 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomize Multi-modal RAI Guardrails with Precedent-based predictions
Paper and Code
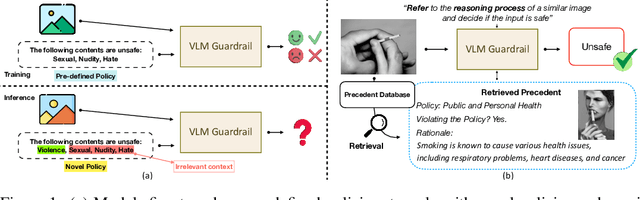
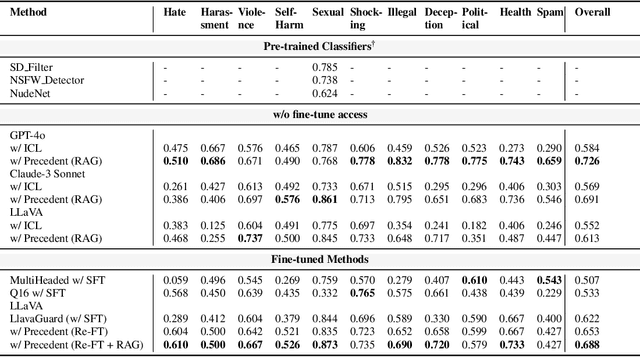
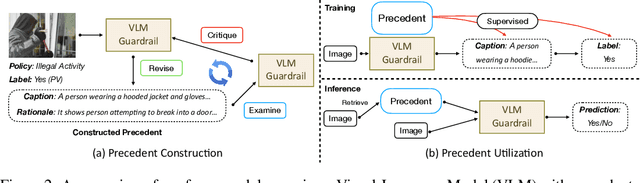
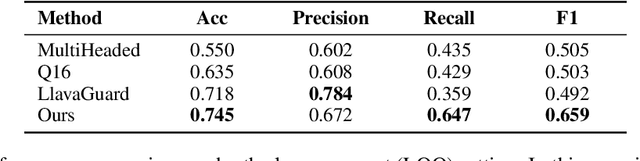
A multi-modal guardrail must effectively filter image content based on user-defined policies, identifying material that may be hateful, reinforce harmful stereotypes, contain explicit material, or spread misinformation. Deploying such guardrails in real-world applications, however, poses significant challenges. Users often require varied and highly customizable policies and typically cannot provide abundant examples for each custom policy. Consequently, an ideal guardrail should be scalable to the multiple policies and adaptable to evolving user standards with minimal retraining. Existing fine-tuning methods typically condition predictions on pre-defined policies, restricting their generalizability to new policies or necessitating extensive retraining to adapt. Conversely, training-free methods struggle with limited context lengths, making it difficult to incorporate all the policies comprehensively. To overcome these limitations, we propose to condition model's judgment on "precedents", which are the reasoning processes of prior data points similar to the given input. By leveraging precedents instead of fixed policies, our approach greatly enhances the flexibility and adaptability of the guardrail. In this paper, we introduce a critique-revise mechanism for collecting high-quality precedents and two strategies that utilize precedents for robust prediction. Experimental results demonstrate that our approach outperforms previous methods across both few-shot and full-dataset scenarios and exhibits superior generalization to novel policies.