 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Synergistic CNN-Transformer Network with Pooling Attention Fusion for Hyperspectral Image Classification
Apr 26, 2026In the hyperspectral image (HSI) classification task, each pixel is categorized into a specific land-cover category or material. Convolutional neural networks (CNNs) and transformers have been widely used to extract local and non-local features in HSI classification. Recent works have utilized a multi-scale vision transformer (ViT) to enhance spectral feature capture and yield promising results. However, most existing methods still face challenges in the effective joint use of spatial-spectral information and in preserving information across layers during the propagation process. To address these issues, we propose a synergistic CNN-Transformer network with pooling attention fusion for HSI classification, which collaboratively utilizes CNNs and ViT to process spatial and spectral features separately. Specifically, we propose a Twin-Branch Feature Extraction (TBFE) module, which employs 3D and 2D convolution in parallel to comprehensively extract spectral and spatial features from HSI. A hybrid pooling attention (HPA) module is designed to aggregate spatial attention. Moreover, a cascade transformer encoder is employed for global spectral feature extraction, and a simple yet efficient cross-layer feature fusion (CFF) module is designed to reduce the loss of crucial information in the previous network layers. Extensive experiments are conducted on several representative datasets to demonstrate the superior performance of our proposed method compared to the state-of-the-art works. Code is available at https://github.com/chenpeng052/SCT-Net.git.
Customizing Large Vision Model-Guided Low-Rank Approximation for Ground-Roll Denoise
Apr 01, 2026Ground-roll is a dominant source of coherent noise in land and vertical seismic profiling (VSP) data, severely masking reflection events and degrading subsequent imaging and interpretation. Conventional attenuation methods, including transform-domain filtering, sparse representation, and deep learning, often suffer from limited adaptability, signal leakage, or dependence on labeled training data, especially under strong signal-noise overlap. To address these challenges, we propose a training-free framework that reformulates ground-roll attenuation as a semantic-guided signal separation problem. Specifically, a promptable large vision model is employed to extract high-level semantic priors by converting seismic gathers into visual representations and localizing ground-roll-dominant regions via text or image prompts. The resulting semantic response is transformed into a continuous soft mask, which is embedded into a mask-conditioned low-rank inverse formulation to enable spatially adaptive suppression and reflection-preserving reconstruction. An efficient alternating direction method of multipliers (ADMM)-based solver is further developed to solve the proposed inverse problem, enabling stable and physically consistent signal recovery without requiring task-specific training or manual annotation. Extensive experiments on both synthetic and field VSP datasets demonstrate that the proposed method achieves superior ground-roll attenuation while preserving reflection continuity and waveform fidelity, consistently outperforming representative transform-domain filtering and implicit neural representation methods.
Camel: Frame-Level Bandwidth Estimation for Low-Latency Live Streaming under Video Bitrate Undershooting
Feb 10, 2026Low-latency live streaming (LLS) has emerged as a popular web application, with many platforms adopting real-time protocols such as WebRTC to minimize end-to-end latency. However, we observe a counter-intuitive phenomenon: even when the actual encoded bitrate does not fully utilize the available bandwidth, stalling events remain frequent. This insufficient bandwidth utilization arises from the intrinsic temporal variations of real-time video encoding, which cause conventional packet-level congestion control algorithms to misestimate available bandwidth. When a high-bitrate frame is suddenly produced, sending at the wrong rate can either trigger packet loss or increase queueing delay, resulting in playback stalls. To address these issues, we present Camel, a novel frame-level congestion control algorithm (CCA) tailored for LLS. Our insight is to use frame-level network feedback to capture the true network capacity, immune to the irregular sending pattern caused by encoding. Camel comprises three key modules: the Bandwidth and Delay Estimator and the Congestion Detector, which jointly determine the average sending rate, and the Bursting Length Controller, which governs the emission pattern to prevent packet loss. We evaluate Camel on both large-scale real-world deployments and controlled simulations. In the real-world platform with 250M users and 2B sessions across 150+ countries, Camel achieves up to a 70.8% increase in 1080P resolution ratio, a 14.4% increase in media bitrate, and up to a 14.1% reduction in stalling ratio. In simulations under undershooting, shallow buffers, and network jitter, Camel outperforms existing congestion control algorithms, with up to 19.8% higher bitrate, 93.0% lower stalling ratio, and 23.9% improvement in bandwidth estimation accuracy.
