 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Token-Level Hallucination Detection in Large Language Models
May 12, 2026Large language models (LLMs) have demonstrated remarkable capabilities, but they still frequently produce hallucinations. These hallucinations are difficult to detect in reasoning-intensive tasks, where the content appears coherent but contains errors like logical flaws and unreliable intermediate results. While step-level analysis is commonly used to detect internal hallucinations, it suffers from limited granularity and poor scalability due to its reliance on step segmentation. To address these limitations, we propose TokenHD, a holistic pipeline for training token-level hallucination detectors. Specifically, TokenHD consists of a scalable data engine for synthesizing large-scale hallucination annotations along with a training recipe featuring an importance-weighted strategy for robust model training. To systematically assess the detection performance, we also provide a rigorous evaluation protocol. Through training within TokenHD, our detector operates directly on free-form text to identify hallucinations, eliminating the need for predefined step segmentation or additional text reformatting. Our experiments show that even a small detector (0.6B) achieves substantial performance gains after training, surpassing much larger reasoning models (e.g., QwQ-32B), and detection performance scales consistently with model size from 0.6B to 8B. Finally, we show that our detector can generalize well across diverse practical scenarios and explore strategies to further enhance its cross-domain generalization capability.
Beyond State Consistency: Behavior Consistency in Text-Based World Models
Apr 15, 2026World models have been emerging as critical components for assessing the consequences of actions generated by interactive agents in online planning and offline evaluation. In text-based environments, world models are typically evaluated and trained with single-step metrics such as Exact Match, aiming to improve the similarity between predicted and real-world states, but such metrics have been shown to be insufficient for capturing actual agent behavior. To address this issue, we introduce a new behavior-aligned training paradigm aimed at improving the functional consistency between the world model and the real environment. This paradigm focuses on optimizing a tractable step-level metric named Behavior Consistency Reward (BehR), which measures how much the likelihood of a logged next action changes between the real state and the world-model-predicted state under a frozen Reference Agent. Experiments on WebShop and TextWorld show that BehR-based training improves long-term alignment in several settings, with the clearest gains in WebShop and less movement in near-ceiling regimes, while preserving or improving single-step prediction quality in three of four settings. World models trained with BehR also achieve lower false positives in offline surrogate evaluation and show modest but encouraging gains in inference-time lookahead planning.
AdaVBoost: Mitigating Hallucinations in LVLMs via Token-Level Adaptive Visual Attention Boosting
Feb 14, 2026Visual attention boosting has emerged as a promising direction for mitigating hallucinations in Large Vision-Language Models (LVLMs), where existing methods primarily focus on where to boost by applying a predefined scaling to the attention of method-specific visual tokens during autoregressive generation. In this paper, we identify a fundamental trade-off in these methods: a predefined scaling factor can be too weak at some generation steps, leaving hallucinations unresolved, yet too strong at others, leading to new hallucinations. Motivated by this finding, we propose AdaVBoost, a token-level visual attention boosting framework that adaptively determines how much attention to boost at each generation step. Specifically, we introduce Visual Grounding Entropy (VGE) to estimate hallucination risk, which leverages visual grounding as a complementary signal to capture evidence mismatches beyond entropy. Guided by VGE, AdaVBoost applies stronger visual attention boosting to high-risk tokens and weaker boosting to low-risk tokens, enabling token-level adaptive intervention at each generation step. Extensive experiments show that AdaVBoost significantly outperforms baseline methods across multiple LVLMs and hallucination benchmarks.
Rethinking the Trust Region in LLM Reinforcement Learning
Feb 04, 2026Reinforcement learning (RL) has become a cornerstone for fine-tuning Large Language Models (LLMs), with Proximal Policy Optimization (PPO) serving as the de facto standard algorithm. Despite its ubiquity, we argue that the core ratio clipping mechanism in PPO is structurally ill-suited for the large vocabularies inherent to LLMs. PPO constrains policy updates based on the probability ratio of sampled tokens, which serves as a noisy single-sample Monte Carlo estimate of the true policy divergence. This creates a sub-optimal learning dynamic: updates to low-probability tokens are aggressively over-penalized, while potentially catastrophic shifts in high-probability tokens are under-constrained, leading to training inefficiency and instability. To address this, we propose Divergence Proximal Policy Optimization (DPPO), which substitutes heuristic clipping with a more principled constraint based on a direct estimate of policy divergence (e.g., Total Variation or KL). To avoid huge memory footprint, we introduce the efficient Binary and Top-K approximations to capture the essential divergence with negligible overhead. Extensive empirical evaluations demonstrate that DPPO achieves superior training stability and efficiency compared to existing methods, offering a more robust foundation for RL-based LLM fine-tuning.
