 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaimDB: A Fact Verification Benchmark over Large Structured Data
Jan 21, 2026Despite substantial progress in fact-verification benchmarks, claims grounded in large-scale structured data remain underexplored. In this work, we introduce ClaimDB, the first fact-verification benchmark where the evidence for claims is derived from compositions of millions of records and multiple tables. ClaimDB consists of 80 unique real-life databases covering a wide range of domains, from governance and healthcare to media, education and the natural sciences. At this scale, verification approaches that rely on "reading" the evidence break down, forcing a timely shift toward reasoning in executable programs. We conduct extensive experiments with 30 state-of-the-art proprietary and open-source (below 70B) LLMs and find that none exceed 83% accuracy, with more than half below 55%. Our analysis also reveals that both closed- and open-source models struggle with abstention -- the ability to admit that there is no evidence to decide -- raising doubts about their reliability in high-stakes data analysis. We release the benchmark, code, and the LLM leaderboard at https://claimdb.github.io .
QirK: Question Answering via Intermediate Representation on Knowledge Graphs
Aug 14, 2024

We demonstrate QirK, a system for answering natural language questions on Knowledge Graphs (KG). QirK can answer structurally complex questions that are still beyond the reach of emerging Large Language Models (LLMs). It does so using a unique combination of database technology, LLMs, and semantic search over vector embeddings. The glue for these components is an intermediate representation (IR). The input question is mapped to IR using LLMs, which is then repaired into a valid relational database query with the aid of a semantic search on vector embeddings. This allows a practical synthesis of LLM capabilities and KG reliability. A short video demonstrating QirK is available at https://youtu.be/6c81BLmOZ0U.
CHORUS: Foundation Models for Unified Data Discovery and Exploration
Jun 16, 2023



We explore the application of foundation models to data discovery and exploration tasks. Foundation models are large language models (LLMs) that show promising performance on a range of diverse tasks unrelated to their training. We show that these models are highly applicable to the data discovery and data exploration domain. When carefully used, they have superior capability on three representative tasks: table-class detection, column-type annotation and join-column prediction. On all three tasks, we show that a foundation-model-based approach outperforms the task-specific models and so the state of the art. Further, our approach often surpasses human-expert task performance. This suggests a future direction in which disparate data management tasks can be unified under foundation models.
Computing Rule-Based Explanations by Leveraging Counterfactuals
Oct 31, 2022



Sophisticated machine models are increasingly used for high-stakes decisions in everyday life. There is an urgent need to develop effective explanation techniques for such automated decisions. Rule-Based Explanations have been proposed for high-stake decisions like loan applications, because they increase the users' trust in the decision. However, rule-based explanations are very inefficient to compute, and existing systems sacrifice their quality in order to achieve reasonable performance. We propose a novel approach to compute rule-based explanations, by using a different type of explanation, Counterfactual Explanations, for which several efficient systems have already been developed. We prove a Duality Theorem, showing that rule-based and counterfactual-based explanations are dual to each other, then use this observation to develop an efficient algorithm for computing rule-based explanations, which uses the counterfactual-based explanation as an oracle. We conduct extensive experiments showing that our system computes rule-based explanations of higher quality, and with the same or better performance, than two previous systems, MinSetCover and Anchor.
