 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Algorithms for Agnostic Pool-based Active Classification
May 13, 2021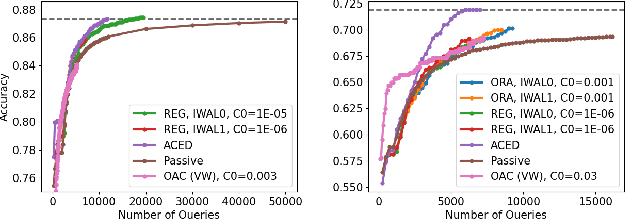

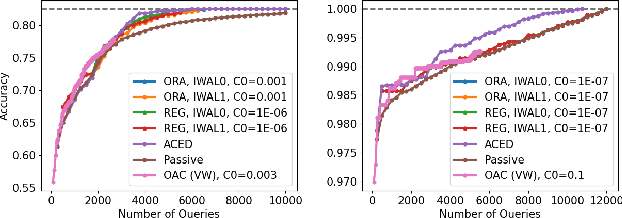
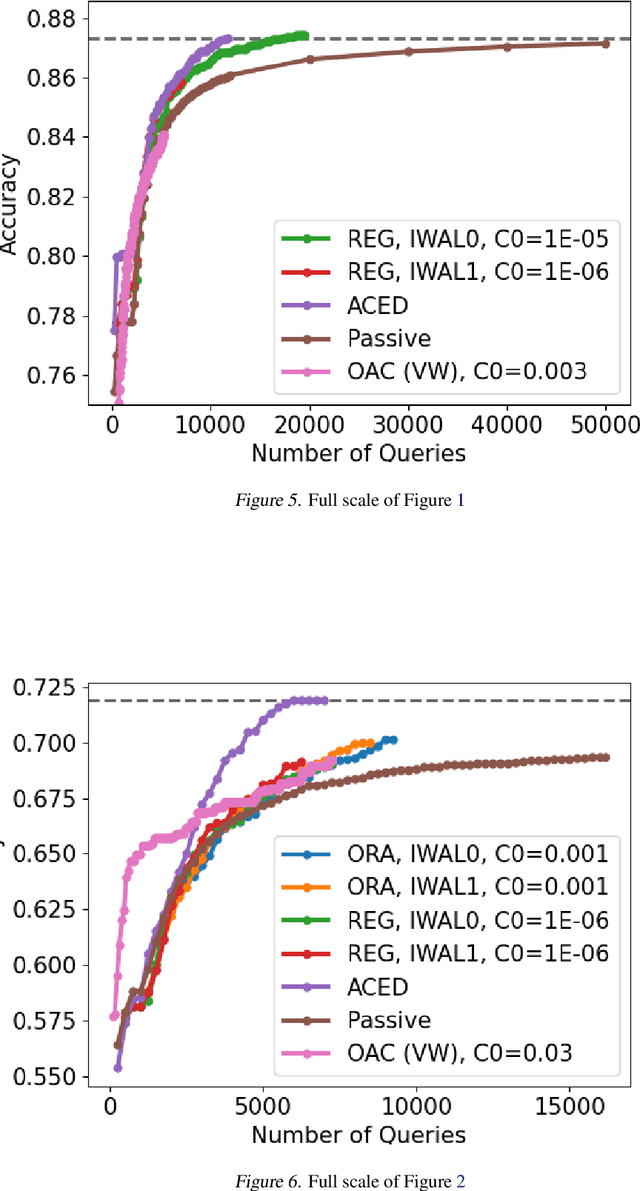
We consider active learning for binary classification in the agnostic pool-based setting. The vast majority of works in active learning in the agnostic setting are inspired by the CAL algorithm where each query is uniformly sampled from the disagreement region of the current version space. The sample complexity of such algorithms is described by a quantity known as the disagreement coefficient which captures both the geometry of the hypothesis space as well as the underlying probability space. To date, the disagreement coefficient has been justified by minimax lower bounds only, leaving the door open for superior instance dependent sample complexities. In this work we propose an algorithm that, in contrast to uniform sampling over the disagreement region, solves an experimental design problem to determine a distribution over examples from which to request labels. We show that the new approach achieves sample complexity bounds that are never worse than the best disagreement coefficient-based bounds, but in specific cases can be dramatically smaller. From a practical perspective, the proposed algorithm requires no hyperparameters to tune (e.g., to control the aggressiveness of sampling), and is computationally efficient by means of assuming access to an empirical risk minimization oracle (without any constraints). Empirically, we demonstrate that our algorithm is superior to state of the art agnostic active learning algorithms on image classification datasets.
