learning guided by diverse reward functions, we develop VersaVid-R1, the first versatile video understanding and reasoning model under the Reason-Then-Respond paradigm capable of handling multiple-choice and open-ended question answering, as well as video captioning tasks. Extensive experiments demonstrate that VersaVid-R1 significantly outperforms existing models across a broad spectrum of benchmarks, covering video general understanding, cognitive reasoning, and captioning tasks.
BridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models
Jun 09, 2025Recently, leveraging pre-trained vision-language models (VLMs) for building vision-language-action (VLA) models has emerged as a promising approach to effective robot manipulation learning. However, only few methods incorporate 3D signals into VLMs for action prediction, and they do not fully leverage the spatial structure inherent in 3D data, leading to low sample efficiency. In this paper, we introduce BridgeVLA, a novel 3D VLA model that (1) projects 3D inputs to multiple 2D images, ensuring input alignment with the VLM backbone, and (2) utilizes 2D heatmaps for action prediction, unifying the input and output spaces within a consistent 2D image space. In addition, we propose a scalable pre-training method that equips the VLM backbone with the capability to predict 2D heatmaps before downstream policy learning. Extensive experiments show the proposed method is able to learn 3D manipulation efficiently and effectively. BridgeVLA outperforms state-of-the-art baseline methods across three simulation benchmarks. In RLBench, it improves the average success rate from 81.4% to 88.2%. In COLOSSEUM, it demonstrates significantly better performance in challenging generalization settings, boosting the average success rate from 56.7% to 64.0%. In GemBench, it surpasses all the comparing baseline methods in terms of average success rate. In real-robot experiments, BridgeVLA outperforms a state-of-the-art baseline method by 32% on average. It generalizes robustly in multiple out-of-distribution settings, including visual disturbances and unseen instructions. Remarkably, it is able to achieve a success rate of 96.8% on 10+ tasks with only 3 trajectories per task, highlighting its extraordinary sample efficiency. Project Website:https://bridgevla.github.io/
Divide-Then-Align: Honest Alignment based on the Knowledge Boundary of RAG
May 27, 2025



Large language models (LLMs) augmented with retrieval systems have significantly advanced natural language processing tasks by integrating external knowledge sources, enabling more accurate and contextually rich responses. To improve the robustness of such systems against noisy retrievals, Retrieval-Augmented Fine-Tuning (RAFT) has emerged as a widely adopted method. However, RAFT conditions models to generate answers even in the absence of reliable knowledge. This behavior undermines their reliability in high-stakes domains, where acknowledging uncertainty is critical. To address this issue, we propose Divide-Then-Align (DTA), a post-training approach designed to endow RAG systems with the ability to respond with "I don't know" when the query is out of the knowledge boundary of both the retrieved passages and the model's internal knowledge. DTA divides data samples into four knowledge quadrants and constructs tailored preference data for each quadrant, resulting in a curated dataset for Direct Preference Optimization (DPO). Experimental results on three benchmark datasets demonstrate that DTA effectively balances accuracy with appropriate abstention, enhancing the reliability and trustworthiness of retrieval-augmented systems.
Reinforcing General Reasoning without Verifiers
May 27, 2025The recent paradigm shift towards training large language models (LLMs) using DeepSeek-R1-Zero-style reinforcement learning (RL) on verifiable rewards has led to impressive advancements in code and mathematical reasoning. However, this methodology is limited to tasks where rule-based answer verification is possible and does not naturally extend to real-world domains such as chemistry, healthcare, engineering, law, biology, business, and economics. Current practical workarounds use an additional LLM as a model-based verifier; however, this introduces issues such as reliance on a strong verifier LLM, susceptibility to reward hacking, and the practical burden of maintaining the verifier model in memory during training. To address this and extend DeepSeek-R1-Zero-style training to general reasoning domains, we propose a verifier-free method (VeriFree) that bypasses answer verification and instead uses RL to directly maximize the probability of generating the reference answer. We compare VeriFree with verifier-based methods and demonstrate that, in addition to its significant practical benefits and reduced compute requirements, VeriFree matches and even surpasses verifier-based methods on extensive evaluations across MMLU-Pro, GPQA, SuperGPQA, and math-related benchmarks. Moreover, we provide insights into this method from multiple perspectives: as an elegant integration of training both the policy and implicit verifier in a unified model, and as a variational optimization approach. Code is available at https://github.com/sail-sg/VeriFree.