Demystifying the Slash Pattern in Attention: The Role of RoPE
Jan 13, 2026Large Language Models (LLMs) often exhibit slash attention patterns, where attention scores concentrate along the $Δ$-th sub-diagonal for some offset $Δ$. These patterns play a key role in passing information across tokens. But why do they emerge? In this paper, we demystify the emergence of these Slash-Dominant Heads (SDHs) from both empirical and theoretical perspectives. First, by analyzing open-source LLMs, we find that SDHs are intrinsic to models and generalize to out-of-distribution prompts. To explain the intrinsic emergence, we analyze the queries, keys, and Rotary Position Embedding (RoPE), which jointly determine attention scores. Our empirical analysis reveals two characteristic conditions of SDHs: (1) Queries and keys are almost rank-one, and (2) RoPE is dominated by medium- and high-frequency components. Under these conditions, queries and keys are nearly identical across tokens, and interactions between medium- and high-frequency components of RoPE give rise to SDHs. Beyond empirical evidence, we theoretically show that these conditions are sufficient to ensure the emergence of SDHs by formalizing them as our modeling assumptions. Particularly, we analyze the training dynamics of a shallow Transformer equipped with RoPE under these conditions, and prove that models trained via gradient descent exhibit SDHs. The SDHs generalize to out-of-distribution prompts.
Defeating the Training-Inference Mismatch via FP16
Oct 30, 2025Reinforcement learning (RL) fine-tuning of large language models (LLMs) often suffers from instability due to the numerical mismatch between the training and inference policies. While prior work has attempted to mitigate this issue through algorithmic corrections or engineering alignments, we show that its root cause lies in the floating point precision itself. The widely adopted BF16, despite its large dynamic range, introduces large rounding errors that breaks the consistency between training and inference. In this work, we demonstrate that simply reverting to \textbf{FP16} effectively eliminates this mismatch. The change is simple, fully supported by modern frameworks with only a few lines of code change, and requires no modification to the model architecture or learning algorithm. Our results suggest that using FP16 uniformly yields more stable optimization, faster convergence, and stronger performance across diverse tasks, algorithms and frameworks. We hope these findings motivate a broader reconsideration of precision trade-offs in RL fine-tuning.
Nonparametric Data Attribution for Diffusion Models
Oct 16, 2025Data attribution for generative models seeks to quantify the influence of individual training examples on model outputs. Existing methods for diffusion models typically require access to model gradients or retraining, limiting their applicability in proprietary or large-scale settings. We propose a nonparametric attribution method that operates entirely on data, measuring influence via patch-level similarity between generated and training images. Our approach is grounded in the analytical form of the optimal score function and naturally extends to multiscale representations, while remaining computationally efficient through convolution-based acceleration. In addition to producing spatially interpretable attributions, our framework uncovers patterns that reflect intrinsic relationships between training data and outputs, independent of any specific model. Experiments demonstrate that our method achieves strong attribution performance, closely matching gradient-based approaches and substantially outperforming existing nonparametric baselines. Code is available at https://github.com/sail-sg/NDA.
Imperceptible Jailbreaking against Large Language Models
Oct 06, 2025Jailbreaking attacks on the vision modality typically rely on imperceptible adversarial perturbations, whereas attacks on the textual modality are generally assumed to require visible modifications (e.g., non-semantic suffixes). In this paper, we introduce imperceptible jailbreaks that exploit a class of Unicode characters called variation selectors. By appending invisible variation selectors to malicious questions, the jailbreak prompts appear visually identical to original malicious questions on screen, while their tokenization is "secretly" altered. We propose a chain-of-search pipeline to generate such adversarial suffixes to induce harmful responses. Our experiments show that our imperceptible jailbreaks achieve high attack success rates against four aligned LLMs and generalize to prompt injection attacks, all without producing any visible modifications in the written prompt. Our code is available at https://github.com/sail-sg/imperceptible-jailbreaks.
