 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIA-RAG: Interval-Algebra-Driven Temporal Reasoning for Dynamic Knowledge Retrieval
Jun 04, 2026Retrieval-Augmented Generation (RAG) has shown strong effectiveness in grounding Large Language Models (LLMs) with external knowledge. However, existing RAG and Graph RAG frameworks largely treat knowledge as static or associate time with coarse-grained timestamps or metadata, failing to capture rich temporal structures such as duration, overlap, and containment. We propose IA-RAG, a hierarchical temporal RAG framework that models knowledge as time intervals and performs retrieval under formal temporal constraints. IA-RAG represents facts as Interval Event Units (IEUs) and organizes them into a hierarchical Thematic Forest, where temporal dependencies are governed by Allen's Interval Algebra. To handle incomplete or uncertain temporal boundaries, IA-RAG further introduces a Sub-graph Time Tightening mechanism that refines fuzzy intervals through logical constraints within connected event subgraphs. In addition, IA-RAG supports implicit temporal semantic retrieval through interval-algebra-guided traversal. Experiments on multiple temporal question answering benchmarks, including TimeQA, TempReason, and ComplexTR, demonstrate that IA-RAG achieves strong temporal retrieval and reasoning performance, particularly on complex compositional temporal reasoning tasks. Our code is released at https://github.com/xiaoAugenstern/LogicalRAG_TemporalQA.
Hierarchical Memory Orchestration for Personalized Persistent Agents
Apr 02, 2026While long-term memory is essential for intelligent agents to maintain consistent historical awareness, the accumulation of extensive interaction data often leads to performance bottlenecks. Naive storage expansion increases retrieval noise and computational latency, overwhelming the reasoning capacity of models deployed on constrained personal devices. To address this, we propose Hierarchical Memory Orchestration (HMO), a framework that organizes interaction history into a three-tiered directory driven by user-centric contextual relevance. Our system maintains a compact primary cache, coupling recent and pivotal memories with an evolving user profile to ensure agent reasoning remains aligned with individual behavioral traits. This primary cache is complemented by a high-priority secondary layer, both of which are managed within a global archive of the full interaction history. Crucially, the user persona dictates memory redistribution across this hierarchy, promoting records mapped to long-term patterns toward more active tiers while relegating less relevant information. This targeted orchestration surfaces historical knowledge precisely when needed while maintaining a lean and efficient active search space. Evaluations on multiple benchmarks achieve state-of-the-art performance. Real-world deployments in ecosystems like OpenClaw demonstrate that HMO significantly enhances agent fluidity and personalization.
DUPLEX: Agentic Dual-System Planning via LLM-Driven Information Extraction
Mar 25, 2026While Large Language Models (LLMs) provide semantic flexibility for robotic task planning, their susceptibility to hallucination and logical inconsistency limits their reliability in long-horizon domains. To bridge the gap between unstructured environments and rigorous plan synthesis, we propose DUPLEX, an agentic dual-system neuro-symbolic architecture that strictly confines the LLM to schema-guided information extraction rather than end-to-end planning or code generation. In our framework, a feed-forward Fast System utilizes a lightweight LLM to extract entities, relations etc. from natural language, deterministically mapping them into a Planning Domain Definition Language (PDDL) problem file for a classical symbolic planner. To resolve complex or underspecified scenarios, a Slow System is activated exclusively upon planning failure, leveraging solver diagnostics to drive a high-capacity LLM in iterative reflection and repair. Extensive evaluations across 12 classical and household planning domains demonstrate that DUPLEX significantly outperforms existing end-to-end and hybrid LLM baselines in both success rate and reliability. These results confirm that The key is not to make the LLM plan better, but to restrict the LLM to the part it is good at - structured semantic grounding - and leave logical plan synthesis to a symbolic planner.
Dissecting Subjectivity and the "Ground Truth" Illusion in Data Annotation
Feb 11, 2026In machine learning, "ground truth" refers to the assumed correct labels used to train and evaluate models. However, the foundational "ground truth" paradigm rests on a positivistic fallacy that treats human disagreement as technical noise rather than a vital sociotechnical signal. This systematic literature review analyzes research published between 2020 and 2025 across seven premier venues: ACL, AIES, CHI, CSCW, EAAMO, FAccT, and NeurIPS, investigating the mechanisms in data annotation practices that facilitate this "consensus trap". Our identification phase captured 30,897 records, which were refined via a tiered keyword filtration schema to a high-recall corpus of 3,042 records for manual screening, resulting in a final included corpus of 346 papers for qualitative synthesis. Our reflexive thematic analysis reveals that systemic failures in positional legibility, combined with the recent architectural shift toward human-as-verifier models, specifically the reliance on model-mediated annotations, introduce deep-seated anchoring bias and effectively remove human voices from the loop. We further demonstrate how geographic hegemony imposes Western norms as universal benchmarks, often enforced by the performative alignment of precarious data workers who prioritize requester compliance over honest subjectivity to avoid economic penalties. Critiquing the "noisy sensor" fallacy, where statistical models misdiagnose cultural pluralism as random error, we argue for reclaiming disagreement as a high-fidelity signal essential for building culturally competent models. To address these systemic tensions, we propose a roadmap for pluralistic annotation infrastructures that shift the objective from discovering a singular "right" answer to mapping the diversity of human experience.
