 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
GenPilot: A Multi-Agent System for Test-Time Prompt Optimization in Image Generation
Oct 08, 2025Text-to-image synthesis has made remarkable progress, yet accurately interpreting complex and lengthy prompts remains challenging, often resulting in semantic inconsistencies and missing details. Existing solutions, such as fine-tuning, are model-specific and require training, while prior automatic prompt optimization (APO) approaches typically lack systematic error analysis and refinement strategies, resulting in limited reliability and effectiveness. Meanwhile, test-time scaling methods operate on fixed prompts and on noise or sample numbers, limiting their interpretability and adaptability. To solve these, we introduce a flexible and efficient test-time prompt optimization strategy that operates directly on the input text. We propose a plug-and-play multi-agent system called GenPilot, integrating error analysis, clustering-based adaptive exploration, fine-grained verification, and a memory module for iterative optimization. Our approach is model-agnostic, interpretable, and well-suited for handling long and complex prompts. Simultaneously, we summarize the common patterns of errors and the refinement strategy, offering more experience and encouraging further exploration. Experiments on DPG-bench and Geneval with improvements of up to 16.9% and 5.7% demonstrate the strong capability of our methods in enhancing the text and image consistency and structural coherence of generated images, revealing the effectiveness of our test-time prompt optimization strategy. The code is available at https://github.com/27yw/GenPilot.
Variational Reasoning for Language Models
Sep 26, 2025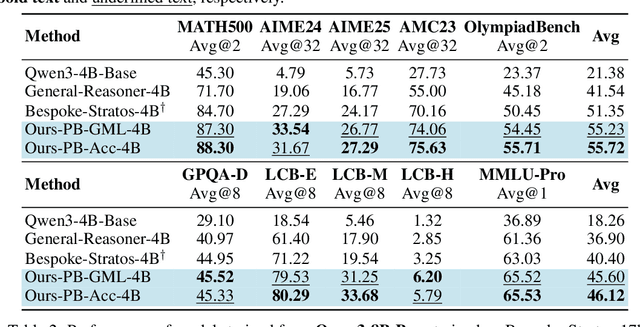
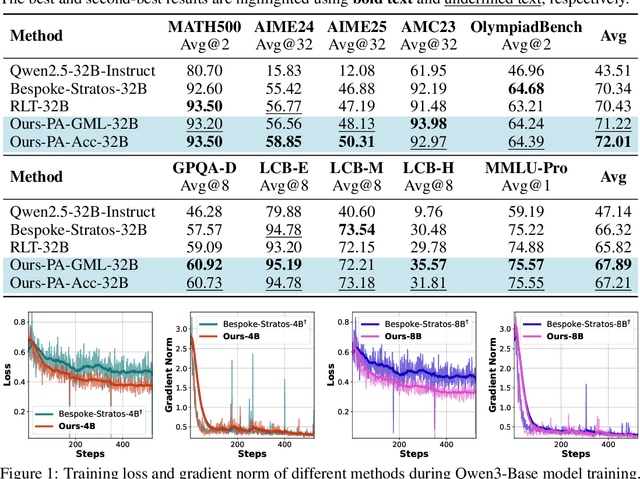
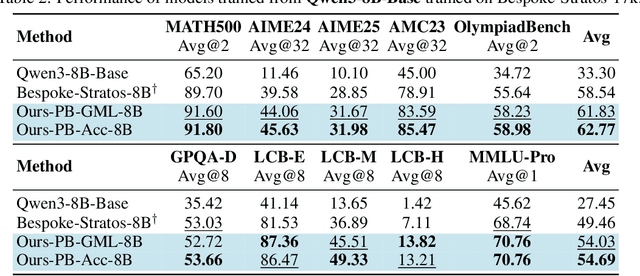
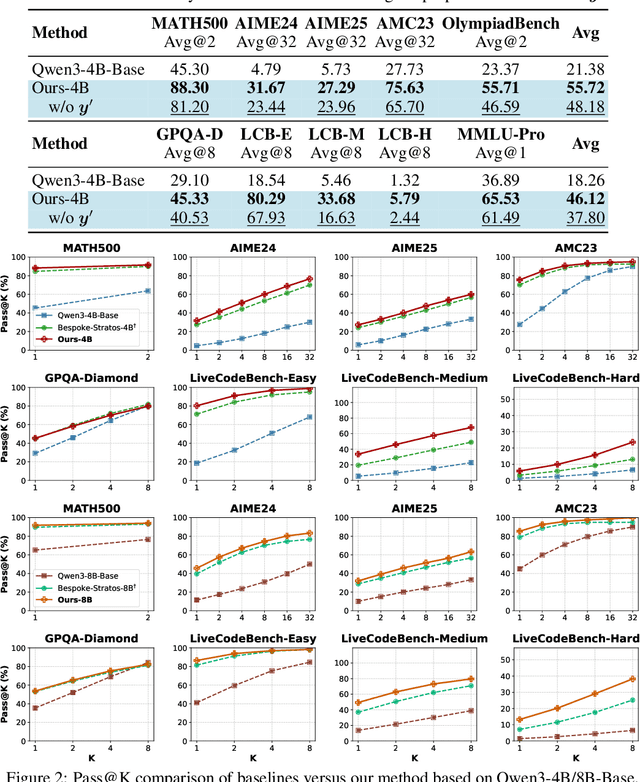
