 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Narrow Unlearning to Emergent Misalignment: Causes, Consequences, and Containment in LLMs
Nov 18, 2025



Recent work has shown that fine-tuning on insecure code data can trigger an emergent misalignment (EMA) phenomenon, where models generate malicious responses even to prompts unrelated to the original insecure code-writing task. Such cross-domain generalization of harmful behavior underscores the need for a deeper understanding of the algorithms, tasks, and datasets that induce emergent misalignment. In this work, we extend this study by demonstrating that emergent misalignment can also arise from narrow refusal unlearning in specific domains. We perform refusal unlearning on Cybersecurity and Safety concept, and evaluate EMA by monitoring refusal scores across seven responsible AI (RAI) domains, Cybersecurity, Safety, Toxicity, Bias, Sensitive Content, Medical/Legal, and Privacy. Our work shows that narrow domain unlearning can yield compliance responses for the targeted concept, however, it may also propagate EMA to unrelated domains. Among the two intervened concepts, Cybersecurity and Safety, we find that the safety concept can have larger EMA impact, i.e, causing lower refusal scores, across other unrelated domains such as bias. We observe this effect consistently across two model families, Mistral-7b-0.3v, and Qwen-7b-2.5. Further, we show that refusal unlearning augmented with cross-entropy loss function on a small set of retain data from the affected domains can largely, if not fully, restore alignment across the impacted domains while having lower refusal rate on the concept we perform unlearning on. To investigate the underlying causes of EMA, we analyze concept entanglements at the representation level via concept vectors. Our analysis reveals that concepts with higher representation similarity in earlier layers are more susceptible to EMA after intervention when the refusal stream is altered through targeted refusal unlearning.
Reinforcing Stereotypes of Anger: Emotion AI on African American Vernacular English
Nov 13, 2025



Automated emotion detection is widely used in applications ranging from well-being monitoring to high-stakes domains like mental health and hiring. However, models often rely on annotations that reflect dominant cultural norms, limiting model ability to recognize emotional expression in dialects often excluded from training data distributions, such as African American Vernacular English (AAVE). This study examines emotion recognition model performance on AAVE compared to General American English (GAE). We analyze 2.7 million tweets geo-tagged within Los Angeles. Texts are scored for strength of AAVE using computational approximations of dialect features. Annotations of emotion presence and intensity are collected on a dataset of 875 tweets with both high and low AAVE densities. To assess model accuracy on a task as subjective as emotion perception, we calculate community-informed "silver" labels where AAVE-dense tweets are labeled by African American, AAVE-fluent (ingroup) annotators. On our labeled sample, GPT and BERT-based models exhibit false positive prediction rates of anger on AAVE more than double than on GAE. SpanEmo, a popular text-based emotion model, increases false positive rates of anger from 25 percent on GAE to 60 percent on AAVE. Additionally, a series of linear regressions reveals that models and non-ingroup annotations are significantly more correlated with profanity-based AAVE features than ingroup annotations. Linking Census tract demographics, we observe that neighborhoods with higher proportions of African American residents are associated with higher predictions of anger (Pearson's correlation r = 0.27) and lower joy (r = -0.10). These results find an emergent safety issue of emotion AI reinforcing racial stereotypes through biased emotion classification. We emphasize the need for culturally and dialect-informed affective computing systems.
