 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot and Pseudo-Label Guided Speech Quality Evaluation with Large Language Models
Apr 15, 2026In this paper, we introduce GatherMOS, a novel framework that leverages large language models (LLM) as meta-evaluators to aggregate diverse signals into quality predictions. GatherMOS integrates lightweight acoustic descriptors with pseudo-labels from DNSMOS and VQScore, enabling the LLM to reason over heterogeneous inputs and infer perceptual mean opinion scores (MOS). We further explore both zero-shot and few-shot in-context learning setups, showing that zero-shot GatherMOS maintains stable performance across diverse conditions, while few-shot guidance yields large gains when support samples match the test conditions. Experiments on the VoiceBank-DEMAND dataset demonstrate that GatherMOS consistently outperforms DNSMOS, VQScore, naive score averaging, and even learning-based models such as CNN-BLSTM and MOS-SSL when trained under limited labeled-data conditions. These results highlight the potential of LLM-based aggregation as a practical strategy for non-intrusive speech quality evaluation.
How Auditory Knowledge in LLM Backbones Shapes Audio Language Models: A Holistic Evaluation
Mar 19, 2026Large language models (LLMs) have been widely used as knowledge backbones of Large Audio Language Models (LALMs), yet how much auditory knowledge they encode through text-only pre-training and how this affects downstream performance remains unclear. We study this gap by comparing different LLMs under two text-only and one audio-grounded setting: (1) direct probing on AKB-2000, a curated benchmark testing the breadth and depth of auditory knowledge; (2) cascade evaluation, where LLMs reason over text descriptions from an audio captioner; and (3) audio-grounded evaluation, where each LLM is fine-tuned into a Large Audio Language Model (LALM) with an audio encoder. Our findings reveal that auditory knowledge varies substantially across families, and text-only results are strongly correlated with audio performance. Our work provides empirical grounding for a comprehensive understanding of LLMs in audio research.
Test-Time Scaling Strategies for Generative Retrieval in Multimodal Conversational Recommendations
Aug 25, 2025



The rapid evolution of e-commerce has exposed the limitations of traditional product retrieval systems in managing complex, multi-turn user interactions. Recent advances in multimodal generative retrieval -- particularly those leveraging multimodal large language models (MLLMs) as retrievers -- have shown promise. However, most existing methods are tailored to single-turn scenarios and struggle to model the evolving intent and iterative nature of multi-turn dialogues when applied naively. Concurrently, test-time scaling has emerged as a powerful paradigm for improving large language model (LLM) performance through iterative inference-time refinement. Yet, its effectiveness typically relies on two conditions: (1) a well-defined problem space (e.g., mathematical reasoning), and (2) the model's ability to self-correct -- conditions that are rarely met in conversational product search. In this setting, user queries are often ambiguous and evolving, and MLLMs alone have difficulty grounding responses in a fixed product corpus. Motivated by these challenges, we propose a novel framework that introduces test-time scaling into conversational multimodal product retrieval. Our approach builds on a generative retriever, further augmented with a test-time reranking (TTR) mechanism that improves retrieval accuracy and better aligns results with evolving user intent throughout the dialogue. Experiments across multiple benchmarks show consistent improvements, with average gains of 14.5 points in MRR and 10.6 points in nDCG@1.
DeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025



We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
Universal Speech Enhancement with Regression and Generative Mamba
May 27, 2025



