 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersaVid-R1: A Versatile Video Understanding and Reasoning Model from Question Answering to Captioning Tasks
Paper and Code
Jun 10, 2025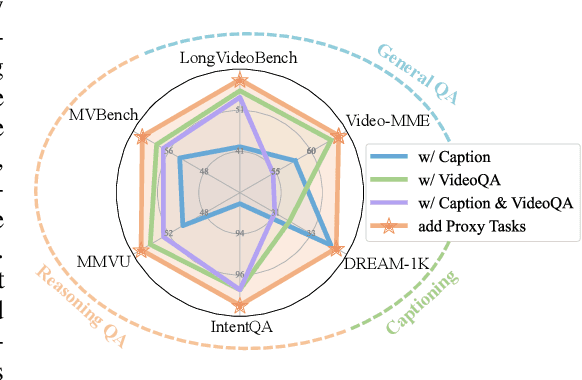

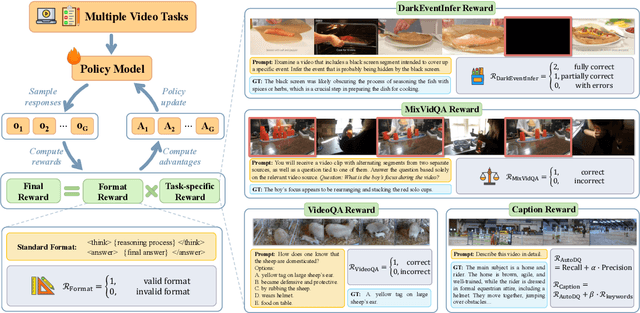

Recent advancements in multimodal large language models have successfully extended the Reason-Then-Respond paradigm to image-based reasoning, yet video-based reasoning remains an underdeveloped frontier, primarily due to the scarcity of high-quality reasoning-oriented data and effective training methodologies. To bridge this gap, we introduce DarkEventInfer and MixVidQA, two novel datasets specifically designed to stimulate the model's advanced video understanding and reasoning abilities. DarkEventinfer presents videos with masked event segments, requiring models to infer the obscured content based on contextual video cues. MixVidQA, on the other hand, presents interleaved video sequences composed of two distinct clips, challenging models to isolate and reason about one while disregarding the other. Leveraging these carefully curated training samples together with reinforcement learning guided by diverse reward functions, we develop VersaVid-R1, the first versatile video understanding and reasoning model under the Reason-Then-Respond paradigm capable of handling multiple-choice and open-ended question answering, as well as video captioning tasks. Extensive experiments demonstrate that VersaVid-R1 significantly outperforms existing models across a broad spectrum of benchmarks, covering video general understanding, cognitive reasoning, and captioning tasks.