 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillHarm: Lifecycle-Aware Skill-Based Attacks via Automated Construction
Jun 01, 2026Agent skills occupy a privileged position in the agent workflow, as agents are expected to implicitly follow and execute them, rendering third-party skills a vulnerable attack surface. Existing studies have revealed unsafe agent behaviors induced by skill-based attacks, but they primarily evaluate poisoned skills within a single task execution and enumerate harms through ad-hoc risk lists. To bridge these gaps, we introduce SkillHarm, a benchmark of skill-based attacks across the skill-use lifecycle, paired with a systematic taxonomy of skill-relevant risks. SkillHarm evaluates two attack scenarios: Fixed-Payload Poisoning (FPP), where a fixed poisoned skill package directly compromises any task session that invokes it, and Self-Mutating Poisoning (SMP), where an initially benign execution silently mutates persistent skill content, deferring harm until a subsequent reuse. It further defines 12 risk types based on the agent workflow component targeted by the harm: data pipelines, system environments, and agent autonomy. To instantiate these attacks at scale, we build AutoSkillHarm, an automated construction pipeline with coding agents driven by natural-language harnesses. The resulting benchmark contains 879 attack samples across 71 skills. Experiments show that current agents remain vulnerable with attack success rates up to 86.3% in FPP and 69.3% in SMP. Our analysis further reveals a latent risk: many apparent attack failures stem from the agent failing to engage with the poisoned file rather than genuine resistance, and current defenses still fail to reliably mitigate the threat.
SWAN: Semantic Watermarking with Abstract Meaning Representation
May 05, 2026We introduce SWAN (Semantic Watermarking with Abstract Meaning Representation), a novel framework that embeds watermark signatures into the semantic structure of a sentence using Abstract Meaning Representation (AMR). In contrast to existing watermarking methods, which typically encode signatures by adjusting token selection preferences during text generation, SWAN embeds the signature directly in the sentence's semantic representation. As the signature is encoded at the semantic structure level, any paraphrase that preserves meaning automatically preserves the signature. SWAN is training-free: watermark injection is achieved by prompting an LLM to generate sentences guided by a selected AMR template while maintaining contextual coherence, and detection uses an off-the-shelf AMR parser followed by a simple one-proportion z-test. Empirical evaluation on the RealNews benchmark shows SWAN matches state-of-the-art detection performance on unaltered watermarked text, while significantly improving robustness against paraphrasing, increasing detection AUC by up to 13.9 percentage points compared to prior methods. These results demonstrate that SWAN's approach of anchoring watermarks in AMR semantic structures provides a simple, effective, and prompt-based method for robust text provenance verification under paraphrasing, opening new avenues for semantic-level watermarking research.
When Actions Go Off-Task: Detecting and Correcting Misaligned Actions in Computer-Use Agents
Feb 09, 2026Computer-use agents (CUAs) have made tremendous progress in the past year, yet they still frequently produce misaligned actions that deviate from the user's original intent. Such misaligned actions may arise from external attacks (e.g., indirect prompt injection) or from internal limitations (e.g., erroneous reasoning). They not only expose CUAs to safety risks, but also degrade task efficiency and reliability. This work makes the first effort to define and study misaligned action detection in CUAs, with comprehensive coverage of both externally induced and internally arising misaligned actions. We further identify three common categories in real-world CUA deployment and construct MisActBench, a benchmark of realistic trajectories with human-annotated, action-level alignment labels. Moreover, we propose DeAction, a practical and universal guardrail that detects misaligned actions before execution and iteratively corrects them through structured feedback. DeAction outperforms all existing baselines across offline and online evaluations with moderate latency overhead: (1) On MisActBench, it outperforms baselines by over 15% absolute in F1 score; (2) In online evaluation, it reduces attack success rate by over 90% under adversarial settings while preserving or even improving task success rate in benign environments.