The Interspeech 2025 URGENT Challenge aimed to advance universal, robust, and generalizable speech enhancement by unifying speech enhancement tasks across a wide variety of conditions, including seven different distortion types and five languages. We present Universal Speech Enhancement Mamba (USEMamba), a state-space speech enhancement model designed to handle long-range sequence modeling, time-frequency structured processing, and sampling frequency-independent feature extraction. Our approach primarily relies on regression-based modeling, which performs well across most distortions. However, for packet loss and bandwidth extension, where missing content must be inferred, a generative variant of the proposed USEMamba proves more effective. Despite being trained on only a subset of the full training data, USEMamba achieved 2nd place in Track 1 during the blind test phase, demonstrating strong generalization across diverse conditions.
Linguistic Knowledge Transfer Learning for Speech Enhancement
Mar 10, 2025Linguistic knowledge plays a crucial role in spoken language comprehension. It provides essential semantic and syntactic context for speech perception in noisy environments. However, most speech enhancement (SE) methods predominantly rely on acoustic features to learn the mapping relationship between noisy and clean speech, with limited exploration of linguistic integration. While text-informed SE approaches have been investigated, they often require explicit speech-text alignment or externally provided textual data, constraining their practicality in real-world scenarios. Additionally, using text as input poses challenges in aligning linguistic and acoustic representations due to their inherent differences. In this study, we propose the Cross-Modality Knowledge Transfer (CMKT) learning framework, which leverages pre-trained large language models (LLMs) to infuse linguistic knowledge into SE models without requiring text input or LLMs during inference. Furthermore, we introduce a misalignment strategy to improve knowledge transfer. This strategy applies controlled temporal shifts, encouraging the model to learn more robust representations. Experimental evaluations demonstrate that CMKT consistently outperforms baseline models across various SE architectures and LLM embeddings, highlighting its adaptability to different configurations. Additionally, results on Mandarin and English datasets confirm its effectiveness across diverse linguistic conditions, further validating its robustness. Moreover, CMKT remains effective even in scenarios without textual data, underscoring its practicality for real-world applications. By bridging the gap between linguistic and acoustic modalities, CMKT offers a scalable and innovative solution for integrating linguistic knowledge into SE models, leading to substantial improvements in both intelligibility and enhancement performance.
Detecting the Undetectable: Assessing the Efficacy of Current Spoof Detection Methods Against Seamless Speech Edits
Jan 07, 2025



Neural speech editing advancements have raised concerns about their misuse in spoofing attacks. Traditional partially edited speech corpora primarily focus on cut-and-paste edits, which, while maintaining speaker consistency, often introduce detectable discontinuities. Recent methods, like A\textsuperscript{3}T and Voicebox, improve transitions by leveraging contextual information. To foster spoofing detection research, we introduce the Speech INfilling Edit (SINE) dataset, created with Voicebox. We detailed the process of re-implementing Voicebox training and dataset creation. Subjective evaluations confirm that speech edited using this novel technique is more challenging to detect than conventional cut-and-paste methods. Despite human difficulty, experimental results demonstrate that self-supervised-based detectors can achieve remarkable performance in detection, localization, and generalization across different edit methods. The dataset and related models will be made publicly available.
NeKo: Toward Post Recognition Generative Correction Large Language Models with Task-Oriented Experts
Nov 08, 2024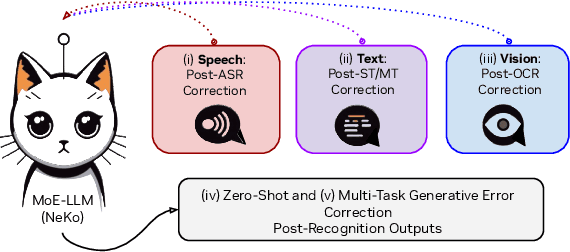
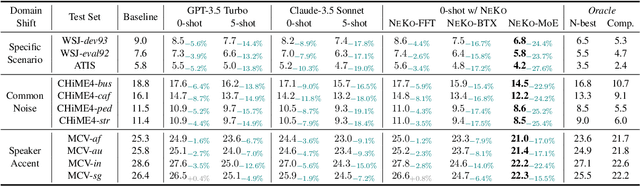
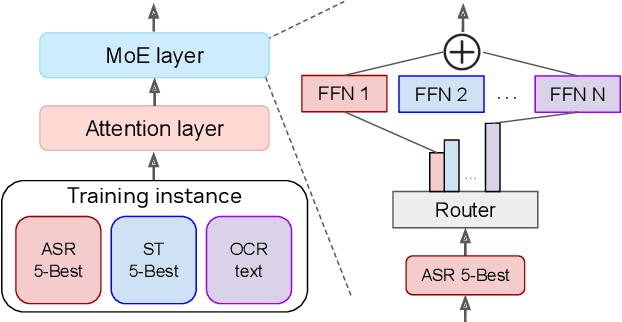
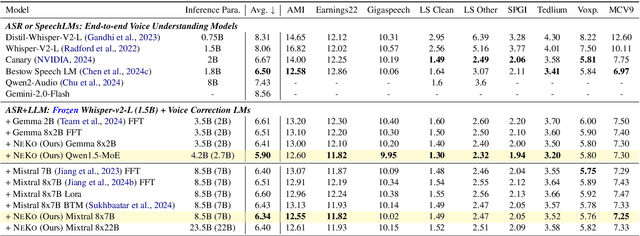
Construction of a general-purpose post-recognition error corrector poses a crucial question: how can we most effectively train a model on a large mixture of domain datasets? The answer would lie in learning dataset-specific features and digesting their knowledge in a single model. Previous methods achieve this by having separate correction language models, resulting in a significant increase in parameters. In this work, we present Mixture-of-Experts as a solution, highlighting that MoEs are much more than a scalability tool. We propose a Multi-Task Correction MoE, where we train the experts to become an ``expert'' of speech-to-text, language-to-text and vision-to-text datasets by learning to route each dataset's tokens to its mapped expert. Experiments on the Open ASR Leaderboard show that we explore a new state-of-the-art performance by achieving an average relative $5.0$% WER reduction and substantial improvements in BLEU scores for speech and translation tasks. On zero-shot evaluation, NeKo outperforms GPT-3.5 and Claude-Opus with $15.5$% to $27.6$% relative WER reduction in the Hyporadise benchmark. NeKo performs competitively on grammar and post-OCR correction as a multi-task model.
RankUp: Boosting Semi-Supervised Regression with an Auxiliary Ranking Classifier
Oct 29, 2024