High-Dimensional Experimental Design and Kernel Bandits
May 12, 2021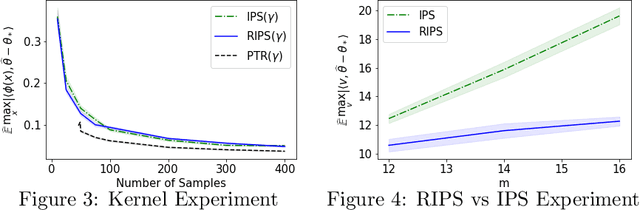
In recent years methods from optimal linear experimental design have been leveraged to obtain state of the art results for linear bandits. A design returned from an objective such as $G$-optimal design is actually a probability distribution over a pool of potential measurement vectors. Consequently, one nuisance of the approach is the task of converting this continuous probability distribution into a discrete assignment of $N$ measurements. While sophisticated rounding techniques have been proposed, in $d$ dimensions they require $N$ to be at least $d$, $d \log(\log(d))$, or $d^2$ based on the sub-optimality of the solution. In this paper we are interested in settings where $N$ may be much less than $d$, such as in experimental design in an RKHS where $d$ may be effectively infinite. In this work, we propose a rounding procedure that frees $N$ of any dependence on the dimension $d$, while achieving nearly the same performance guarantees of existing rounding procedures. We evaluate the procedure against a baseline that projects the problem to a lower dimensional space and performs rounding which requires $N$ to just be at least a notion of the effective dimension. We also leverage our new approach in a new algorithm for kernelized bandits to obtain state of the art results for regret minimization and pure exploration. An advantage of our approach over existing UCB-like approaches is that our kernel bandit algorithms are also robust to model misspecification.
Improved Corruption Robust Algorithms for Episodic Reinforcement Learning
Mar 08, 2021We study episodic reinforcement learning under unknown adversarial corruptions in both the rewards and the transition probabilities of the underlying system. We propose new algorithms which, compared to the existing results in (Lykouris et al., 2020), achieve strictly better regret bounds in terms of total corruptions for the tabular setting. To be specific, firstly, our regret bounds depend on more precise numerical values of total rewards corruptions and transition corruptions, instead of only on the total number of corrupted episodes. Secondly, our regret bounds are the first of their kind in the reinforcement learning setting to have the number of corruptions show up additively with respect to $\min\{\sqrt{T}, \text{PolicyGapComplexity}\}$ rather than multiplicatively. Our results follow from a general algorithmic framework that combines corruption-robust policy elimination meta-algorithms, and plug-in reward-free exploration sub-algorithms. Replacing the meta-algorithm or sub-algorithm may extend the framework to address other corrupted settings with potentially more structure.
Task-Optimal Exploration in Linear Dynamical Systems
Feb 10, 2021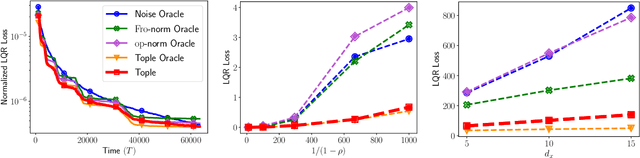
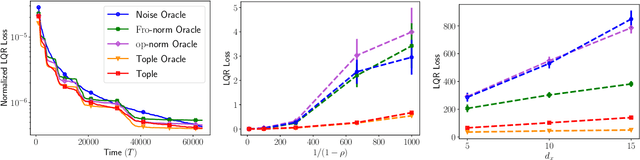
Exploration in unknown environments is a fundamental problem in reinforcement learning and control. In this work, we study task-guided exploration and determine what precisely an agent must learn about their environment in order to complete a particular task. Formally, we study a broad class of decision-making problems in the setting of linear dynamical systems, a class that includes the linear quadratic regulator problem. We provide instance- and task-dependent lower bounds which explicitly quantify the difficulty of completing a task of interest. Motivated by our lower bound, we propose a computationally efficient experiment-design based exploration algorithm. We show that it optimally explores the environment, collecting precisely the information needed to complete the task, and provide finite-time bounds guaranteeing that it achieves the instance- and task-optimal sample complexity, up to constant factors. Through several examples of the LQR problem, we show that performing task-guided exploration provably improves on exploration schemes which do not take into account the task of interest. Along the way, we establish that certainty equivalence decision making is instance- and task-optimal, and obtain the first algorithm for the linear quadratic regulator problem which is instance-optimal. We conclude with several experiments illustrating the effectiveness of our approach in practice.
