 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOCHA: Multi-Objective Chebyshev Annealing for Agent Skill Optimization
May 19, 2026LLM agents organize behavior through skills - structured natural-language specifications governing how an agent reasons, retrieves, and responds. Unlike monolithic prompts, skills are multi-field artifacts subject to hard platform constraints: description fields are truncated for routing, instruction bodies are compacted via progressive disclosure, and co-resident skills compete for limited context windows. These constraints make skill optimization inherently multi-objective: a skill must simultaneously maximize task performance and satisfy platform limits. Yet existing prompt optimizers either ignore these trade-offs or collapse them into a weighted sum, missing Pareto-optimal variants in non-convex objective regions. We introduce MOCHA (Multi-Objective Chebyshev Annealing), which replaces single-objective selection with Chebyshev scalarization - covering the full Pareto front, including non-convex regions - combined with exponential annealing that transitions from exploration to exploitation. In our experiments across six diverse agent skills - where all methods share the same multi-objective mutation operator and baselines receive identical per-objective textual feedback - existing optimizers fail to improve the seed skill on 4 of 6 tasks: 1000 rollouts yield zero progress. MOCHA breaks through on every task, achieving 7.5% relative improvement in mean correctness over the strongest baseline (up to 14.9% on FEVER and 10.4% on TheoremQA) while discovering twice as many more Pareto-optimal skill variants.
Zoomer: Adaptive Image Focus Optimization for Black-box MLLM
Apr 30, 2025

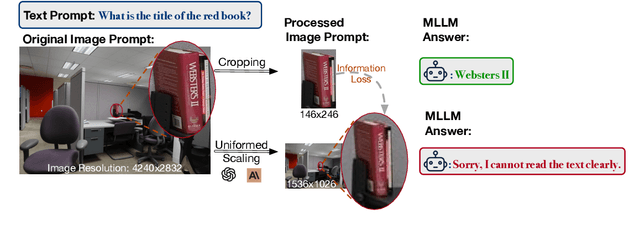
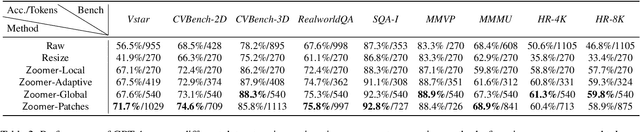
Recent advancements in multimodal large language models (MLLMs) have broadened the scope of vision-language tasks, excelling in applications like image captioning and interactive question-answering. However, these models struggle with accurately processing visual data, particularly in tasks requiring precise object recognition and fine visual details. Stringent token limits often result in the omission of critical information, hampering performance. To address these limitations, we introduce \SysName, a novel visual prompting mechanism designed to enhance MLLM performance while preserving essential visual details within token limits. \SysName features three key innovations: a prompt-aware strategy that dynamically highlights relevant image regions, a spatial-preserving orchestration schema that maintains object integrity, and a budget-aware prompting method that balances global context with crucial visual details. Comprehensive evaluations across multiple datasets demonstrate that \SysName consistently outperforms baseline methods, achieving up to a $26.9\%$ improvement in accuracy while significantly reducing token consumption.
Exponentially Weighted Instance-Aware Repeat Factor Sampling for Long-Tailed Object Detection Model Training in Unmanned Aerial Vehicles Surveillance Scenarios
Mar 27, 2025Object detection models often struggle with class imbalance, where rare categories appear significantly less frequently than common ones. Existing sampling-based rebalancing strategies, such as Repeat Factor Sampling (RFS) and Instance-Aware Repeat Factor Sampling (IRFS), mitigate this issue by adjusting sample frequencies based on image and instance counts. However, these methods are based on linear adjustments, which limit their effectiveness in long-tailed distributions. This work introduces Exponentially Weighted Instance-Aware Repeat Factor Sampling (E-IRFS), an extension of IRFS that applies exponential scaling to better differentiate between rare and frequent classes. E-IRFS adjusts sampling probabilities using an exponential function applied to the geometric mean of image and instance frequencies, ensuring a more adaptive rebalancing strategy. We evaluate E-IRFS on a dataset derived from the Fireman-UAV-RGBT Dataset and four additional public datasets, using YOLOv11 object detection models to identify fire, smoke, people and lakes in emergency scenarios. The results show that E-IRFS improves detection performance by 22\% over the baseline and outperforms RFS and IRFS, particularly for rare categories. The analysis also highlights that E-IRFS has a stronger effect on lightweight models with limited capacity, as these models rely more on data sampling strategies to address class imbalance. The findings demonstrate that E-IRFS improves rare object detection in resource-constrained environments, making it a suitable solution for real-time applications such as UAV-based emergency monitoring.
VoLUT: Efficient Volumetric streaming enhanced by LUT-based super-resolution
Feb 17, 20253D volumetric video provides immersive experience and is gaining traction in digital media. Despite its rising popularity, the streaming of volumetric video content poses significant challenges due to the high data bandwidth requirement. A natural approach to mitigate the bandwidth issue is to reduce the volumetric video's data rate by downsampling the content prior to transmission. The video can then be upsampled at the receiver's end using a super-resolution (SR) algorithm to reconstruct the high-resolution details. While super-resolution techniques have been extensively explored and advanced for 2D video content, there is limited work on SR algorithms tailored for volumetric videos. To address this gap and the growing need for efficient volumetric video streaming, we have developed VoLUT with a new SR algorithm specifically designed for volumetric content. Our algorithm uniquely harnesses the power of lookup tables (LUTs) to facilitate the efficient and accurate upscaling of low-resolution volumetric data. The use of LUTs enables our algorithm to quickly reference precomputed high-resolution values, thereby significantly reducing the computational complexity and time required for upscaling. We further apply adaptive video bit rate algorithm (ABR) to dynamically determine the downsampling rate according to the network condition and stream the selected video rate to the receiver. Compared to related work, VoLUT is the first to enable high-quality 3D SR on commodity mobile devices at line-rate. Our evaluation shows VoLUT can reduce bandwidth usage by 70% , boost QoE by 36.7% for volumetric video streaming and achieve 3D SR speed-up with no quality compromise.
A First Look at GPT Apps: Landscape and Vulnerability
Feb 23, 2024With the advancement of Large Language Models (LLMs), increasingly sophisticated and powerful GPTs are entering the market. Despite their popularity, the LLM ecosystem still remains unexplored. Additionally, LLMs' susceptibility to attacks raises concerns over safety and plagiarism. Thus, in this work, we conduct a pioneering exploration of GPT stores, aiming to study vulnerabilities and plagiarism within GPT applications. To begin with, we conduct, to our knowledge, the first large-scale monitoring and analysis of two stores, an unofficial GPTStore.AI, and an official OpenAI GPT Store. Then, we propose a TriLevel GPT Reversing (T-GR) strategy for extracting GPT internals. To complete these two tasks efficiently, we develop two automated tools: one for web scraping and another designed for programmatically interacting with GPTs. Our findings reveal a significant enthusiasm among users and developers for GPT interaction and creation, as evidenced by the rapid increase in GPTs and their creators. However, we also uncover a widespread failure to protect GPT internals, with nearly 90% of system prompts easily accessible, leading to considerable plagiarism and duplication among GPTs.