State-of-the-art (SOTA) semi-supervised learning techniques, such as FixMatch and it's variants, have demonstrated impressive performance in classification tasks. However, these methods are not directly applicable to regression tasks. In this paper, we present RankUp, a simple yet effective approach that adapts existing semi-supervised classification techniques to enhance the performance of regression tasks. RankUp achieves this by converting the original regression task into a ranking problem and training it concurrently with the original regression objective. This auxiliary ranking classifier outputs a classification result, thus enabling integration with existing semi-supervised classification methods. Moreover, we introduce regression distribution alignment (RDA), a complementary technique that further enhances RankUp's performance by refining pseudo-labels through distribution alignment. Despite its simplicity, RankUp, with or without RDA, achieves SOTA results in across a range of regression benchmarks, including computer vision, audio, and natural language processing tasks. Our code and log data are open-sourced at https://github.com/pm25/semi-supervised-regression.
Developing Instruction-Following Speech Language Model Without Speech Instruction-Tuning Data
Sep 30, 2024



Recent end-to-end speech language models (SLMs) have expanded upon the capabilities of large language models (LLMs) by incorporating pre-trained speech models. However, these SLMs often undergo extensive speech instruction-tuning to bridge the gap between speech and text modalities. This requires significant annotation efforts and risks catastrophic forgetting of the original language capabilities. In this work, we present a simple yet effective automatic process for creating speech-text pair data that carefully injects speech paralinguistic understanding abilities into SLMs while preserving the inherent language capabilities of the text-based LLM. Our model demonstrates general capabilities for speech-related tasks without the need for speech instruction-tuning data, achieving impressive performance on Dynamic-SUPERB and AIR-Bench-Chat benchmarks. Furthermore, our model exhibits the ability to follow complex instructions derived from LLMs, such as specific output formatting and chain-of-thought reasoning. Our approach not only enhances the versatility and effectiveness of SLMs but also reduces reliance on extensive annotated datasets, paving the way for more efficient and capable speech understanding systems.