REACT: Representation Extraction And Controllable Tuning to Overcome Overfitting in LLM Knowledge Editing
May 25, 2025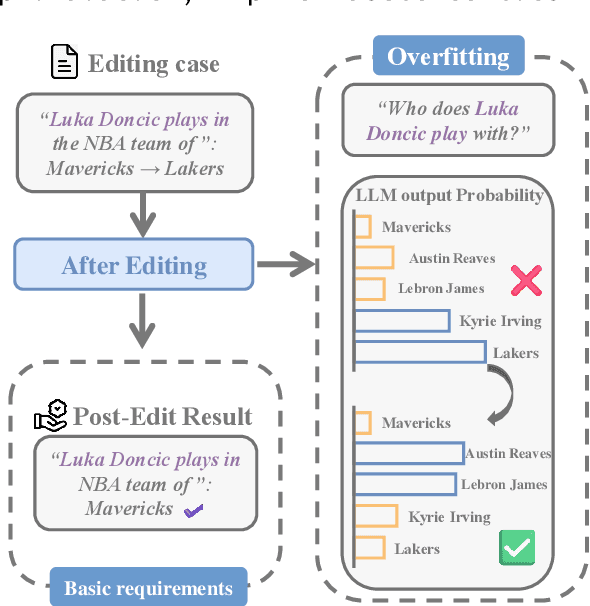
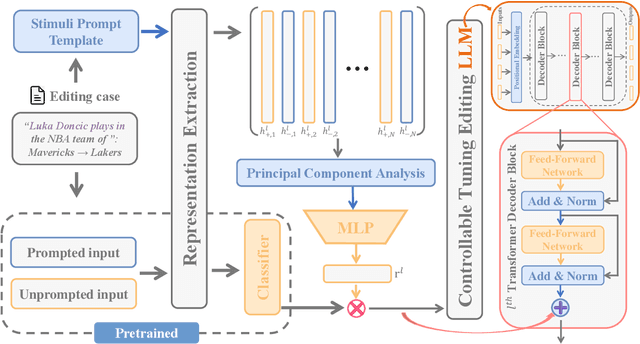
Large language model editing methods frequently suffer from overfitting, wherein factual updates can propagate beyond their intended scope, overemphasizing the edited target even when it's contextually inappropriate. To address this challenge, we introduce REACT (Representation Extraction And Controllable Tuning), a unified two-phase framework designed for precise and controllable knowledge editing. In the initial phase, we utilize tailored stimuli to extract latent factual representations and apply Principal Component Analysis with a simple learnbale linear transformation to compute a directional "belief shift" vector for each instance. In the second phase, we apply controllable perturbations to hidden states using the obtained vector with a magnitude scalar, gated by a pre-trained classifier that permits edits only when contextually necessary. Relevant experiments on EVOKE benchmarks demonstrate that REACT significantly reduces overfitting across nearly all evaluation metrics, and experiments on COUNTERFACT and MQuAKE shows that our method preserves balanced basic editing performance (reliability, locality, and generality) under diverse editing scenarios.
AuroRA: Breaking Low-Rank Bottleneck of LoRA with Nonlinear Mapping
May 24, 2025Low-Rank Adaptation (LoRA) is a widely adopted parameter-efficient fine-tuning (PEFT) method validated across NLP and CV domains. However, LoRA faces an inherent low-rank bottleneck: narrowing its performance gap with full finetuning requires increasing the rank of its parameter matrix, resulting in significant parameter overhead. Recent linear LoRA variants have attempted to enhance expressiveness by introducing additional linear mappings; however, their composition remains inherently linear and fails to fundamentally improve LoRA's representational capacity. To address this limitation, we propose AuroRA, which incorporates an Adaptive Nonlinear Layer (ANL) between two linear projectors to capture fixed and learnable nonlinearities. This combination forms an MLP-like structure with a compressed rank, enabling flexible and precise approximation of diverse target functions while theoretically guaranteeing lower approximation errors and bounded gradients. Extensive experiments on 22 datasets and 6 pretrained models demonstrate that AuroRA: (I) not only matches or surpasses full fine-tuning performance with only 6.18% ~ 25% of LoRA's parameters but also (II) outperforms state-of-the-art PEFT methods by up to 10.88% in both NLP and CV tasks, and (III) exhibits robust performance across various rank configurations.
Materials Generation in the Era of Artificial Intelligence: A Comprehensive Survey
May 22, 2025



Materials are the foundation of modern society, underpinning advancements in energy, electronics, healthcare, transportation, and infrastructure. The ability to discover and design new materials with tailored properties is critical to solving some of the most pressing global challenges. In recent years, the growing availability of high-quality materials data combined with rapid advances in Artificial Intelligence (AI) has opened new opportunities for accelerating materials discovery. Data-driven generative models provide a powerful tool for materials design by directly create novel materials that satisfy predefined property requirements. Despite the proliferation of related work, there remains a notable lack of up-to-date and systematic surveys in this area. To fill this gap, this paper provides a comprehensive overview of recent progress in AI-driven materials generation. We first organize various types of materials and illustrate multiple representations of crystalline materials. We then provide a detailed summary and taxonomy of current AI-driven materials generation approaches. Furthermore, we discuss the common evaluation metrics and summarize open-source codes and benchmark datasets. Finally, we conclude with potential future directions and challenges in this fast-growing field. The related sources can be found at https://github.com/ZhixunLEE/Awesome-AI-for-Materials-Generation.