 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Long-Context Retrieval with Multi-Prefix Embedding
Jun 22, 2026Long-context retrieval exposes a tension: single-vector embeddings lose fine-grained detail, while token-level multi-vector methods incur prohibitive storage. We propose Multi-Prefix Embedding (MPE), which partitions a document into chunks separated by EOS tokens, encodes the full sequence in a single causal forward pass, and extracts one embedding at each prefix boundary. MPE retains cross-chunk context, enables chunk-level MaxSim matching, and trains with only document-level relevance labels. Experiments on MLDR-en, BrowseComp-Plus, and LongEmbed show that MPE is competitive with or outperforms single-vector, independent-chunk, and multi-vector baselines, while providing a natural source attribution mechanism for locating evidence chunks.
The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
A Sober Look at Agentic Misalignment in Automated Workflows
May 22, 2026We study a class of emergent misalignment in multi-agent systems (MAS), with a focus on automated workflows, which we refer to agentic misalignment. Although these systems can solve complex tasks, they often fail because agents act according to implicit proxy utilities that do not align with the intended human goals. We formally define these behaviors and analyze them within a Bayesian framework, showing that generic utilities naturally lead to posterior collapse of agents in automated workflows. To address this issue, we propose Agentic Evidence Attribution (AEA), a novel alignment paradigm that improves agent posteriors using context-specific evidence. AEA reasons over agent actions and provides structured evidence to correct misaligned behavior during collaboration. To better understand the role of evidence, we study two instantiations of AEA: self-reflection (internal evidence from the model) and weak-to-strong generalization (external evidence on the agentic trajectory). We show that a small evidence model effectively aligns the MAS by providing orthogonal failure attribution. Our results clarify the sources of agentic misalignment in automated workflows and show that evidence-based alignment can effectively improve agent collaboration and leads to reliable multi-agent systems built on automated workflows.
Layer-wise Token Compression for Efficient Document Reranking
May 21, 2026Transformer-based document cross-encoder rerankers are a central component of modern information retrieval systems. Despite their success, these models suffer from high computational costs due to processing long query-document sequences at inference time. A known approach to improve efficiency is token compression, which consists of aggregating groups of tokens together in the initial embedding layer, reducing the effective number of tokens, and making the computation faster. While token compression has proven to be successful for bi-encoder retrievers, we empirically observed that this approach may be ineffective for cross-encoder rerankers. In this paper, we propose Layer-wise Token Compression (LTC), which applies adaptive token pooling at intermediate transformer layers. Through extensive ablation studies on MS MARCO passage and document ranking tasks, we demonstrate that compression at middle layers preserves ranking quality while increasing inference QPS by up to 25% for passage ranking and up to 116% for document ranking. We also extend LTC to listwise LLM rerankers and show that the same approach can be easily applied to long-context listwise reranking, where the QPS improvements are even greater. More surprisingly, when applying rerankers trained on short passages to long-document ranking tasks, models trained with compression outperform their uncompressed counterparts, suggesting that compression may act as a beneficial regularizer that encourages length-invariant representations.
CLEAR: Context Augmentation from Contrastive Learning of Experience via Agentic Reflection
Apr 08, 2026Large language model agents rely on effective model context to obtain task-relevant information for decision-making. Many existing context engineering approaches primarily rely on the context generated from the past experience and retrieval mechanisms that reuse these context. However, retrieved context from past tasks must be adapted by the execution agent to fit new situations, placing additional reasoning burden on the underlying LLM. To address this limitation, we propose a generative context augmentation framework using Contrastive Learning of Experience via Agentic Reflection (CLEAR). CLEAR first employs a reflection agent to perform contrastive analysis over past execution trajectories and summarize useful context for each observed task. These summaries are then used as supervised fine-tuning data to train a context augmentation model (CAM). Then we further optimize CAM using reinforcement learning, where the reward signal is obtained by running the task execution agent. By learning to generate task-specific knowledge rather than retrieve knowledge from the past, CAM produces context that is better tailored to the current task. We conduct comprehensive evaluations on the AppWorld and WebShop benchmarks. Experimental results show that CLEAR consistently outperforms strong baselines. It improves task completion rate from 72.62% to 81.15% on AppWorld test set and averaged reward from 0.68 to 0.74 on a subset of WebShop, compared with baseline agent. Our code is publicly available at https://github.com/awslabs/CLEAR.