DialectGen: Benchmarking and Improving Dialect Robustness in Multimodal Generation
Oct 16, 2025

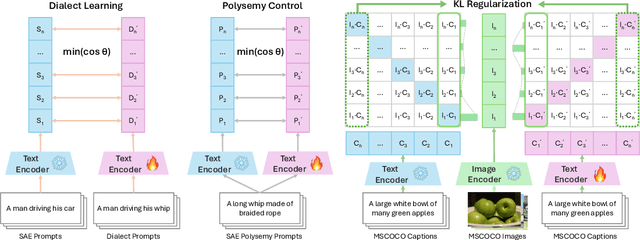

Contact languages like English exhibit rich regional variations in the form of dialects, which are often used by dialect speakers interacting with generative models. However, can multimodal generative models effectively produce content given dialectal textual input? In this work, we study this question by constructing a new large-scale benchmark spanning six common English dialects. We work with dialect speakers to collect and verify over 4200 unique prompts and evaluate on 17 image and video generative models. Our automatic and human evaluation results show that current state-of-the-art multimodal generative models exhibit 32.26% to 48.17% performance degradation when a single dialect word is used in the prompt. Common mitigation methods such as fine-tuning and prompt rewriting can only improve dialect performance by small margins (< 7%), while potentially incurring significant performance degradation in Standard American English (SAE). To this end, we design a general encoder-based mitigation strategy for multimodal generative models. Our method teaches the model to recognize new dialect features while preserving SAE performance. Experiments on models such as Stable Diffusion 1.5 show that our method is able to simultaneously raise performance on five dialects to be on par with SAE (+34.4%), while incurring near zero cost to SAE performance.
LLMs as Scalable, General-Purpose Simulators For Evolving Digital Agent Training
Oct 16, 2025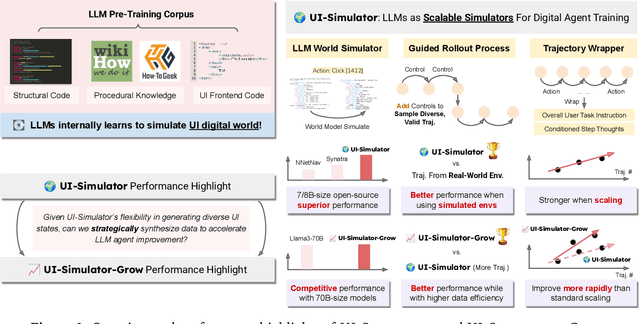
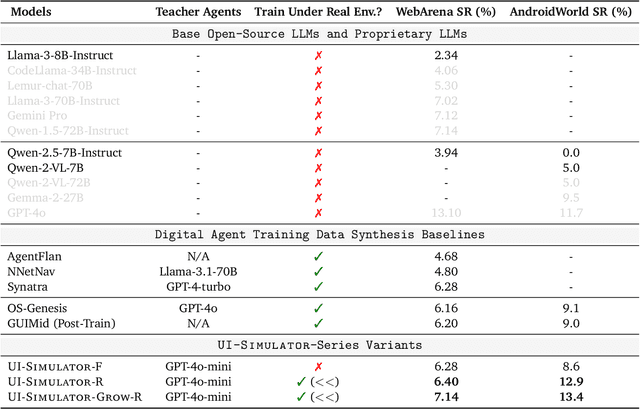

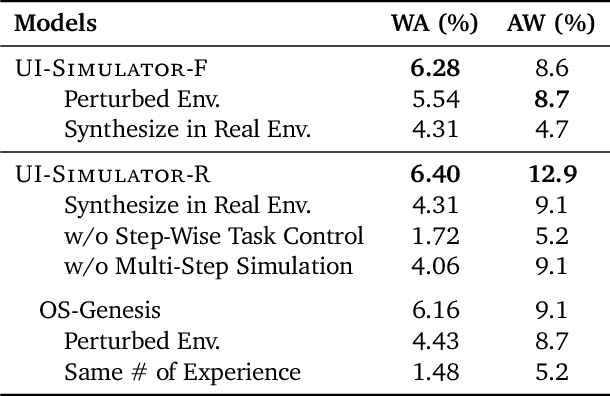
Digital agents require diverse, large-scale UI trajectories to generalize across real-world tasks, yet collecting such data is prohibitively expensive in both human annotation, infra and engineering perspectives. To this end, we introduce $\textbf{UI-Simulator}$, a scalable paradigm that generates structured UI states and transitions to synthesize training trajectories at scale. Our paradigm integrates a digital world simulator for diverse UI states, a guided rollout process for coherent exploration, and a trajectory wrapper that produces high-quality and diverse trajectories for agent training. We further propose $\textbf{UI-Simulator-Grow}$, a targeted scaling strategy that enables more rapid and data-efficient scaling by prioritizing high-impact tasks and synthesizes informative trajectory variants. Experiments on WebArena and AndroidWorld show that UI-Simulator rivals or surpasses open-source agents trained on real UIs with significantly better robustness, despite using weaker teacher models. Moreover, UI-Simulator-Grow matches the performance of Llama-3-70B-Instruct using only Llama-3-8B-Instruct as the base model, highlighting the potential of targeted synthesis scaling paradigm to continuously and efficiently enhance the digital agents.