Variational Reasoning for Language Models
Sep 26, 2025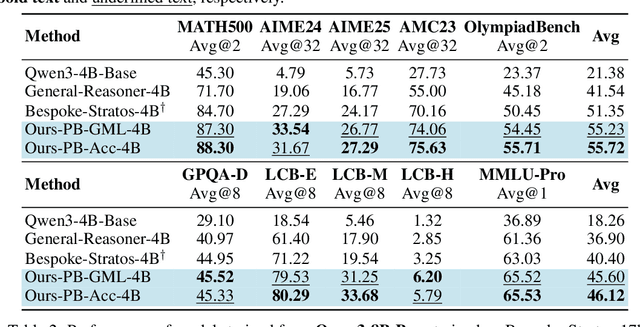
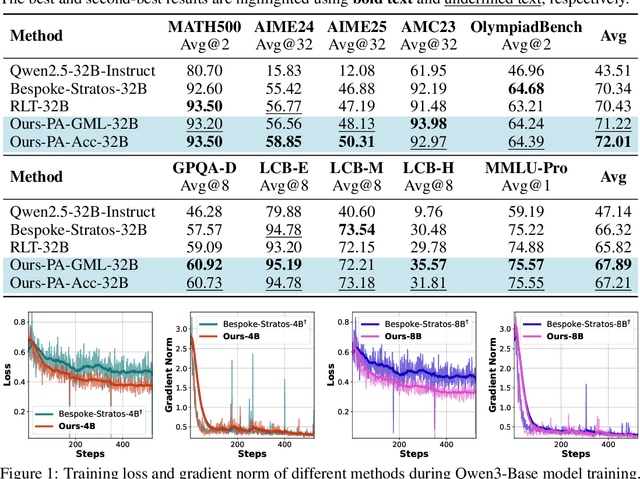
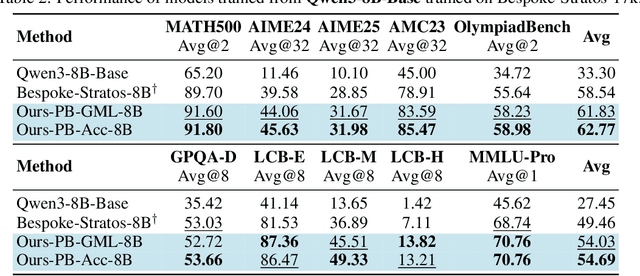
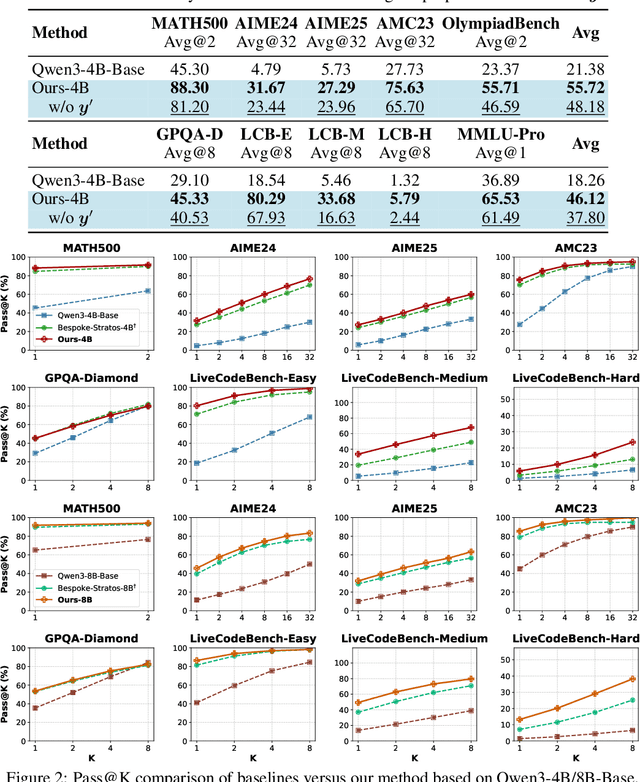
We introduce a variational reasoning framework for language models that treats thinking traces as latent variables and optimizes them through variational inference. Starting from the evidence lower bound (ELBO), we extend it to a multi-trace objective for tighter bounds and propose a forward-KL formulation that stabilizes the training of the variational posterior. We further show that rejection sampling finetuning and binary-reward RL, including GRPO, can be interpreted as local forward-KL objectives, where an implicit weighting by model accuracy naturally arises from the derivation and reveals a previously unnoticed bias toward easier questions. We empirically validate our method on the Qwen 2.5 and Qwen 3 model families across a wide range of reasoning tasks. Overall, our work provides a principled probabilistic perspective that unifies variational inference with RL-style methods and yields stable objectives for improving the reasoning ability of language models. Our code is available at https://github.com/sail-sg/variational-reasoning.
Language Models Can Learn from Verbal Feedback Without Scalar Rewards
Sep 26, 2025



LLMs are often trained with RL from human or AI feedback, yet such methods typically compress nuanced feedback into scalar rewards, discarding much of their richness and inducing scale imbalance. We propose treating verbal feedback as a conditioning signal. Inspired by language priors in text-to-image generation, which enable novel outputs from unseen prompts, we introduce the feedback-conditional policy (FCP). FCP learns directly from response-feedback pairs, approximating the feedback-conditional posterior through maximum likelihood training on offline data. We further develop an online bootstrapping stage where the policy generates under positive conditions and receives fresh feedback to refine itself. This reframes feedback-driven learning as conditional generation rather than reward optimization, offering a more expressive way for LLMs to directly learn from verbal feedback. Our code is available at https://github.com/sail-sg/feedback-conditional-policy.