The Agent's First Day: Benchmarking Learning, Exploration, and Scheduling in the Workplace Scenarios
Jan 13, 2026The rapid evolution of Multi-modal Large Language Models (MLLMs) has advanced workflow automation; however, existing research mainly targets performance upper bounds in static environments, overlooking robustness for stochastic real-world deployment. We identify three key challenges: dynamic task scheduling, active exploration under uncertainty, and continuous learning from experience. To bridge this gap, we introduce \method{}, a dynamic evaluation environment that simulates a "trainee" agent continuously exploring a novel setting. Unlike traditional benchmarks, \method{} evaluates agents along three dimensions: (1) context-aware scheduling for streaming tasks with varying priorities; (2) prudent information acquisition to reduce hallucination via active exploration; and (3) continuous evolution by distilling generalized strategies from rule-based, dynamically generated tasks. Experiments show that cutting-edge agents have significant deficiencies in dynamic environments, especially in active exploration and continual learning. Our work establishes a framework for assessing agent reliability, shifting evaluation from static tests to realistic, production-oriented scenarios. Our codes are available at https://github.com/KnowledgeXLab/EvoEnv
LeanRAG: Knowledge-Graph-Based Generation with Semantic Aggregation and Hierarchical Retrieval
Aug 14, 2025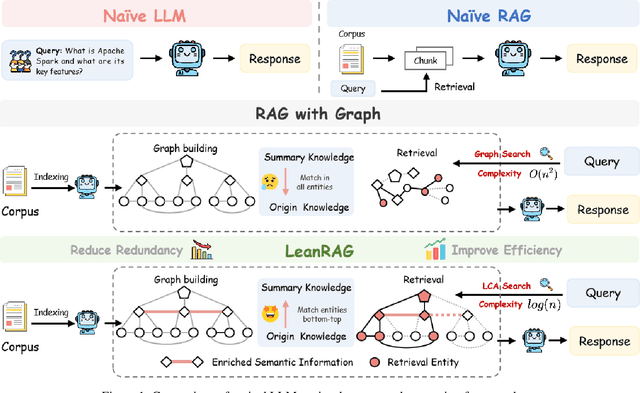
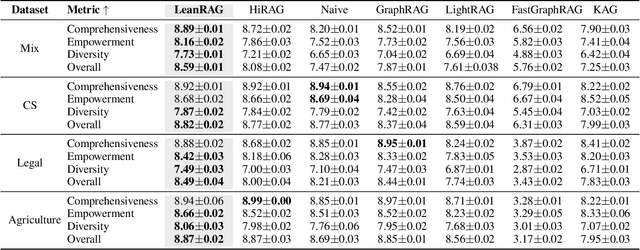
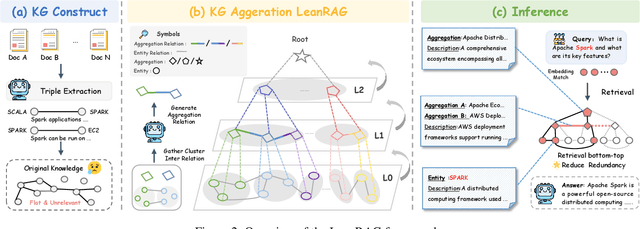

Retrieval-Augmented Generation (RAG) plays a crucial role in grounding Large Language Models by leveraging external knowledge, whereas the effectiveness is often compromised by the retrieval of contextually flawed or incomplete information. To address this, knowledge graph-based RAG methods have evolved towards hierarchical structures, organizing knowledge into multi-level summaries. However, these approaches still suffer from two critical, unaddressed challenges: high-level conceptual summaries exist as disconnected ``semantic islands'', lacking the explicit relations needed for cross-community reasoning; and the retrieval process itself remains structurally unaware, often degenerating into an inefficient flat search that fails to exploit the graph's rich topology. To overcome these limitations, we introduce LeanRAG, a framework that features a deeply collaborative design combining knowledge aggregation and retrieval strategies. LeanRAG first employs a novel semantic aggregation algorithm that forms entity clusters and constructs new explicit relations among aggregation-level summaries, creating a fully navigable semantic network. Then, a bottom-up, structure-guided retrieval strategy anchors queries to the most relevant fine-grained entities and then systematically traverses the graph's semantic pathways to gather concise yet contextually comprehensive evidence sets. The LeanRAG can mitigate the substantial overhead associated with path retrieval on graphs and minimizes redundant information retrieval. Extensive experiments on four challenging QA benchmarks with different domains demonstrate that LeanRAG significantly outperforming existing methods in response quality while reducing 46\% retrieval redundancy. Code is available at: https://github.com/RaZzzyz/LeanRAG
Platform for Representation and Integration of multimodal Molecular Embeddings
Jul 10, 2025Existing machine learning methods for molecular (e.g., gene) embeddings are restricted to specific tasks or data modalities, limiting their effectiveness within narrow domains. As a result, they fail to capture the full breadth of gene functions and interactions across diverse biological contexts. In this study, we have systematically evaluated knowledge representations of biomolecules across multiple dimensions representing a task-agnostic manner spanning three major data sources, including omics experimental data, literature-derived text data, and knowledge graph-based representations. To distinguish between meaningful biological signals from chance correlations, we devised an adjusted variant of Singular Vector Canonical Correlation Analysis (SVCCA) that quantifies signal redundancy and complementarity across different data modalities and sources. These analyses reveal that existing embeddings capture largely non-overlapping molecular signals, highlighting the value of embedding integration. Building on this insight, we propose Platform for Representation and Integration of multimodal Molecular Embeddings (PRISME), a machine learning based workflow using an autoencoder to integrate these heterogeneous embeddings into a unified multimodal representation. We validated this approach across various benchmark tasks, where PRISME demonstrated consistent performance, and outperformed individual embedding methods in missing value imputations. This new framework supports comprehensive modeling of biomolecules, advancing the development of robust, broadly applicable multimodal embeddings optimized for downstream biomedical machine learning applications.