Full-Duplex-Bench-v2: A Multi-Turn Evaluation Framework for Duplex Dialogue Systems with an Automated Examiner
Oct 09, 2025While full-duplex speech agents enable natural, low-latency interaction by speaking and listening simultaneously, their consistency and task performance in multi-turn settings remain underexplored. We introduce Full-Duplex-Bench-v2 (FDB-v2), a streaming framework that integrates with an automated examiner that enforces staged goals under two pacing setups (Fast vs. Slow). FDB-v2 covers four task families: daily, correction, entity tracking, and safety. We report turn-taking fluency, multi-turn instruction following, and task-specific competence. The framework is extensible, supporting both commercial APIs and open source models. When we test full-duplex systems with FDB-v2, they often get confused when people talk at the same time, struggle to handle corrections smoothly, and sometimes lose track of who or what is being talked about. Through an open-sourced, standardized streaming protocol and a task set, FDB-v2 makes it easy to extend to new task families, allowing the community to tailor and accelerate evaluation of multi-turn full-duplex systems.
Dynamic Generation of Multi-LLM Agents Communication Topologies with Graph Diffusion Models
Oct 09, 2025The efficiency of multi-agent systems driven by large language models (LLMs) largely hinges on their communication topology. However, designing an optimal topology is a non-trivial challenge, as it requires balancing competing objectives such as task performance, communication cost, and robustness. Existing frameworks often rely on static or hand-crafted topologies, which inherently fail to adapt to diverse task requirements, leading to either excessive token consumption for simple problems or performance bottlenecks for complex ones. To address this challenge, we introduce a novel generative framework called \textit{Guided Topology Diffusion (GTD)}. Inspired by conditional discrete graph diffusion models, GTD formulates topology synthesis as an iterative construction process. At each step, the generation is steered by a lightweight proxy model that predicts multi-objective rewards (e.g., accuracy, utility, cost), enabling real-time, gradient-free optimization towards task-adaptive