 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Fusion of Large Atomic and Language Models to Accelerate Materials Discovery
Apr 26, 2026The discovery of novel materials is critical for global energy and quantum technology transitions. While deep learning has fundamentally reshaped this landscape, existing predictive or generative models typically operate in isolation, lacking the autonomous orchestration required to execute the full discovery process. Here we present ElementsClaw, an agentic framework for materials discovery that synergizes Large Atomic Models (LAMs) with Large Language Models (LLMs). In response to varied human requirements, ElementsClaw dynamically orchestrates a suite of LAM tools finetuned from our proposed model Elements for atomic-scale numerical computation, while leveraging LLMs for high-level semantic reasoning. This shift moves AI-driven materials science from isolated processes toward integrated and human interactive discovery. In the demanding domain of superconductors, our agentic system guides the experimental synthesis of four new superconductors, including Zr3ScRe8 with a transition temperature of 6.8 K and HfZrRe4 at 6.7 K. At scale, ElementsClaw screens more than 2.4 million stable crystals within only 28 GPU hours, identifying 68,000 high-confidence superconducting candidates and vastly expanding the known superconducting space. These results demonstrate how our agent accelerates materials discovery with high physical fidelity.
Privacy-Preserving Model Transcription with Differentially Private Synthetic Distillation
Jan 27, 2026While many deep learning models trained on private datasets have been deployed in various practical tasks, they may pose a privacy leakage risk as attackers could recover informative data or label knowledge from models. In this work, we present \emph{privacy-preserving model transcription}, a data-free model-to-model conversion solution to facilitate model deployment with a privacy guarantee. To this end, we propose a cooperative-competitive learning approach termed \emph{differentially private synthetic distillation} that learns to convert a pretrained model (teacher) into its privacy-preserving counterpart (student) via a trainable generator without access to private data. The learning collaborates with three players in a unified framework and performs alternate optimization: i)~the generator is learned to generate synthetic data, ii)~the teacher and student accept the synthetic data and compute differential private labels by flexible data or label noisy perturbation, and iii)~the student is updated with noisy labels and the generator is updated by taking the student as a discriminator for adversarial training. We theoretically prove that our approach can guarantee differential privacy and convergence. The transcribed student has good performance and privacy protection, while the resulting generator can generate private synthetic data for downstream tasks. Extensive experiments clearly demonstrate that our approach outperforms 26 state-of-the-arts.
DiffSpectra: Molecular Structure Elucidation from Spectra using Diffusion Models
Jul 09, 2025Molecular structure elucidation from spectra is a foundational problem in chemistry, with profound implications for compound identification, synthesis, and drug development. Traditional methods rely heavily on expert interpretation and lack scalability. Pioneering machine learning methods have introduced retrieval-based strategies, but their reliance on finite libraries limits generalization to novel molecules. Generative models offer a promising alternative, yet most adopt autoregressive SMILES-based architectures that overlook 3D geometry and struggle to integrate diverse spectral modalities. In this work, we present DiffSpectra, a generative framework that directly infers both 2D and 3D molecular structures from multi-modal spectral data using diffusion models. DiffSpectra formulates structure elucidation as a conditional generation process. Its denoising network is parameterized by Diffusion Molecule Transformer, an SE(3)-equivariant architecture that integrates topological and geometric information. Conditioning is provided by SpecFormer, a transformer-based spectral encoder that captures intra- and inter-spectral dependencies from multi-modal spectra. Extensive experiments demonstrate that DiffSpectra achieves high accuracy in structure elucidation, recovering exact structures with 16.01% top-1 accuracy and 96.86% top-20 accuracy through sampling. The model benefits significantly from 3D geometric modeling, SpecFormer pre-training, and multi-modal conditioning. These results highlight the effectiveness of spectrum-conditioned diffusion modeling in addressing the challenge of molecular structure elucidation. To our knowledge, DiffSpectra is the first framework to unify multi-modal spectral reasoning and joint 2D/3D generative modeling for de novo molecular structure elucidation.