BayesFlow: A Probability Inference Framework for Meta-Agent Assisted Workflow Generation
Jan 29, 2026Automatic workflow generation is the process of automatically synthesizing sequences of LLM calls, tool invocations, and post-processing steps for complex end-to-end tasks. Most prior methods cast this task as an optimization problem with limited theoretical grounding. We propose to cast workflow generation as Bayesian inference over a posterior distribution on workflows, and introduce \textbf{Bayesian Workflow Generation (BWG)}, a sampling framework that builds workflows step-by-step using parallel look-ahead rollouts for importance weighting and a sequential in-loop refiner for pool-wide improvements. We prove that, without the refiner, the weighted empirical distribution converges to the target posterior. We instantiate BWG as \textbf{BayesFlow}, a training-free algorithm for workflow construction. Across six benchmark datasets, BayesFlow improves accuracy by up to 9 percentage points over SOTA workflow generation baselines and by up to 65 percentage points over zero-shot prompting, establishing BWG as a principled upgrade to search-based workflow design. Code will be available on https://github.com/BoYuanVisionary/BayesFlow.
Learning to Ideate for Machine Learning Engineering Agents
Jan 24, 2026Existing machine learning engineering (MLE) agents struggle to iteratively optimize their implemented algorithms for effectiveness. To address this, we introduce MLE-Ideator, a dual-agent framework that separates ideation from implementation. In our system, an implementation agent can request strategic help from a dedicated Ideator. We show this approach is effective in two ways. First, in a training-free setup, our framework significantly outperforms implementation-only agent baselines on MLE-Bench. Second, we demonstrate that the Ideator can be trained with reinforcement learning (RL) to generate more effective ideas. With only 1K training samples from 10 MLE tasks, our RL-trained Qwen3-8B Ideator achieves an 11.5% relative improvement compared to its untrained counterpart and surpasses Claude Sonnet 3.5. These results highlights a promising path toward training strategic AI systems for scientific discovery.
LACONIC: Dense-Level Effectiveness for Scalable Sparse Retrieval via a Two-Phase Training Curriculum
Jan 04, 2026While dense retrieval models have become the standard for state-of-the-art information retrieval, their deployment is often constrained by high memory requirements and reliance on GPU accelerators for vector similarity search. Learned sparse retrieval offers a compelling alternative by enabling efficient search via inverted indices, yet it has historically received less attention than dense approaches. In this report, we introduce LACONIC, a family of learned sparse retrievers based on the Llama-3 architecture (1B, 3B, and 8B). We propose a streamlined two-phase training curriculum consisting of (1) weakly supervised pre-finetuning to adapt causal LLMs for bidirectional contextualization and (2) high-signal finetuning using curated hard negatives. Our results demonstrate that LACONIC effectively bridges the performance gap with dense models: the 8B variant achieves a state-of-the-art 60.2 nDCG on the MTEB Retrieval benchmark, ranking 15th on the leaderboard as of January 1, 2026, while utilizing 71\% less index memory than an equivalent dense model. By delivering high retrieval effectiveness on commodity CPU hardware with a fraction of the compute budget required by competing models, LACONIC provides a scalable and efficient solution for real-world search applications.
