 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrameQuant: Flexible Low-Bit Quantization for Transformers
Mar 10, 2024



Transformers are the backbone of powerful foundation models for many Vision and Natural Language Processing tasks. But their compute and memory/storage footprint is large, and so, serving such models is expensive often requiring high-end hardware. To mitigate this difficulty, Post-Training Quantization seeks to modify a pre-trained model and quantize it to eight bits or lower, significantly boosting compute/memory/latency efficiency. Such models have been successfully quantized to four bits with some performance loss. In this work, we outline a simple scheme to quantize Transformer-based models to just two bits (plus some overhead) with only a small drop in accuracy. Key to our formulation is a concept borrowed from Harmonic analysis called Fusion Frames. Our main finding is that the quantization must take place not in the original weight space, but instead in the Fusion Frame representations. If quantization is interpreted as the addition of noise, our casting of the problem allows invoking an extensive body of known consistent recovery and noise robustness guarantees. Further, if desired, de-noising filters are known in closed form. We show empirically, via a variety of experiments, that (almost) two-bit quantization for Transformer models promises sizable efficiency gains.
RSAM-Seg: A SAM-based Approach with Prior Knowledge Integration for Remote Sensing Image Semantic Segmentation
Feb 29, 2024



The development of high-resolution remote sensing satellites has provided great convenience for research work related to remote sensing. Segmentation and extraction of specific targets are essential tasks when facing the vast and complex remote sensing images. Recently, the introduction of Segment Anything Model (SAM) provides a universal pre-training model for image segmentation tasks. While the direct application of SAM to remote sensing image segmentation tasks does not yield satisfactory results, we propose RSAM-Seg, which stands for Remote Sensing SAM with Semantic Segmentation, as a tailored modification of SAM for the remote sensing field and eliminates the need for manual intervention to provide prompts. Adapter-Scale, a set of supplementary scaling modules, are proposed in the multi-head attention blocks of the encoder part of SAM. Furthermore, Adapter-Feature are inserted between the Vision Transformer (ViT) blocks. These modules aim to incorporate high-frequency image information and image embedding features to generate image-informed prompts. Experiments are conducted on four distinct remote sensing scenarios, encompassing cloud detection, field monitoring, building detection and road mapping tasks . The experimental results not only showcase the improvement over the original SAM and U-Net across cloud, buildings, fields and roads scenarios, but also highlight the capacity of RSAM-Seg to discern absent areas within the ground truth of certain datasets, affirming its potential as an auxiliary annotation method. In addition, the performance in few-shot scenarios is commendable, underscores its potential in dealing with limited datasets.
PROC2PDDL: Open-Domain Planning Representations from Texts
Feb 29, 2024



Planning in a text-based environment continues to be a major challenge for AI systems. Recent approaches have used language models to predict a planning domain definition (e.g., PDDL) but have only been evaluated in closed-domain simulated environments. To address this, we present Proc2PDDL , the first dataset containing open-domain procedural texts paired with expert-annotated PDDL representations. Using this dataset, we evaluate state-of-the-art models on defining the preconditions and effects of actions. We show that Proc2PDDL is highly challenging, with GPT-3.5's success rate close to 0% and GPT-4's around 35%. Our analysis shows both syntactic and semantic errors, indicating LMs' deficiency in both generating domain-specific prgorams and reasoning about events. We hope this analysis and dataset helps future progress towards integrating the best of LMs and formal planning.
From Summary to Action: Enhancing Large Language Models for Complex Tasks with Open World APIs
Feb 28, 2024The distinction between humans and animals lies in the unique ability of humans to use and create tools. Tools empower humans to overcome physiological limitations, fostering the creation of magnificent civilizations. Similarly, enabling foundational models like Large Language Models (LLMs) with the capacity to learn external tool usage may serve as a pivotal step toward realizing artificial general intelligence. Previous studies in this field have predominantly pursued two distinct approaches to augment the tool invocation capabilities of LLMs. The first approach emphasizes the construction of relevant datasets for model fine-tuning. The second approach, in contrast, aims to fully exploit the inherent reasoning abilities of LLMs through in-context learning strategies. In this work, we introduce a novel tool invocation pipeline designed to control massive real-world APIs. This pipeline mirrors the human task-solving process, addressing complicated real-life user queries. At each step, we guide LLMs to summarize the achieved results and determine the next course of action. We term this pipeline `from Summary to action', Sum2Act for short. Empirical evaluations of our Sum2Act pipeline on the ToolBench benchmark show significant performance improvements, outperforming established methods like ReAct and DFSDT. This highlights Sum2Act's effectiveness in enhancing LLMs for complex real-world tasks.
Clustering and Ranking: Diversity-preserved Instruction Selection through Expert-aligned Quality Estimation
Feb 28, 2024