Learning Privacy-Preserving Student Networks via Discriminative-Generative Distillation
Sep 04, 2024While deep models have proved successful in learning rich knowledge from massive well-annotated data, they may pose a privacy leakage risk in practical deployment. It is necessary to find an effective trade-off between high utility and strong privacy. In this work, we propose a discriminative-generative distillation approach to learn privacy-preserving deep models. Our key idea is taking models as bridge to distill knowledge from private data and then transfer it to learn a student network via two streams. First, discriminative stream trains a baseline classifier on private data and an ensemble of teachers on multiple disjoint private subsets, respectively. Then, generative stream takes the classifier as a fixed discriminator and trains a generator in a data-free manner. After that, the generator is used to generate massive synthetic data which are further applied to train a variational autoencoder (VAE). Among these synthetic data, a few of them are fed into the teacher ensemble to query labels via differentially private aggregation, while most of them are embedded to the trained VAE for reconstructing synthetic data. Finally, a semi-supervised student learning is performed to simultaneously handle two tasks: knowledge transfer from the teachers with distillation on few privately labeled synthetic data, and knowledge enhancement with tangent-normal adversarial regularization on many triples of reconstructed synthetic data. In this way, our approach can control query cost over private data and mitigate accuracy degradation in a unified manner, leading to a privacy-preserving student model. Extensive experiments and analysis clearly show the effectiveness of the proposed approach.
Learning Differentially Private Diffusion Models via Stochastic Adversarial Distillation
Aug 27, 2024



While the success of deep learning relies on large amounts of training datasets, data is often limited in privacy-sensitive domains. To address this challenge, generative model learning with differential privacy has emerged as a solution to train private generative models for desensitized data generation. However, the quality of the images generated by existing methods is limited due to the complexity of modeling data distribution. We build on the success of diffusion models and introduce DP-SAD, which trains a private diffusion model by a stochastic adversarial distillation method. Specifically, we first train a diffusion model as a teacher and then train a student by distillation, in which we achieve differential privacy by adding noise to the gradients from other models to the student. For better generation quality, we introduce a discriminator to distinguish whether an image is from the teacher or the student, which forms the adversarial training. Extensive experiments and analysis clearly demonstrate the effectiveness of our proposed method.
M3D: Dataset Condensation by Minimizing Maximum Mean Discrepancy
Jan 03, 2024Training state-of-the-art (SOTA) deep models often requires extensive data, resulting in substantial training and storage costs. To address these challenges, dataset condensation has been developed to learn a small synthetic set that preserves essential information from the original large-scale dataset. Nowadays, optimization-oriented methods have been the primary method in the field of dataset condensation for achieving SOTA results. However, the bi-level optimization process hinders the practical application of such methods to realistic and larger datasets. To enhance condensation efficiency, previous works proposed Distribution-Matching (DM) as an alternative, which significantly reduces the condensation cost. Nonetheless, current DM-based methods have yielded less comparable results to optimization-oriented methods due to their focus on aligning only the first moment of the distributions. In this paper, we present a novel DM-based method named M3D for dataset condensation by Minimizing the Maximum Mean Discrepancy between feature representations of the synthetic and real images. By embedding their distributions in a reproducing kernel Hilbert space, we align all orders of moments of the distributions of real and synthetic images, resulting in a more generalized condensed set. Notably, our method even surpasses the SOTA optimization-oriented method IDC on the high-resolution ImageNet dataset. Extensive analysis is conducted to verify the effectiveness of the proposed method.
Learning Differentially Private Probabilistic Models for Privacy-Preserving Image Generation
May 18, 2023A number of deep models trained on high-quality and valuable images have been deployed in practical applications, which may pose a leakage risk of data privacy. Learning differentially private generative models can sidestep this challenge through indirect data access. However, such differentially private generative models learned by existing approaches can only generate images with a low-resolution of less than 128x128, hindering the widespread usage of generated images in downstream training. In this work, we propose learning differentially private probabilistic models (DPPM) to generate high-resolution images with differential privacy guarantee. In particular, we first train a model to fit the distribution of the training data and make it satisfy differential privacy by performing a randomized response mechanism during training process. Then we perform Hamiltonian dynamics sampling along with the differentially private movement direction predicted by the trained probabilistic model to obtain the privacy-preserving images. In this way, it is possible to apply these images to different downstream tasks while protecting private information. Notably, compared to other state-of-the-art differentially private generative approaches, our approach can generate images up to 256x256 with remarkable visual quality and data utility. Extensive experiments show the effectiveness of our approach.