* 8 pages, 20 figures, to appear in WWW 2026
DidSee: Diffusion-Based Depth Completion for Material-Agnostic Robotic Perception and Manipulation
Jun 26, 2025Commercial RGB-D cameras often produce noisy, incomplete depth maps for non-Lambertian objects. Traditional depth completion methods struggle to generalize due to the limited diversity and scale of training data. Recent advances exploit visual priors from pre-trained text-to-image diffusion models to enhance generalization in dense prediction tasks. However, we find that biases arising from training-inference mismatches in the vanilla diffusion framework significantly impair depth completion performance. Additionally, the lack of distinct visual features in non-Lambertian regions further hinders precise prediction. To address these issues, we propose \textbf{DidSee}, a diffusion-based framework for depth completion on non-Lambertian objects. First, we integrate a rescaled noise scheduler enforcing a zero terminal signal-to-noise ratio to eliminate signal leakage bias. Second, we devise a noise-agnostic single-step training formulation to alleviate error accumulation caused by exposure bias and optimize the model with a task-specific loss. Finally, we incorporate a semantic enhancer that enables joint depth completion and semantic segmentation, distinguishing objects from backgrounds and yielding precise, fine-grained depth maps. DidSee achieves state-of-the-art performance on multiple benchmarks, demonstrates robust real-world generalization, and effectively improves downstream tasks such as category-level pose estimation and robotic grasping.Project page: https://wenzhoulyu.github.io/DidSee/
HeterMoE: Efficient Training of Mixture-of-Experts Models on Heterogeneous GPUs
Apr 04, 2025The Mixture-of-Experts (MoE) architecture has become increasingly popular as a method to scale up large language models (LLMs). To save costs, heterogeneity-aware training solutions have been proposed to utilize GPU clusters made up of both newer and older-generation GPUs. However, existing solutions are agnostic to the performance characteristics of different MoE model components (i.e., attention and expert) and do not fully utilize each GPU's compute capability. In this paper, we introduce HeterMoE, a system to efficiently train MoE models on heterogeneous GPUs. Our key insight is that newer GPUs significantly outperform older generations on attention due to architectural advancements, while older GPUs are still relatively efficient for experts. HeterMoE disaggregates attention and expert computation, where older GPUs are only assigned with expert modules. Through the proposed zebra parallelism, HeterMoE overlaps the computation on different GPUs, in addition to employing an asymmetric expert assignment strategy for fine-grained load balancing to minimize GPU idle time. Our evaluation shows that HeterMoE achieves up to 2.3x speed-up compared to existing MoE training systems, and 1.4x compared to an optimally balanced heterogeneity-aware solution. HeterMoE efficiently utilizes older GPUs by maintaining 95% training throughput on average, even with half of the GPUs in a homogeneous A40 cluster replaced with V100.
VoLUT: Efficient Volumetric streaming enhanced by LUT-based super-resolution
Feb 17, 20253D volumetric video provides immersive experience and is gaining traction in digital media. Despite its rising popularity, the streaming of volumetric video content poses significant challenges due to the high data bandwidth requirement. A natural approach to mitigate the bandwidth issue is to reduce the volumetric video's data rate by downsampling the content prior to transmission. The video can then be upsampled at the receiver's end using a super-resolution (SR) algorithm to reconstruct the high-resolution details. While super-resolution techniques have been extensively explored and advanced for 2D video content, there is limited work on SR algorithms tailored for volumetric videos. To address this gap and the growing need for efficient volumetric video streaming, we have developed VoLUT with a new SR algorithm specifically designed for volumetric content. Our algorithm uniquely harnesses the power of lookup tables (LUTs) to facilitate the efficient and accurate upscaling of low-resolution volumetric data. The use of LUTs enables our algorithm to quickly reference precomputed high-resolution values, thereby significantly reducing the computational complexity and time required for upscaling. We further apply adaptive video bit rate algorithm (ABR) to dynamically determine the downsampling rate according to the network condition and stream the selected video rate to the receiver. Compared to related work, VoLUT is the first to enable high-quality 3D SR on commodity mobile devices at line-rate. Our evaluation shows VoLUT can reduce bandwidth usage by 70% , boost QoE by 36.7% for volumetric video streaming and achieve 3D SR speed-up with no quality compromise.