Leveraging Post Hoc Context for Faster Learning in Bandit Settings with Applications in Robot-Assisted Feeding
Nov 05, 2020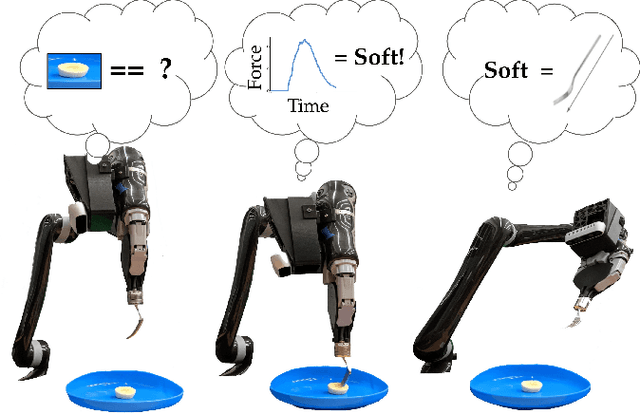
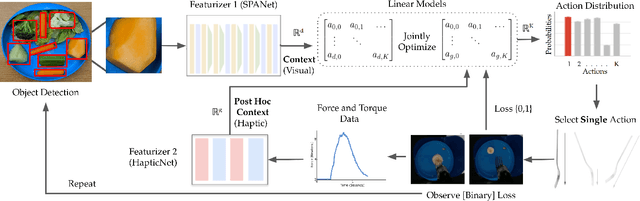


Autonomous robot-assisted feeding requires the ability to acquire a wide variety of food items. However, it is impossible for such a system to be trained on all types of food in existence. Therefore, a key challenge is choosing a manipulation strategy for a previously unseen food item. Previous work showed that the problem can be represented as a linear contextual bandit on visual information. However, food has a wide variety of multi-modal properties relevant to manipulation that can be hard to distinguish visually. Our key insight is that we can leverage the haptic information we collect during manipulation to learn some of these properties and more quickly adapt our visual model to previously unseen food. In general, we propose a modified linear contextual bandit framework augmented with post hoc context observed after action selection to empirically increase learning speed (as measured by cross-validation mean square error) and reduce cumulative regret. Experiments on synthetic data demonstrate that this effect is more pronounced when the dimensionality of the context is large relative to the post hoc context or when the post hoc context model is particularly easy to learn. Finally, we apply this framework to the bite acquisition problem and demonstrate the acquisition of 8 previously unseen types of food with 21% fewer failures across 64 attempts.
Experimental Design for Regret Minimization in Linear Bandits
Nov 01, 2020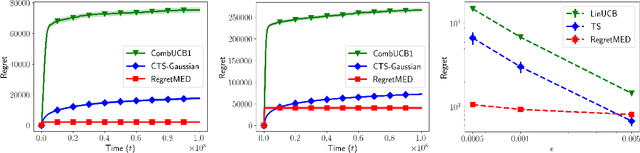

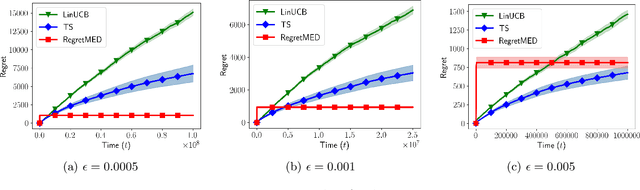
In this paper we propose a novel experimental design-based algorithm to minimize regret in online stochastic linear and combinatorial bandits. While existing literature tends to focus on optimism-based algorithms--which have been shown to be suboptimal in many cases--our approach carefully plans which action to take by balancing the tradeoff between information gain and reward, overcoming the failures of optimism. In addition, we leverage tools from the theory of suprema of empirical processes to obtain regret guarantees that scale with the Gaussian width of the action set, avoiding wasteful union bounds. We provide state-of-the-art finite time regret guarantees and show that our algorithm can be applied in both the bandit and semi-bandit feedback regime. In the combinatorial semi-bandit setting, we show that our algorithm is computationally efficient and relies only on calls to a linear maximization oracle. In addition, we show that with slight modification our algorithm can be used for pure exploration, obtaining state-of-the-art pure exploration guarantees in the semi-bandit setting. Finally, we provide, to the best of our knowledge, the first example where optimism fails in the semi-bandit regime, and show that in this setting our algorithm succeeds.