GeCo: Quality Counterfactual Explanations in Real Time
Jan 05, 2021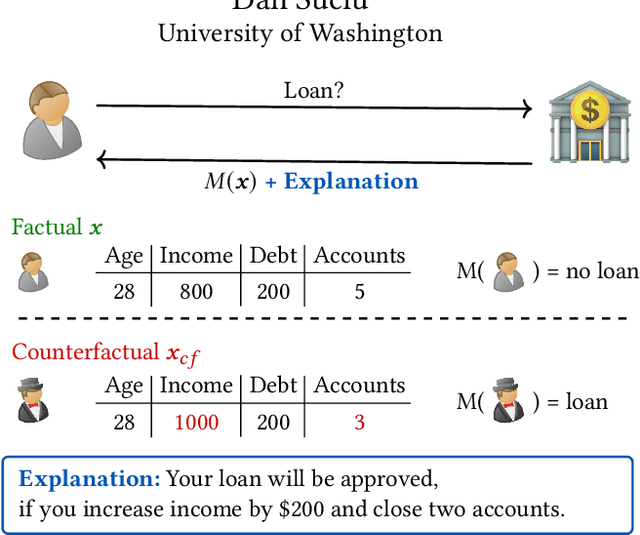
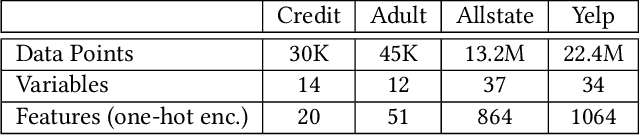

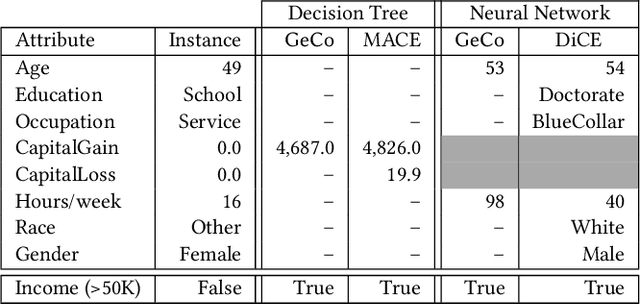
Machine learning is increasingly applied in high-stakes decision making that directly affect people's lives, and this leads to an increased demand for systems to explain their decisions. Explanations often take the form of counterfactuals, which consists of conveying to the end user what she/he needs to change in order to improve the outcome. Computing counterfactual explanations is challenging, because of the inherent tension between a rich semantics of the domain, and the need for real time response. In this paper we present GeCo, the first system that can compute plausible and feasible counterfactual explanations in real time. At its core, GeCo relies on a genetic algorithm, which is customized to favor searching counterfactual explanations with the smallest number of changes. To achieve real-time performance, we introduce two novel optimizations: $\Delta$-representation of candidate counterfactuals, and partial evaluation of the classifier. We compare empirically GeCo against four other systems described in the literature, and show that it is the only system that can achieve both high quality explanations and real time answers.
On the Tractability of SHAP Explanations
Sep 18, 2020SHAP explanations are a popular feature-attribution mechanism for explainable AI. They use game-theoretic notions to measure the influence of individual features on the prediction of a machine learning model. Despite a lot of recent interest from both academia and industry, it is not known whether SHAP explanations of common machine learning models can be computed efficiently. In this paper, we establish the complexity of computing the SHAP explanation in three important settings. First, we consider fully-factorized data distributions, and show that the complexity of computing the SHAP explanation is the same as the complexity of computing the expected value of the model. This fully-factorized setting is often used to simplify the SHAP computation, yet our results show that the computation can be intractable for commonly used models such as logistic regression. Going beyond fully-factorized distributions, we show that computing SHAP explanations is already intractable for a very simple setting: computing SHAP explanations of trivial classifiers over naive Bayes distributions. Finally, we show that even computing SHAP over the empirical distribution is #P-hard.
Causal Relational Learning
Apr 07, 2020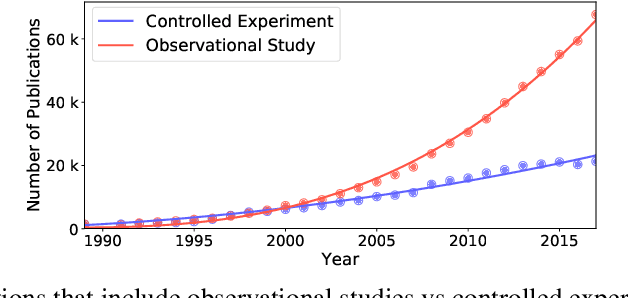



Causal inference is at the heart of empirical research in natural and social sciences and is critical for scientific discovery and informed decision making. The gold standard in causal inference is performing randomized controlled trials; unfortunately these are not always feasible due to ethical, legal, or cost constraints. As an alternative, methodologies for causal inference from observational data have been developed in statistical studies and social sciences. However, existing methods critically rely on restrictive assumptions such as the study population consisting of homogeneous elements that can be represented in a single flat table, where each row is referred to as a unit. In contrast, in many real-world settings, the study domain naturally consists of heterogeneous elements with complex relational structure, where the data is naturally represented in multiple related tables. In this paper, we present a formal framework for causal inference from such relational data. We propose a declarative language called CaRL for capturing causal background knowledge and assumptions and specifying causal queries using simple Datalog-like rules.CaRL provides a foundation for inferring causality and reasoning about the effect of complex interventions in relational domains. We present an extensive experimental evaluation on real relational data to illustrate the applicability of CaRL in social sciences and healthcare.
