 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMosaic: A Sample-Based Database System for Open World Query Processing
Paper and Code
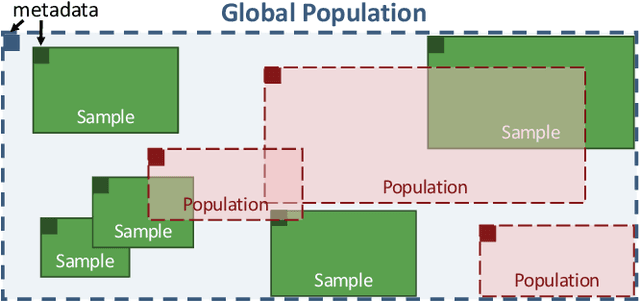
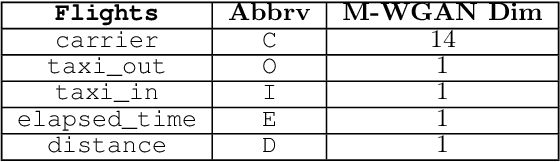
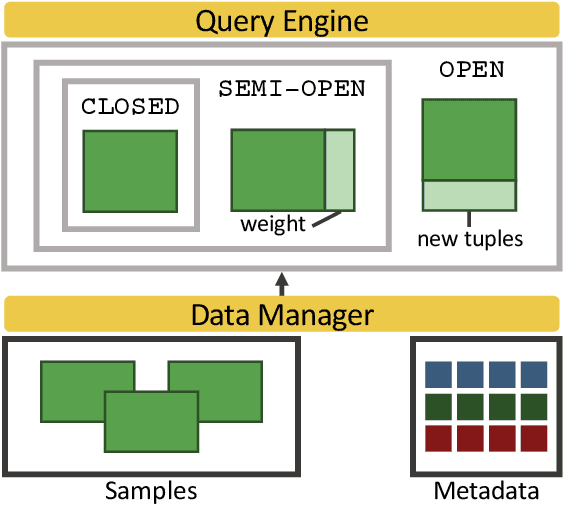

Data scientists have relied on samples to analyze populations of interest for decades. Recently, with the increase in the number of public data repositories, sample data has become easier to access. It has not, however, become easier to analyze. This sample data is arbitrarily biased with an unknown sampling probability, meaning data scientists must manually debias the sample with custom techniques to avoid inaccurate results. In this vision paper, we propose Mosaic, a database system that treats samples as first-class citizens and allows users to ask questions over populations represented by these samples. Answering queries over biased samples is non-trivial as there is no existing, standard technique to answer population queries when the sampling probability is unknown. In this paper, we show how our envisioned system solves this problem by having a unique sample-based data model with extensions to the SQL language. We propose how to perform population query answering using biased samples and give preliminary results for one of our novel query answering techniques.