topologies. This iterative, guided synthesis process distinguishes GTD from single-step generative frameworks, enabling it to better navigate complex design trade-offs. We validated GTD across multiple benchmarks, and experiments show that this framework can generate highly task-adaptive, sparse, and efficient communication topologies, significantly outperforming existing methods in LLM agent collaboration.
ContextNav: Towards Agentic Multimodal In-Context Learning
Oct 06, 2025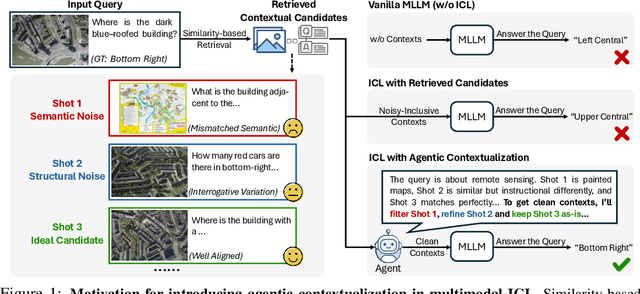
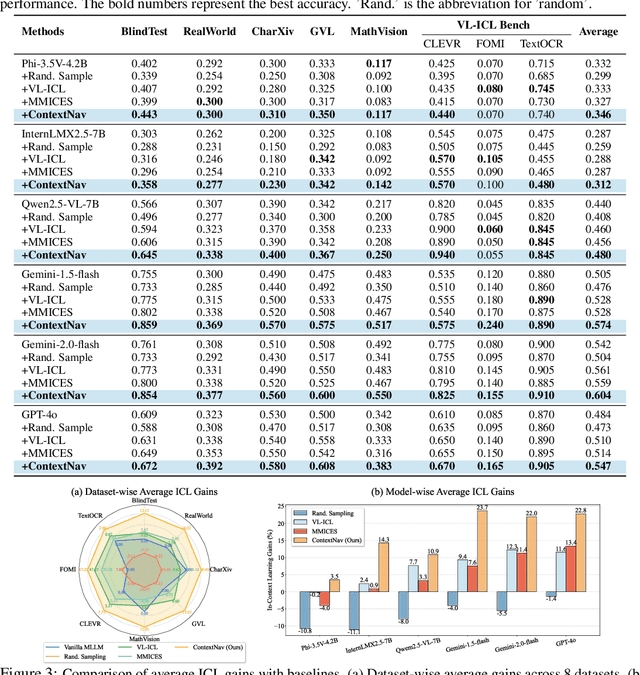
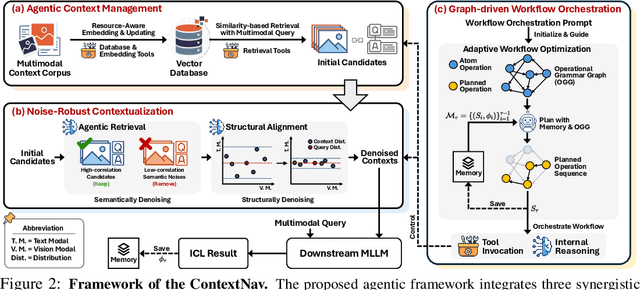
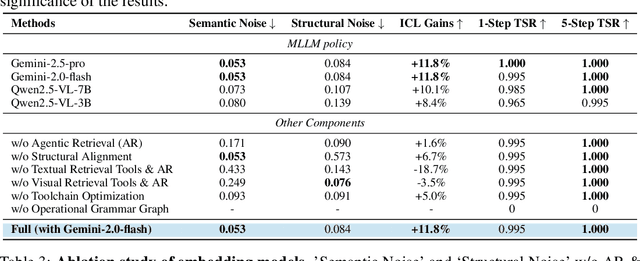
Recent advances demonstrate that multimodal large language models (MLLMs) exhibit strong multimodal in-context learning (ICL) capabilities, enabling them to adapt to novel vision-language tasks from a few contextual examples. However, existing ICL approaches face challenges in reconciling scalability with robustness across diverse tasks and noisy contextual examples: manually selecting examples produces clean contexts but is labor-intensive and task-specific, while similarity-based retrieval improves scalability but could introduce irrelevant or structurally inconsistent samples that degrade ICL performance. To address these limitations, we propose ContextNav, the first agentic framework that integrates the scalability of automated retrieval with the quality and adaptiveness of human-like curation, enabling noise-robust and dynamically optimized contextualization for multimodal ICL. ContextNav unifies context management and noise-robust contextualization within a closed-loop workflow driven by graph-based orchestration. Specifically, it builds a resource-aware multimodal embedding pipeline, maintains a retrievable vector database, and applies agentic retrieval and structural alignment to construct noise-resilient contexts. An Operational Grammar Graph (OGG) further supports adaptive workflow planning and optimization, enabling the agent to refine its operational strategies based on downstream ICL feedback. Experimental results demonstrate that ContextNav achieves state-of-the-art performance across various datasets, underscoring the promise of agentic workflows for advancing scalable and robust contextualization in multimodal ICL.