Causality-based Explanation of Classification Outcomes
Mar 15, 2020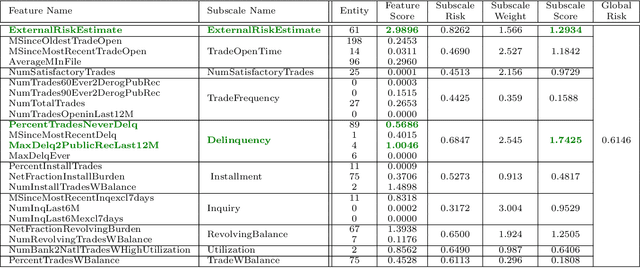
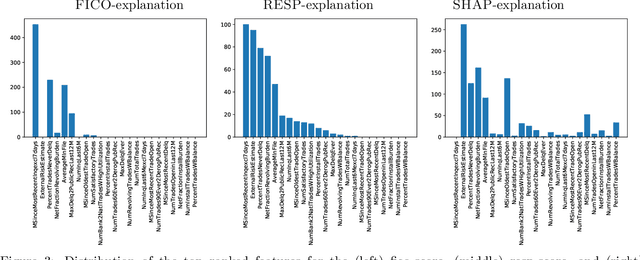
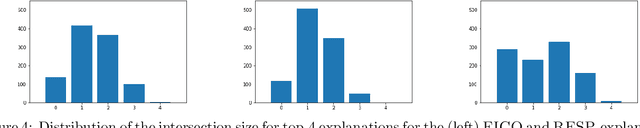
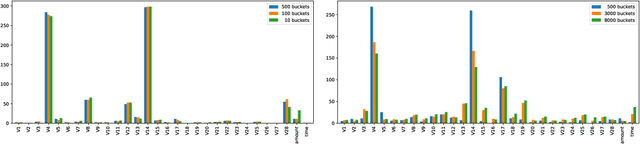
We propose a simple definition of an explanation for the outcome of a classifier based on concepts from causality. We compare it with previously proposed notions of explanation, and study their complexity. We conduct an experimental evaluation with two real datasets from the financial domain.
Mosaic: A Sample-Based Database System for Open World Query Processing
Jan 10, 2020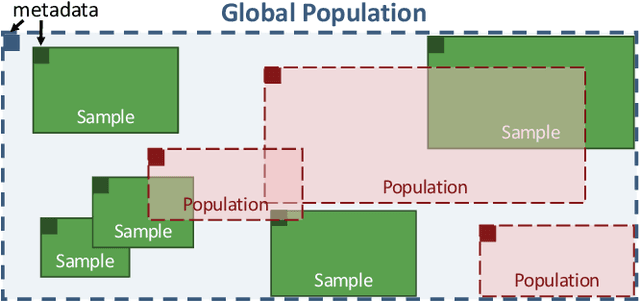
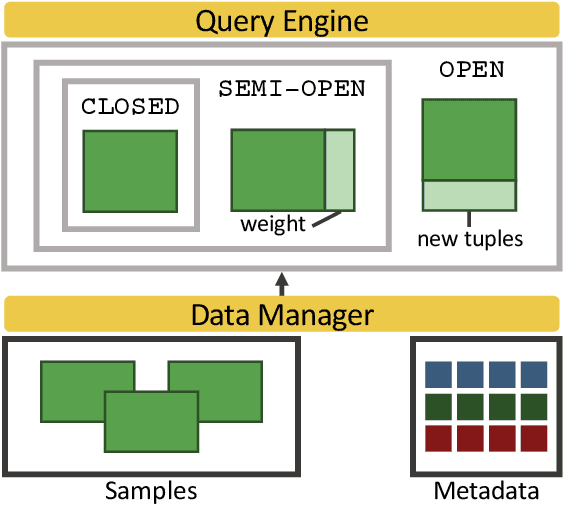

Data scientists have relied on samples to analyze populations of interest for decades. Recently, with the increase in the number of public data repositories, sample data has become easier to access. It has not, however, become easier to analyze. This sample data is arbitrarily biased with an unknown sampling probability, meaning data scientists must manually debias the sample with custom techniques to avoid inaccurate results. In this vision paper, we propose Mosaic, a database system that treats samples as first-class citizens and allows users to ask questions over populations represented by these samples. Answering queries over biased samples is non-trivial as there is no existing, standard technique to answer population queries when the sampling probability is unknown. In this paper, we show how our envisioned system solves this problem by having a unique sample-based data model with extensions to the SQL language. We propose how to perform population query answering using biased samples and give preliminary results for one of our novel query answering techniques.