With contributions from the open-source community, a vast amount of instruction tuning (IT) data has emerged. Given the significant resource allocation required by training and evaluating models, it is advantageous to have an efficient method for selecting high-quality IT data. However, existing methods for instruction data selection have limitations such as relying on fragile external APIs, being affected by biases in GPT models, or reducing the diversity of the selected instruction dataset. In this paper, we propose an industrial-friendly, expert-aligned and diversity-preserved instruction data selection method: Clustering and Ranking (CaR). CaR consists of two steps. The first step involves ranking instruction pairs using a scoring model that is well aligned with expert preferences (achieving an accuracy of 84.25%). The second step involves preserving dataset diversity through a clustering process.In our experiment, CaR selected a subset containing only 1.96% of Alpaca's IT data, yet the underlying AlpaCaR model trained on this subset outperforms Alpaca by an average of 32.1% in GPT-4 evaluations. Furthermore, our method utilizes small models (355M parameters) and requires only 11.2% of the monetary cost compared to existing methods, making it easily deployable in industrial scenarios.
FrameNeRF: A Simple and Efficient Framework for Few-shot Novel View Synthesis
Feb 26, 2024
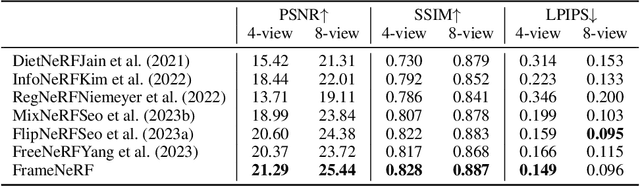
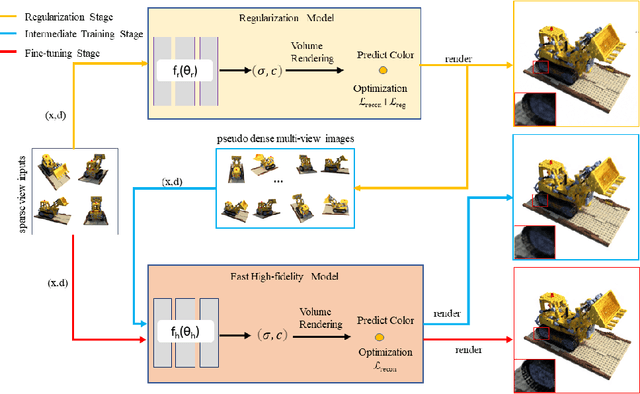
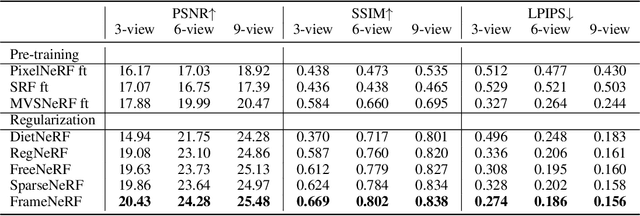
We present a novel framework, called FrameNeRF, designed to apply off-the-shelf fast high-fidelity NeRF models with fast training speed and high rendering quality for few-shot novel view synthesis tasks. The training stability of fast high-fidelity models is typically constrained to dense views, making them unsuitable for few-shot novel view synthesis tasks. To address this limitation, we utilize a regularization model as a data generator to produce dense views from sparse inputs, facilitating subsequent training of fast high-fidelity models. Since these dense views are pseudo ground truth generated by the regularization model, original sparse images are then used to fine-tune the fast high-fidelity model. This process helps the model learn realistic details and correct artifacts introduced in earlier stages. By leveraging an off-the-shelf regularization model and a fast high-fidelity model, our approach achieves state-of-the-art performance across various benchmark datasets.
A First Look at GPT Apps: Landscape and Vulnerability
Feb 23, 2024With the advancement of Large Language Models (LLMs), increasingly sophisticated and powerful GPTs are entering the market. Despite their popularity, the LLM ecosystem still remains unexplored. Additionally, LLMs' susceptibility to attacks raises concerns over safety and plagiarism. Thus, in this work, we conduct a pioneering exploration of GPT stores, aiming to study vulnerabilities and plagiarism within GPT applications. To begin with, we conduct, to our knowledge, the first large-scale monitoring and analysis of two stores, an unofficial GPTStore.AI, and an official OpenAI GPT Store. Then, we propose a TriLevel GPT Reversing (T-GR) strategy for extracting GPT internals. To complete these two tasks efficiently, we develop two automated tools: one for web scraping and another designed for programmatically interacting with GPTs. Our findings reveal a significant enthusiasm among users and developers for GPT interaction and creation, as evidenced by the rapid increase in GPTs and their creators. However, we also uncover a widespread failure to protect GPT internals, with nearly 90% of system prompts easily accessible, leading to considerable plagiarism and duplication among GPTs.
A Neural-network Enhanced Video Coding Framework beyond ECM
Feb 21, 2024