A First Look at GPT Apps: Landscape and Vulnerability
Feb 23, 2024With the advancement of Large Language Models (LLMs), increasingly sophisticated and powerful GPTs are entering the market. Despite their popularity, the LLM ecosystem still remains unexplored. Additionally, LLMs' susceptibility to attacks raises concerns over safety and plagiarism. Thus, in this work, we conduct a pioneering exploration of GPT stores, aiming to study vulnerabilities and plagiarism within GPT applications. To begin with, we conduct, to our knowledge, the first large-scale monitoring and analysis of two stores, an unofficial GPTStore.AI, and an official OpenAI GPT Store. Then, we propose a TriLevel GPT Reversing (T-GR) strategy for extracting GPT internals. To complete these two tasks efficiently, we develop two automated tools: one for web scraping and another designed for programmatically interacting with GPTs. Our findings reveal a significant enthusiasm among users and developers for GPT interaction and creation, as evidenced by the rapid increase in GPTs and their creators. However, we also uncover a widespread failure to protect GPT internals, with nearly 90% of system prompts easily accessible, leading to considerable plagiarism and duplication among GPTs.
Adaptive Skeleton Graph Decoding
Feb 19, 2024



Large language models (LLMs) have seen significant adoption for natural language tasks, owing their success to massive numbers of model parameters (e.g., 70B+); however, LLM inference incurs significant computation and memory costs. Recent approaches propose parallel decoding strategies, such as Skeleton-of-Thought (SoT), to improve performance by breaking prompts down into sub-problems that can be decoded in parallel; however, they often suffer from reduced response quality. Our key insight is that we can request additional information, specifically dependencies and difficulty, when generating the sub-problems to improve both response quality and performance. In this paper, we propose Skeleton Graph Decoding (SGD), which uses dependencies exposed between sub-problems to support information forwarding between dependent sub-problems for improved quality while exposing parallelization opportunities for decoding independent sub-problems. Additionally, we leverage difficulty estimates for each sub-problem to select an appropriately-sized model, improving performance without significantly reducing quality. Compared to standard autoregressive generation and SoT, SGD achieves a 1.69x speedup while improving quality by up to 51%.