Learning to Actively Learn: A Robust Approach
Oct 29, 2020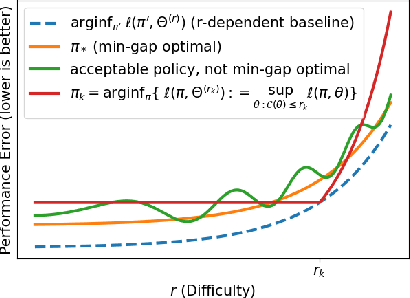
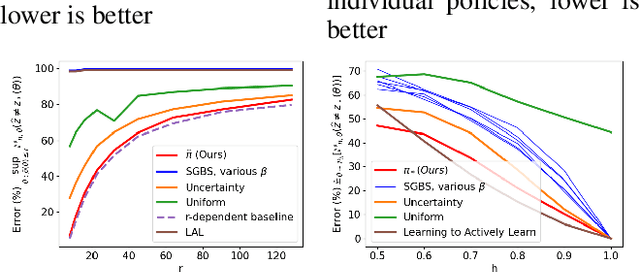
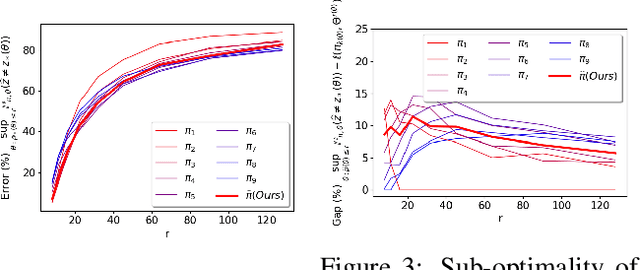
This work proposes a procedure for designing algorithms for specific adaptive data collection tasks like active learning and pure-exploration multi-armed bandits. Unlike the design of traditional adaptive algorithms that rely on concentration of measure and careful analysis to justify the correctness and sample complexity of the procedure, our adaptive algorithm is learned via adversarial training over equivalence classes of problems derived from information theoretic lower bounds. In particular, a single adaptive learning algorithm is learned that competes with the best adaptive algorithm learned for each equivalence class. Our procedure takes as input just the available queries, set of hypotheses, loss function, and total query budget. This is in contrast to existing meta-learning work that learns an adaptive algorithm relative to an explicit, user-defined subset or prior distribution over problems which can be challenging to define and be mismatched to the instance encountered at test time. This work is particularly focused on the regime when the total query budget is very small, such as a few dozen, which is much smaller than those budgets typically considered by theoretically derived algorithms. We perform synthetic experiments to justify the stability and effectiveness of the training procedure, and then evaluate the method on tasks derived from real data including a noisy 20 Questions game and a joke recommendation task.
A New Perspective on Pool-Based Active Classification and False-Discovery Control
Aug 14, 2020In many scientific settings there is a need for adaptive experimental design to guide the process of identifying regions of the search space that contain as many true positives as possible subject to a low rate of false discoveries (i.e. false alarms). Such regions of the search space could differ drastically from a predicted set that minimizes 0/1 error and accurate identification could require very different sampling strategies. Like active learning for binary classification, this experimental design cannot be optimally chosen a priori, but rather the data must be taken sequentially and adaptively. However, unlike classification with 0/1 error, collecting data adaptively to find a set with high true positive rate and low false discovery rate (FDR) is not as well understood. In this paper we provide the first provably sample efficient adaptive algorithm for this problem. Along the way we highlight connections between classification, combinatorial bandits, and FDR control making contributions to each.