Deepfake Video Detection with Spatiotemporal Dropout Transformer
Jul 14, 2022



While the abuse of deepfake technology has caused serious concerns recently, how to detect deepfake videos is still a challenge due to the high photo-realistic synthesis of each frame. Existing image-level approaches often focus on single frame and ignore the spatiotemporal cues hidden in deepfake videos, resulting in poor generalization and robustness. The key of a video-level detector is to fully exploit the spatiotemporal inconsistency distributed in local facial regions across different frames in deepfake videos. Inspired by that, this paper proposes a simple yet effective patch-level approach to facilitate deepfake video detection via spatiotemporal dropout transformer. The approach reorganizes each input video into bag of patches that is then fed into a vision transformer to achieve robust representation. Specifically, a spatiotemporal dropout operation is proposed to fully explore patch-level spatiotemporal cues and serve as effective data augmentation to further enhance model's robustness and generalization ability. The operation is flexible and can be easily plugged into existing vision transformers. Extensive experiments demonstrate the effectiveness of our approach against 25 state-of-the-arts with impressive robustness, generalizability, and representation ability.
Interpretable Face Manipulation Detection via Feature Whitening
Jun 21, 2021
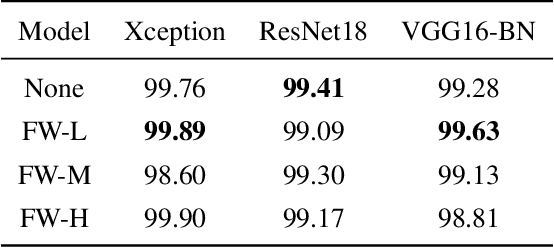
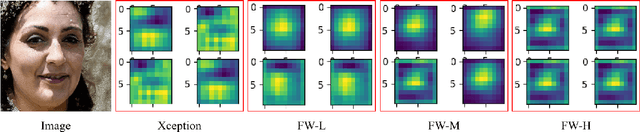
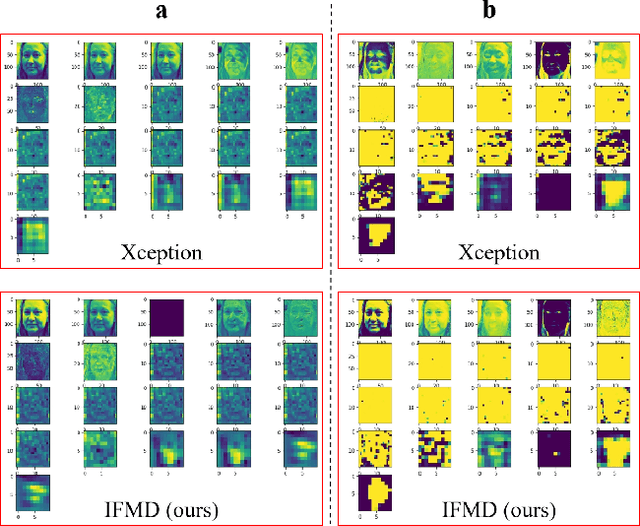
Why should we trust the detections of deep neural networks for manipulated faces? Understanding the reasons is important for users in improving the fairness, reliability, privacy and trust of the detection models. In this work, we propose an interpretable face manipulation detection approach to achieve the trustworthy and accurate inference. The approach could make the face manipulation detection process transparent by embedding the feature whitening module. This module aims to whiten the internal working mechanism of deep networks through feature decorrelation and feature constraint. The experimental results demonstrate that our proposed approach can strike a balance between the detection accuracy and the model interpretability.