We introduce a variational reasoning framework for language models that treats thinking traces as latent variables and optimizes them through variational inference. Starting from the evidence lower bound (ELBO), we extend it to a multi-trace objective for tighter bounds and propose a forward-KL formulation that stabilizes the training of the variational posterior. We further show that rejection sampling finetuning and binary-reward RL, including GRPO, can be interpreted as local forward-KL objectives, where an implicit weighting by model accuracy naturally arises from the derivation and reveals a previously unnoticed bias toward easier questions. We empirically validate our method on the Qwen 2.5 and Qwen 3 model families across a wide range of reasoning tasks. Overall, our work provides a principled probabilistic perspective that unifies variational inference with RL-style methods and yields stable objectives for improving the reasoning ability of language models. Our code is available at https://github.com/sail-sg/variational-reasoning.
EgoDemoGen: Novel Egocentric Demonstration Generation Enables Viewpoint-Robust Manipulation
Sep 26, 2025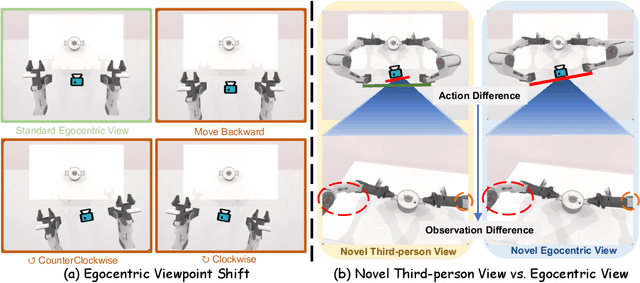

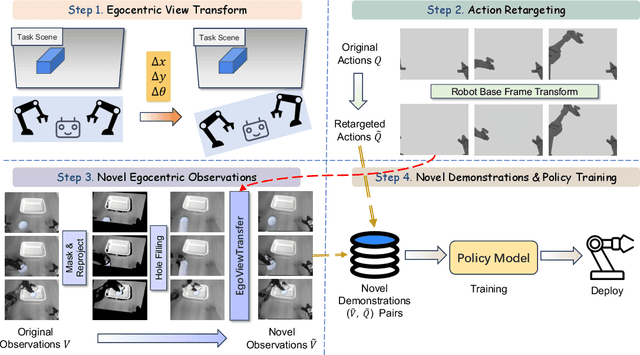
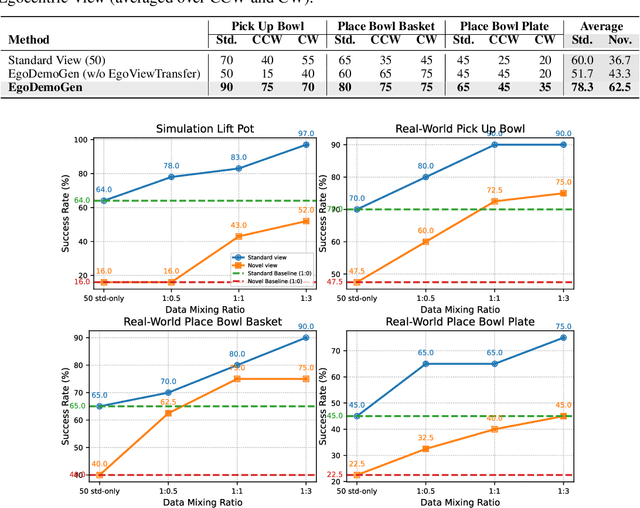
Imitation learning based policies perform well in robotic manipulation, but they often degrade under *egocentric viewpoint shifts* when trained from a single egocentric viewpoint. To address this issue, we present **EgoDemoGen**, a framework that generates *paired* novel egocentric demonstrations by retargeting actions in the novel egocentric frame and synthesizing the corresponding egocentric observation videos with proposed generative video repair model **EgoViewTransfer**, which is conditioned by a novel-viewpoint reprojected scene video and a robot-only video rendered from the retargeted joint actions. EgoViewTransfer is finetuned from a pretrained video generation model using self-supervised double reprojection strategy. We evaluate EgoDemoGen on both simulation (RoboTwin2.0) and real-world robot. After training with a mixture of EgoDemoGen-generated novel egocentric demonstrations and original standard egocentric demonstrations, policy success rate improves **absolutely** by **+17.0%** for standard egocentric viewpoint and by **+17.7%** for novel egocentric viewpoints in simulation. On real-world robot, the **absolute** improvements are **+18.3%** and **+25.8%**. Moreover, performance continues to improve as the proportion of EgoDemoGen-generated demonstrations increases, with diminishing returns. These results demonstrate that EgoDemoGen provides a practical route to egocentric viewpoint-robust robotic manipulation.