Teaching People LLM's Errors and Getting it Right
Dec 24, 2025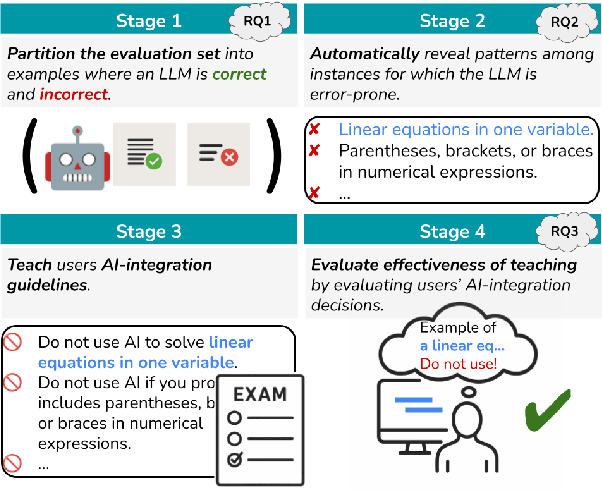
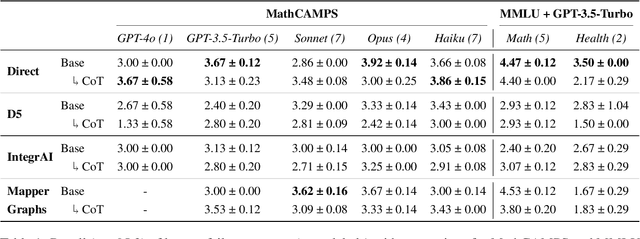
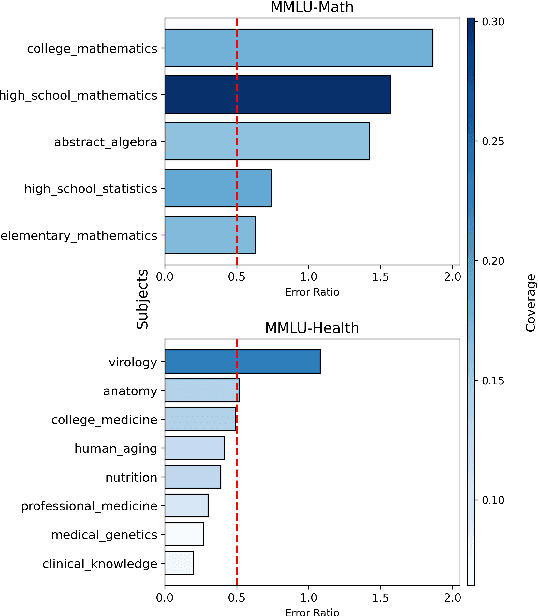
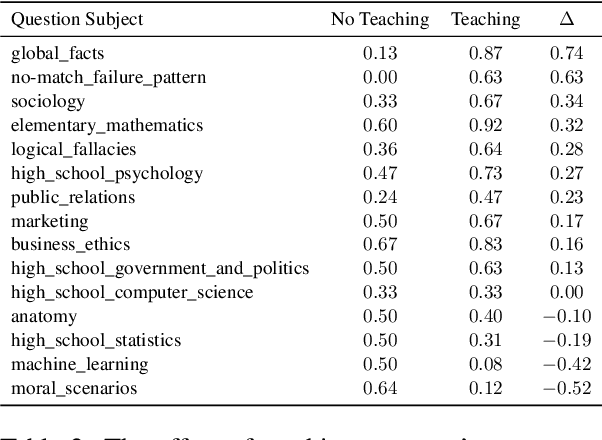
People use large language models (LLMs) when they should not. This is partly because they see LLMs compose poems and answer intricate questions, so they understandably, but incorrectly, assume LLMs won't stumble on basic tasks like simple arithmetic. Prior work has tried to address this by clustering instance embeddings into regions where an LLM is likely to fail and automatically describing patterns in these regions. The found failure patterns are taught to users to mitigate their overreliance. Yet, this approach has not fully succeeded. In this analysis paper, we aim to understand why. We first examine whether the negative result stems from the absence of failure patterns. We group instances in two datasets by their meta-labels and evaluate an LLM's predictions on these groups. We then define criteria to flag groups that are sizable and where the LLM is error-prone, and find meta-label groups that meet these criteria. Their meta-labels are the LLM's failure patterns that could be taught to users, so they do exist. We next test whether prompting and embedding-based approaches can surface these known failures. Without this, users cannot be taught about them to reduce their overreliance. We find mixed results across methods, which could explain the negative result. Finally, we revisit the final metric that measures teaching effectiveness. We propose to assess a user's ability to effectively use the given failure patterns to anticipate when an LLM is error-prone. A user study shows a positive effect from teaching with this metric, unlike the human-AI team accuracy. Our findings show that teaching failure patterns could be a viable approach to mitigating overreliance, but success depends on better automated failure-discovery methods and using metrics like ours.
Reinforcement Learning for Self-Improving Agent with Skill Library
Dec 18, 2025



Large Language Model (LLM)-based agents have demonstrated remarkable capabilities in complex reasoning and multi-turn interactions but struggle to continuously improve and adapt when deployed in new environments. One promising approach is implementing skill libraries that allow agents to learn, validate, and apply new skills. However, current skill library approaches rely primarily on LLM prompting, making consistent skill library implementation challenging. To overcome these challenges, we propose a Reinforcement Learning (RL)-based approach to enhance agents' self-improvement capabilities with a skill library. Specifically, we introduce Skill Augmented GRPO for self-Evolution (SAGE), a novel RL framework that systematically incorporates skills into learning. The framework's key component, Sequential Rollout, iteratively deploys agents across a chain of similar tasks for each rollout. As agents navigate through the task chain, skills generated from previous tasks accumulate in the library and become available for subsequent tasks. Additionally, the framework enhances skill generation and utilization through a Skill-integrated Reward that complements the original outcome-based rewards. Experimental results on AppWorld demonstrate that SAGE, when applied to supervised-finetuned model with expert experience, achieves 8.9% higher Scenario Goal Completion while requiring 26% fewer interaction steps and generating 59% fewer tokens, substantially outperforming existing approaches in both accuracy and efficiency.