 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Reuse in Pipeline-Aware Hyperparameter Tuning
Paper and Code
Mar 12, 2019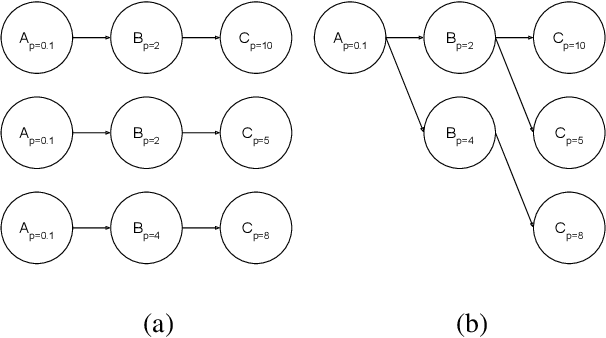
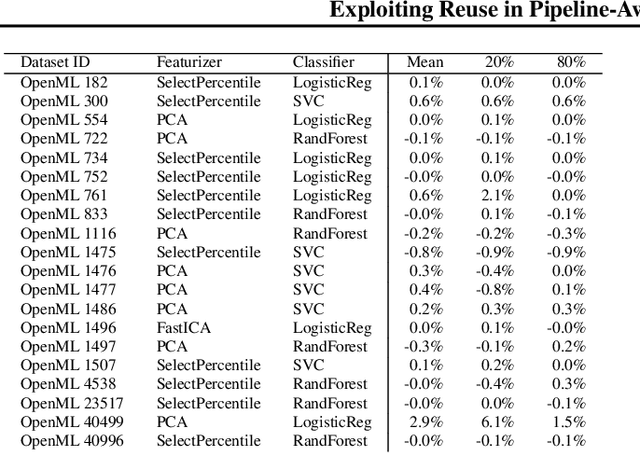
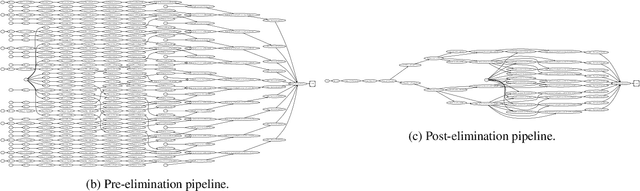
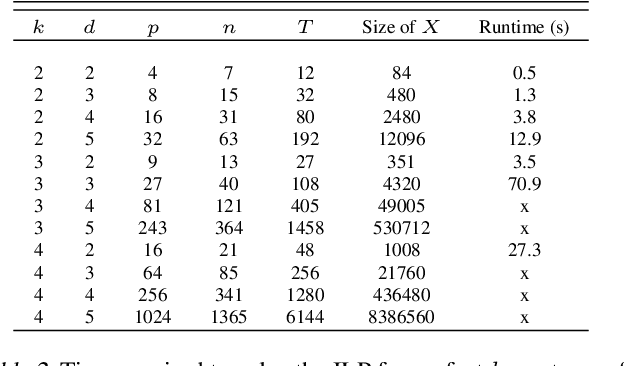
Hyperparameter tuning of multi-stage pipelines introduces a significant computational burden. Motivated by the observation that work can be reused across pipelines if the intermediate computations are the same, we propose a pipeline-aware approach to hyperparameter tuning. Our approach optimizes both the design and execution of pipelines to maximize reuse. We design pipelines amenable for reuse by (i) introducing a novel hybrid hyperparameter tuning method called gridded random search, and (ii) reducing the average training time in pipelines by adapting early-stopping hyperparameter tuning approaches. We then realize the potential for reuse during execution by introducing a novel caching problem for ML workloads which we pose as a mixed integer linear program (ILP), and subsequently evaluating various caching heuristics relative to the optimal solution of the ILP. We conduct experiments on simulated and real-world machine learning pipelines to show that a pipeline-aware approach to hyperparameter tuning can offer over an order-of-magnitude speedup over independently evaluating pipeline configurations.