Let All be Whitened: Multi-teacher Distillation for Efficient Visual Retrieval
Dec 15, 2023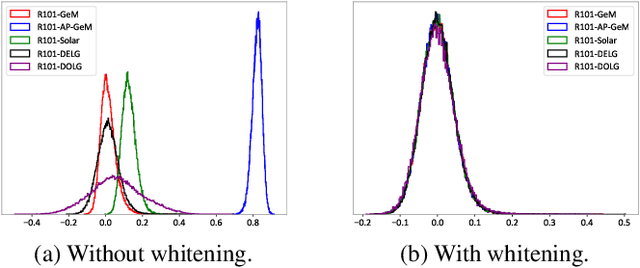
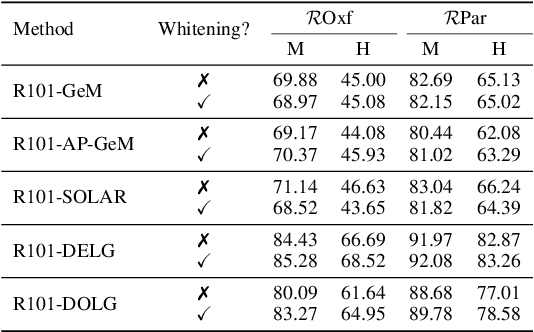
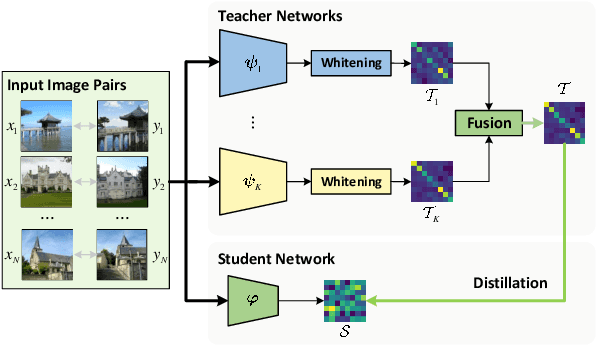
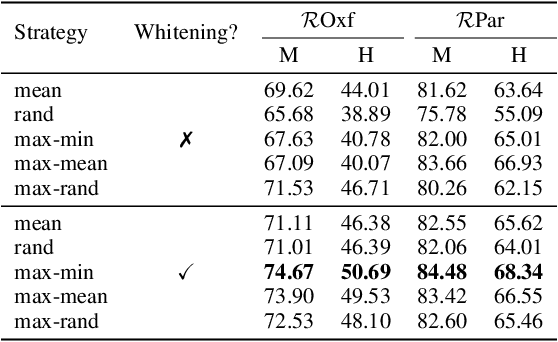
Visual retrieval aims to search for the most relevant visual items, e.g., images and videos, from a candidate gallery with a given query item. Accuracy and efficiency are two competing objectives in retrieval tasks. Instead of crafting a new method pursuing further improvement on accuracy, in this paper we propose a multi-teacher distillation framework Whiten-MTD, which is able to transfer knowledge from off-the-shelf pre-trained retrieval models to a lightweight student model for efficient visual retrieval. Furthermore, we discover that the similarities obtained by different retrieval models are diversified and incommensurable, which makes it challenging to jointly distill knowledge from multiple models. Therefore, we propose to whiten the output of teacher models before fusion, which enables effective multi-teacher distillation for retrieval models. Whiten-MTD is conceptually simple and practically effective. Extensive experiments on two landmark image retrieval datasets and one video retrieval dataset demonstrate the effectiveness of our proposed method, and its good balance of retrieval performance and efficiency. Our source code is released at https://github.com/Maryeon/whiten_mtd.
Interpretable Deep Reinforcement Learning for Optimizing Heterogeneous Energy Storage Systems
Oct 20, 2023



Energy storage systems (ESS) are pivotal component in the energy market, serving as both energy suppliers and consumers. ESS operators can reap benefits from energy arbitrage by optimizing operations of storage equipment. To further enhance ESS flexibility within the energy market and improve renewable energy utilization, a heterogeneous photovoltaic-ESS (PV-ESS) is proposed, which leverages the unique characteristics of battery energy storage (BES) and hydrogen energy storage (HES). For scheduling tasks of the heterogeneous PV-ESS, cost description plays a crucial role in guiding operator's strategies to maximize benefits. We develop a comprehensive cost function that takes into account degradation, capital, and operation/maintenance costs to reflect real-world scenarios. Moreover, while numerous methods excel in optimizing ESS energy arbitrage, they often rely on black-box models with opaque decision-making processes, limiting practical applicability. To overcome this limitation and enable transparent scheduling strategies, a prototype-based policy network with inherent interpretability is introduced. This network employs human-designed prototypes to guide decision-making by comparing similarities between prototypical situations and encountered situations, which allows for naturally explained scheduling strategies. Comparative results across four distinct cases underscore the effectiveness and practicality of our proposed pre-hoc interpretable optimization method when contrasted with black-box models.