An Empirical Process Approach to the Union Bound: Practical Algorithms for Combinatorial and Linear Bandits
Jun 21, 2020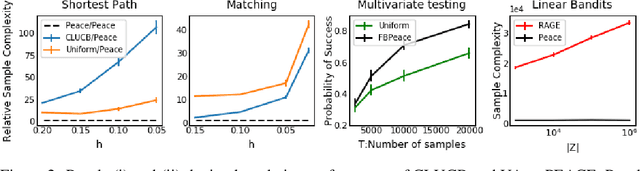
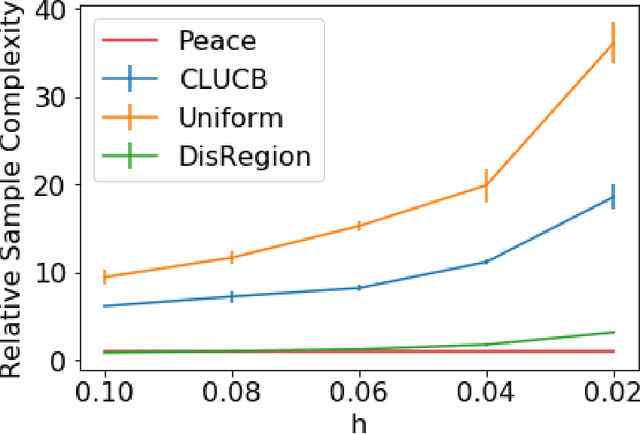
This paper proposes near-optimal algorithms for the pure-exploration linear bandit problem in the fixed confidence and fixed budget settings. Leveraging ideas from the theory of suprema of empirical processes, we provide an algorithm whose sample complexity scales with the geometry of the instance and avoids an explicit union bound over the number of arms. Unlike previous approaches which sample based on minimizing a worst-case variance (e.g. G-optimal design), we define an experimental design objective based on the Gaussian-width of the underlying arm set. We provide a novel lower bound in terms of this objective that highlights its fundamental role in the sample complexity. The sample complexity of our fixed confidence algorithm matches this lower bound, and in addition is computationally efficient for combinatorial classes, e.g. shortest-path, matchings and matroids, where the arm sets can be exponentially large in the dimension. Finally, we propose the first algorithm for linear bandits in the the fixed budget setting. Its guarantee matches our lower bound up to logarithmic factors.
Estimating the number and effect sizes of non-null hypotheses
Feb 17, 2020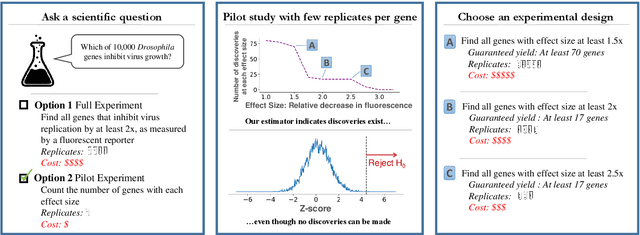
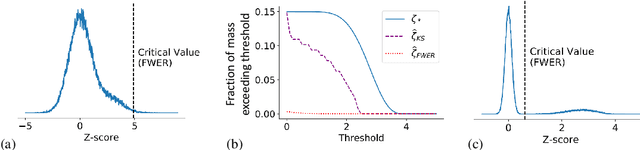
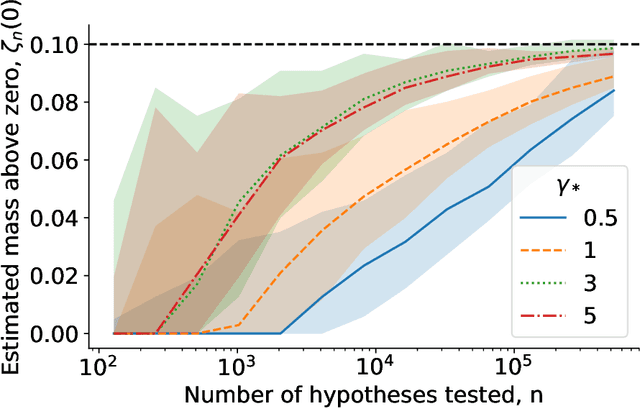
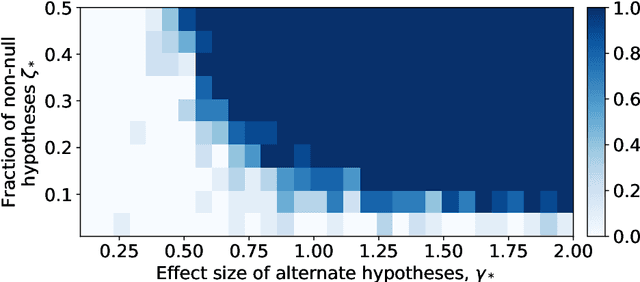
We study the problem of estimating the distribution of effect sizes (the mean of the test statistic under the alternate hypothesis) in a multiple testing setting. Knowing this distribution allows us to calculate the power (type II error) of any experimental design. We show that it is possible to estimate this distribution using an inexpensive pilot experiment, which takes significantly fewer samples than would be required by an experiment that identified the discoveries. Our estimator can be used to guarantee the number of discoveries that will be made using a given experimental design in a future experiment. We prove that this simple and computationally efficient estimator enjoys a number of favorable theoretical properties, and demonstrate its effectiveness on data from a gene knockout experiment on influenza inhibition in Drosophila.