BaseReward: A Strong Baseline for Multimodal Reward Model
Sep 19, 2025



The rapid advancement of Multimodal Large Language Models (MLLMs) has made aligning them with human preferences a critical challenge. Reward Models (RMs) are a core technology for achieving this goal, but a systematic guide for building state-of-the-art Multimodal Reward Models (MRMs) is currently lacking in both academia and industry. Through exhaustive experimental analysis, this paper aims to provide a clear ``recipe'' for constructing high-performance MRMs. We systematically investigate every crucial component in the MRM development pipeline, including \textit{reward modeling paradigms} (e.g., Naive-RM, Critic-based RM, and Generative RM), \textit{reward head architecture}, \textit{training strategies}, \textit{data curation} (covering over ten multimodal and text-only preference datasets), \textit{backbone model} and \textit{model scale}, and \textit{ensemble methods}. Based on these experimental insights, we introduce \textbf{BaseReward}, a powerful and efficient baseline for multimodal reward modeling. BaseReward adopts a simple yet effective architecture, built upon a {Qwen2.5-VL} backbone, featuring an optimized two-layer reward head, and is trained on a carefully curated mixture of high-quality multimodal and text-only preference data. Our results show that BaseReward establishes a new SOTA on major benchmarks such as MM-RLHF-Reward Bench, VL-Reward Bench, and Multimodal Reward Bench, outperforming previous models. Furthermore, to validate its practical utility beyond static benchmarks, we integrate BaseReward into a real-world reinforcement learning pipeline, successfully enhancing an MLLM's performance across various perception, reasoning, and conversational tasks. This work not only delivers a top-tier MRM but, more importantly, provides the community with a clear, empirically-backed guide for developing robust reward models for the next generation of MLLMs.