Customize Multi-modal RAI Guardrails with Precedent-based predictions
Jul 28, 2025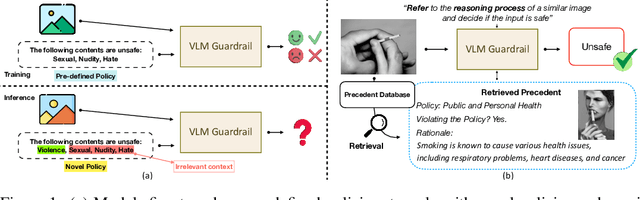
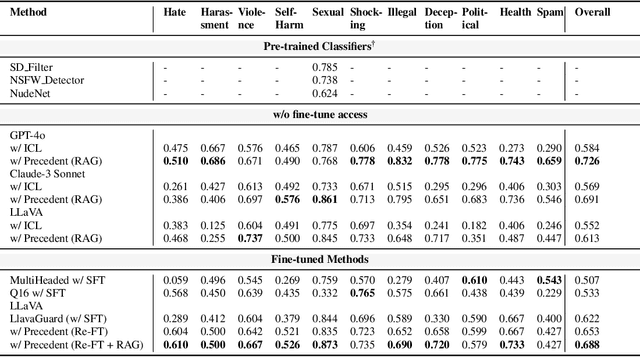
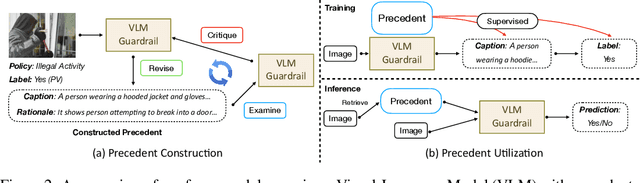
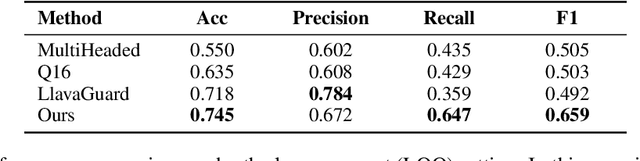
A multi-modal guardrail must effectively filter image content based on user-defined policies, identifying material that may be hateful, reinforce harmful stereotypes, contain explicit material, or spread misinformation. Deploying such guardrails in real-world applications, however, poses significant challenges. Users often require varied and highly customizable policies and typically cannot provide abundant examples for each custom policy. Consequently, an ideal guardrail should be scalable to the multiple policies and adaptable to evolving user standards with minimal retraining. Existing fine-tuning methods typically condition predictions on pre-defined policies, restricting their generalizability to new policies or necessitating extensive retraining to adapt. Conversely, training-free methods struggle with limited context lengths, making it difficult to incorporate all the policies comprehensively. To overcome these limitations, we propose to condition model's judgment on "precedents", which are the reasoning processes of prior data points similar to the given input. By leveraging precedents instead of fixed policies, our approach greatly enhances the flexibility and adaptability of the guardrail. In this paper, we introduce a critique-revise mechanism for collecting high-quality precedents and two strategies that utilize precedents for robust prediction. Experimental results demonstrate that our approach outperforms previous methods across both few-shot and full-dataset scenarios and exhibits superior generalization to novel policies.
DeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025



We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
Embodied Web Agents: Bridging Physical-Digital Realms for Integrated Agent Intelligence
Jun 18, 2025AI agents today are mostly siloed - they either retrieve and reason over vast amount of digital information and knowledge obtained online; or interact with the physical world through embodied perception, planning and action - but rarely both. This separation limits their ability to solve tasks that require integrated physical and digital intelligence, such as cooking from online recipes, navigating with dynamic map data, or interpreting real-world landmarks using web knowledge. We introduce Embodied Web Agents, a novel paradigm for AI agents that fluidly bridge embodiment and web-scale reasoning. To operationalize this concept, we first develop the Embodied Web Agents task environments, a unified simulation platform that tightly integrates realistic 3D indoor and outdoor environments with functional web interfaces. Building upon this platform, we construct and release the Embodied Web Agents Benchmark, which encompasses a diverse suite of tasks including cooking, navigation, shopping, tourism, and geolocation - all requiring coordinated reasoning across physical and digital realms for systematic assessment of cross-domain intelligence. Experimental results reveal significant performance gaps between state-of-the-art AI systems and human capabilities, establishing both challenges and opportunities at the intersection of embodied cognition and web-scale knowledge access. All datasets, codes and websites are publicly available at our project page https://embodied-web-agent.github.io/.