Mosaic: Data-Free Knowledge Distillation via Mixture-of-Experts for Heterogeneous Distributed Environments
May 26, 2025



Federated Learning (FL) is a decentralized machine learning paradigm that enables clients to collaboratively train models while preserving data privacy. However, the coexistence of model and data heterogeneity gives rise to inconsistent representations and divergent optimization dynamics across clients, ultimately hindering robust global performance. To transcend these challenges, we propose Mosaic, a novel data-free knowledge distillation framework tailored for heterogeneous distributed environments. Mosaic first trains local generative models to approximate each client's personalized distribution, enabling synthetic data generation that safeguards privacy through strict separation from real data. Subsequently, Mosaic forms a Mixture-of-Experts (MoE) from client models based on their specialized knowledge, and distills it into a global model using the generated data. To further enhance the MoE architecture, Mosaic integrates expert predictions via a lightweight meta model trained on a few representative prototypes. Extensive experiments on standard image classification benchmarks demonstrate that Mosaic consistently outperforms state-of-the-art approaches under both model and data heterogeneity. The source code has been published at https://github.com/Wings-Of-Disaster/Mosaic.
Materials Generation in the Era of Artificial Intelligence: A Comprehensive Survey
May 22, 2025



Materials are the foundation of modern society, underpinning advancements in energy, electronics, healthcare, transportation, and infrastructure. The ability to discover and design new materials with tailored properties is critical to solving some of the most pressing global challenges. In recent years, the growing availability of high-quality materials data combined with rapid advances in Artificial Intelligence (AI) has opened new opportunities for accelerating materials discovery. Data-driven generative models provide a powerful tool for materials design by directly create novel materials that satisfy predefined property requirements. Despite the proliferation of related work, there remains a notable lack of up-to-date and systematic surveys in this area. To fill this gap, this paper provides a comprehensive overview of recent progress in AI-driven materials generation. We first organize various types of materials and illustrate multiple representations of crystalline materials. We then provide a detailed summary and taxonomy of current AI-driven materials generation approaches. Furthermore, we discuss the common evaluation metrics and summarize open-source codes and benchmark datasets. Finally, we conclude with potential future directions and challenges in this fast-growing field. The related sources can be found at https://github.com/ZhixunLEE/Awesome-AI-for-Materials-Generation.
Bridge2AI: Building A Cross-disciplinary Curriculum Towards AI-Enhanced Biomedical and Clinical Care
May 20, 2025



Objective: As AI becomes increasingly central to healthcare, there is a pressing need for bioinformatics and biomedical training systems that are personalized and adaptable. Materials and Methods: The NIH Bridge2AI Training, Recruitment, and Mentoring (TRM) Working Group developed a cross-disciplinary curriculum grounded in collaborative innovation, ethical data stewardship, and professional development within an adapted Learning Health System (LHS) framework. Results: The curriculum integrates foundational AI modules, real-world projects, and a structured mentee-mentor network spanning Bridge2AI Grand Challenges and the Bridge Center. Guided by six learner personas, the program tailors educational pathways to individual needs while supporting scalability. Discussion: Iterative refinement driven by continuous feedback ensures that content remains responsive to learner progress and emerging trends. Conclusion: With over 30 scholars and 100 mentors engaged across North America, the TRM model demonstrates how adaptive, persona-informed training can build interdisciplinary competencies and foster an integrative, ethically grounded AI education in biomedical contexts.