Solving the Min-Max Multiple Traveling Salesmen Problem via Learning-Based Path Generation and Optimal Splitting
Aug 23, 2025This study addresses the Min-Max Multiple Traveling Salesmen Problem ($m^3$-TSP), which aims to coordinate tours for multiple salesmen such that the length of the longest tour is minimized. Due to its NP-hard nature, exact solvers become impractical under the assumption that $P \ne NP$. As a result, learning-based approaches have gained traction for their ability to rapidly generate high-quality approximate solutions. Among these, two-stage methods combine learning-based components with classical solvers, simplifying the learning objective. However, this decoupling often disrupts consistent optimization, potentially degrading solution quality. To address this issue, we propose a novel two-stage framework named \textbf{Generate-and-Split} (GaS), which integrates reinforcement learning (RL) with an optimal splitting algorithm in a joint training process. The splitting algorithm offers near-linear scalability with respect to the number of cities and guarantees optimal splitting in Euclidean space for any given path. To facilitate the joint optimization of the RL component with the algorithm, we adopt an LSTM-enhanced model architecture to address partial observability. Extensive experiments show that the proposed GaS framework significantly outperforms existing learning-based approaches in both solution quality and transferability.
AeroDuo: Aerial Duo for UAV-based Vision and Language Navigation
Aug 21, 2025Aerial Vision-and-Language Navigation (VLN) is an emerging task that enables Unmanned Aerial Vehicles (UAVs) to navigate outdoor environments using natural language instructions and visual cues. However, due to the extended trajectories and complex maneuverability of UAVs, achieving reliable UAV-VLN performance is challenging and often requires human intervention or overly detailed instructions. To harness the advantages of UAVs' high mobility, which could provide multi-grained perspectives, while maintaining a manageable motion space for learning, we introduce a novel task called Dual-Altitude UAV Collaborative VLN (DuAl-VLN). In this task, two UAVs operate at distinct altitudes: a high-altitude UAV responsible for broad environmental reasoning, and a low-altitude UAV tasked with precise navigation. To support the training and evaluation of the DuAl-VLN, we construct the HaL-13k, a dataset comprising 13,838 collaborative high-low UAV demonstration trajectories, each paired with target-oriented language instructions. This dataset includes both unseen maps and an unseen object validation set to systematically evaluate the model's generalization capabilities across novel environments and unfamiliar targets. To consolidate their complementary strengths, we propose a dual-UAV collaborative VLN framework, AeroDuo, where the high-altitude UAV integrates a multimodal large language model (Pilot-LLM) for target reasoning, while the low-altitude UAV employs a lightweight multi-stage policy for navigation and target grounding. The two UAVs work collaboratively and only exchange minimal coordinate information to ensure efficiency.
Foundation Model for Skeleton-Based Human Action Understanding
Aug 18, 2025Human action understanding serves as a foundational pillar in the field of intelligent motion perception. Skeletons serve as a modality- and device-agnostic representation for human modeling, and skeleton-based action understanding has potential applications in humanoid robot control and interaction. \RED{However, existing works often lack the scalability and generalization required to handle diverse action understanding tasks. There is no skeleton foundation model that can be adapted to a wide range of action understanding tasks}. This paper presents a Unified Skeleton-based Dense Representation Learning (USDRL) framework, which serves as a foundational model for skeleton-based human action understanding. USDRL consists of a Transformer-based Dense Spatio-Temporal Encoder (DSTE), Multi-Grained Feature Decorrelation (MG-FD), and Multi-Perspective Consistency Training (MPCT). The DSTE module adopts two parallel streams to learn temporal dynamic and spatial structure features. The MG-FD module collaboratively performs feature decorrelation across temporal, spatial, and instance domains to reduce dimensional redundancy and enhance information extraction. The MPCT module employs both multi-view and multi-modal self-supervised consistency training. The former enhances the learning of high-level semantics and mitigates the impact of low-level discrepancies, while the latter effectively facilitates the learning of informative multimodal features. We perform extensive experiments on 25 benchmarks across across 9 skeleton-based action understanding tasks, covering coarse prediction, dense prediction, and transferred prediction. Our approach significantly outperforms the current state-of-the-art methods. We hope that this work would broaden the scope of research in skeleton-based action understanding and encourage more attention to dense prediction tasks.
OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025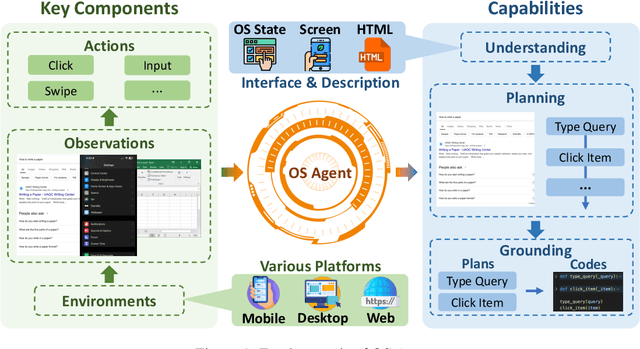
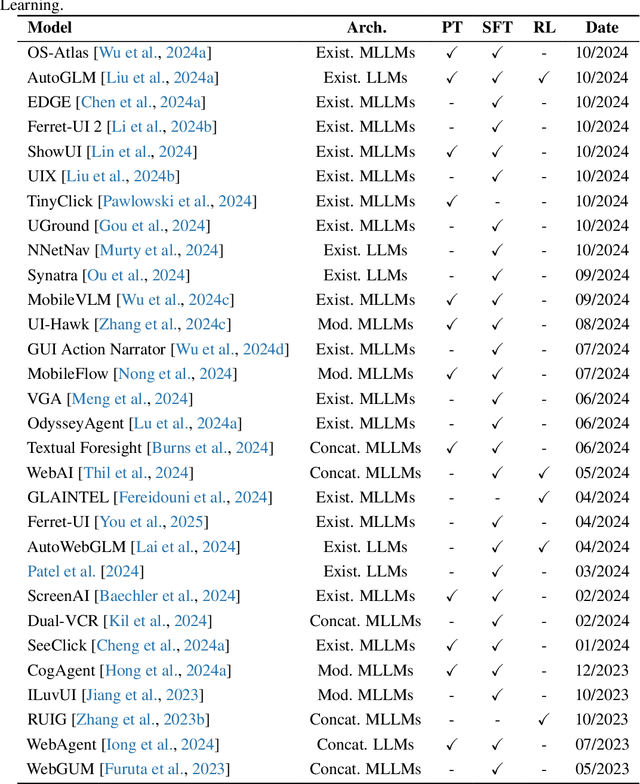
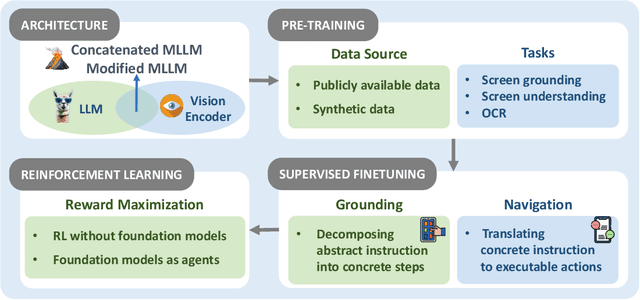
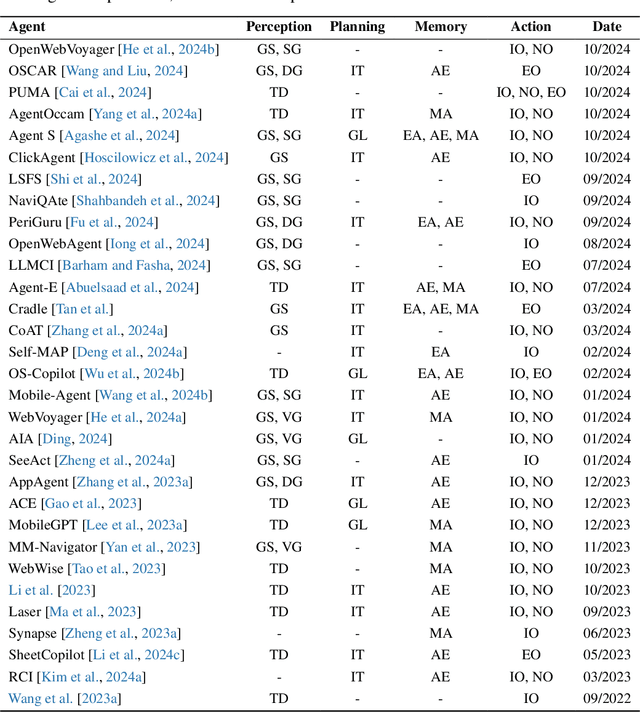
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.
DTPA: Dynamic Token-level Prefix Augmentation for Controllable Text Generation
Aug 06, 2025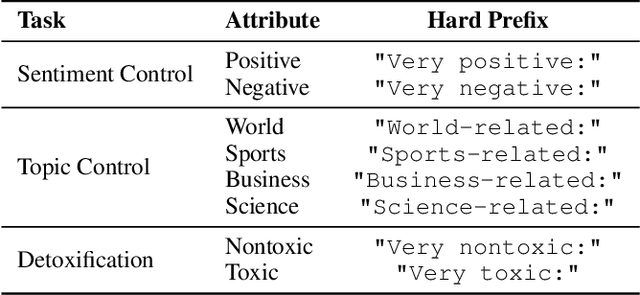

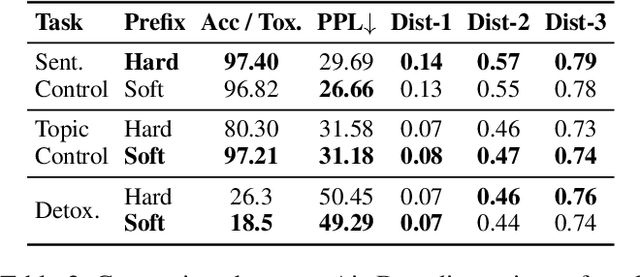

Controllable Text Generation (CTG) is a vital subfield in Natural Language Processing (NLP), aiming to generate text that aligns with desired attributes. However, previous studies commonly focus on the quality of controllable text generation for short sequences, while the generation of long-form text remains largely underexplored. In this paper, we observe that the controllability of texts generated by the powerful prefix-based method Air-Decoding tends to decline with increasing sequence length, which we hypothesize primarily arises from the observed decay in attention to the prefixes. Meanwhile, different types of prefixes including soft and hard prefixes are also key factors influencing performance. Building on these insights, we propose a lightweight and effective framework called Dynamic Token-level Prefix Augmentation (DTPA) based on Air-Decoding for controllable text generation. Specifically, it first selects the optimal prefix type for a given task. Then we dynamically amplify the attention to the prefix for the attribute distribution to enhance controllability, with a scaling factor growing exponentially as the sequence length increases. Moreover, based on the task, we optionally apply a similar augmentation to the original prompt for the raw distribution to balance text quality. After attribute distribution reconstruction, the generated text satisfies the attribute constraints well. Experiments on multiple CTG tasks demonstrate that DTPA generally outperforms other methods in attribute control while maintaining competitive fluency, diversity, and topic relevance. Further analysis highlights DTPA's superior effectiveness in long text generation.