Data Management for Causal Algorithmic Fairness
Oct 01, 2019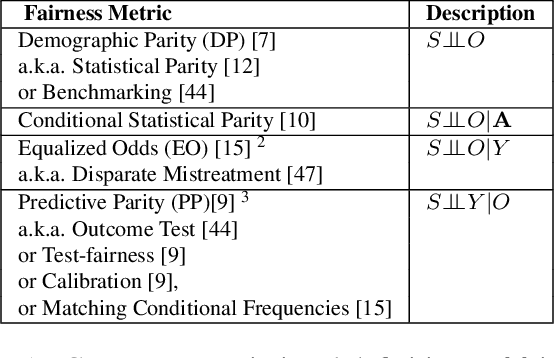
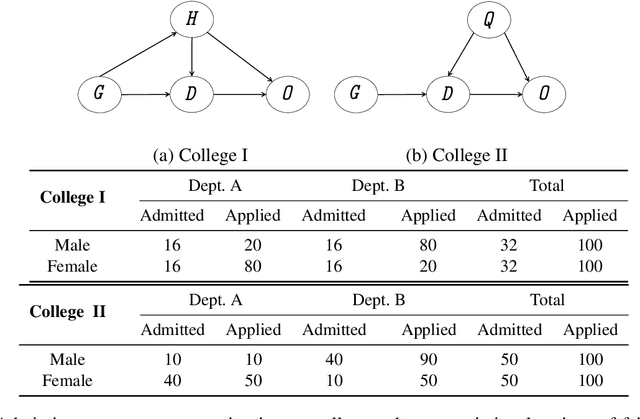
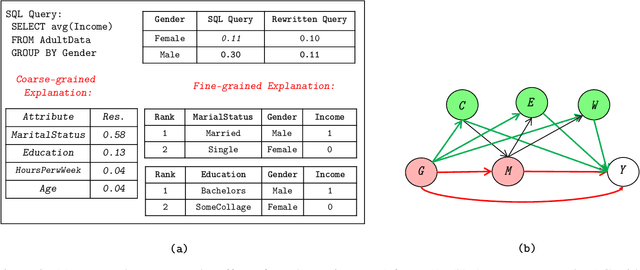
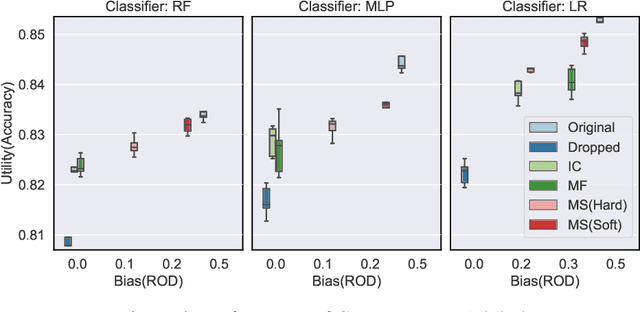
Fairness is increasingly recognized as a critical component of machine learning systems. However, it is the underlying data on which these systems are trained that often reflects discrimination, suggesting a data management problem. In this paper, we first make a distinction between associational and causal definitions of fairness in the literature and argue that the concept of fairness requires causal reasoning. We then review existing works and identify future opportunities for applying data management techniques to causal algorithmic fairness.