In this paper, a hybrid video compression framework is proposed that serves as a demonstrative showcase of deep learning-based approaches extending beyond the confines of traditional coding methodologies. The proposed hybrid framework is founded upon the Enhanced Compression Model (ECM), which is a further enhancement of the Versatile Video Coding (VVC) standard. We have augmented the latest ECM reference software with well-designed coding techniques, including block partitioning, deep learning-based loop filter, and the activation of block importance mapping (BIM) which was integrated but previously inactive within ECM, further enhancing coding performance. Compared with ECM-10.0, our method achieves 6.26, 13.33, and 12.33 BD-rate savings for the Y, U, and V components under random access (RA) configuration, respectively.
Calibrating Large Language Models with Sample Consistency
Feb 21, 2024Accurately gauging the confidence level of Large Language Models' (LLMs) predictions is pivotal for their reliable application. However, LLMs are often uncalibrated inherently and elude conventional calibration techniques due to their proprietary nature and massive scale. In this work, we explore the potential of deriving confidence from the distribution of multiple randomly sampled model generations, via three measures of consistency. We perform an extensive evaluation across various open and closed-source models on nine reasoning datasets. Results show that consistency-based calibration methods outperform existing post-hoc approaches. Meanwhile, we find that factors such as intermediate explanations, model scaling, and larger sample sizes enhance calibration, while instruction-tuning makes calibration more difficult. Moreover, confidence scores obtained from consistency have the potential to enhance model performance. Finally, we offer practical guidance on choosing suitable consistency metrics for calibration, tailored to the characteristics of various LMs.
Translating Images to Road Network:A Non-Autoregressive Sequence-to-Sequence Approach
Feb 13, 2024



The extraction of road network is essential for the generation of high-definition maps since it enables the precise localization of road landmarks and their interconnections. However, generating road network poses a significant challenge due to the conflicting underlying combination of Euclidean (e.g., road landmarks location) and non-Euclidean (e.g., road topological connectivity) structures. Existing methods struggle to merge the two types of data domains effectively, but few of them address it properly. Instead, our work establishes a unified representation of both types of data domain by projecting both Euclidean and non-Euclidean data into an integer series called RoadNet Sequence. Further than modeling an auto-regressive sequence-to-sequence Transformer model to understand RoadNet Sequence, we decouple the dependency of RoadNet Sequence into a mixture of auto-regressive and non-autoregressive dependency. Building on this, our proposed non-autoregressive sequence-to-sequence approach leverages non-autoregressive dependencies while fixing the gap towards auto-regressive dependencies, resulting in success on both efficiency and accuracy. Extensive experiments on nuScenes dataset demonstrate the superiority of RoadNet Sequence representation and the non-autoregressive approach compared to existing state-of-the-art alternatives. The code is open-source on https://github.com/fudan-zvg/RoadNetworkTRansformer.