Customize Multi-modal RAI Guardrails with Precedent-based predictions
Jul 28, 2025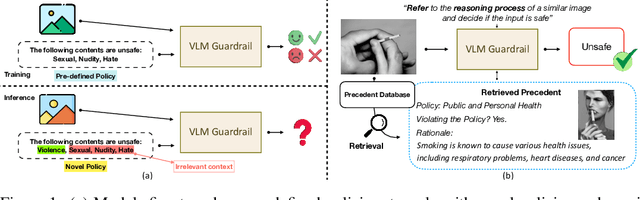
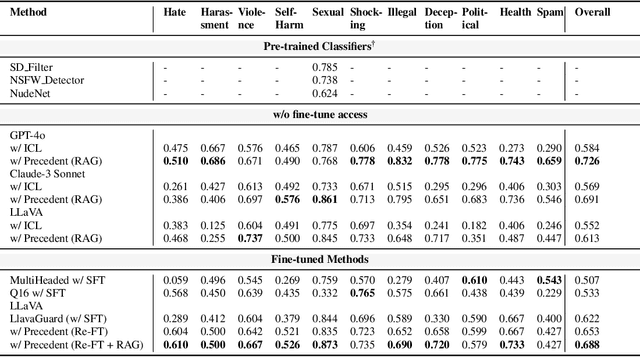
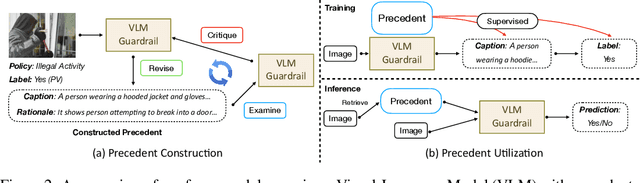
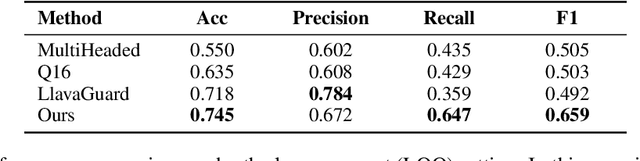
A multi-modal guardrail must effectively filter image content based on user-defined policies, identifying material that may be hateful, reinforce harmful stereotypes, contain explicit material, or spread misinformation. Deploying such guardrails in real-world applications, however, poses significant challenges. Users often require varied and highly customizable policies and typically cannot provide abundant examples for each custom policy. Consequently, an ideal guardrail should be scalable to the multiple policies and adaptable to evolving user standards with minimal retraining. Existing fine-tuning methods typically condition predictions on pre-defined policies, restricting their generalizability to new policies or necessitating extensive retraining to adapt. Conversely, training-free methods struggle with limited context lengths, making it difficult to incorporate all the policies comprehensively. To overcome these limitations, we propose to condition model's judgment on "precedents", which are the reasoning processes of prior data points similar to the given input. By leveraging precedents instead of fixed policies, our approach greatly enhances the flexibility and adaptability of the guardrail. In this paper, we introduce a critique-revise mechanism for collecting high-quality precedents and two strategies that utilize precedents for robust prediction. Experimental results demonstrate that our approach outperforms previous methods across both few-shot and full-dataset scenarios and exhibits superior generalization to novel policies.
Improving Spoken Language Understanding By Exploiting ASR N-best Hypotheses
Jan 11, 2020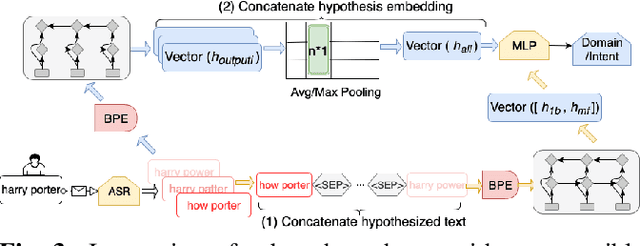
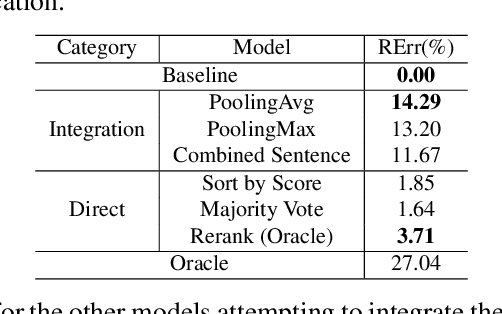
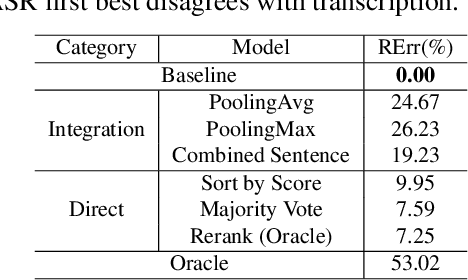
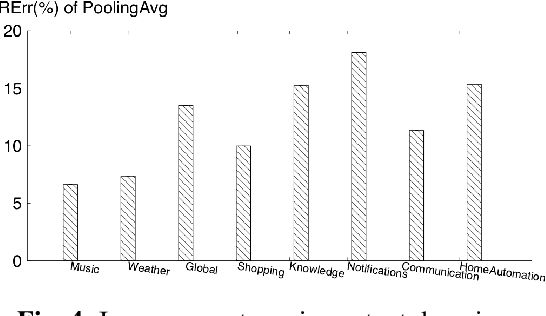
In a modern spoken language understanding (SLU) system, the natural language understanding (NLU) module takes interpretations of a speech from the automatic speech recognition (ASR) module as the input. The NLU module usually uses the first best interpretation of a given speech in downstream tasks such as domain and intent classification. However, the ASR module might misrecognize some speeches and the first best interpretation could be erroneous and noisy. Solely relying on the first best interpretation could make the performance of downstream tasks non-optimal. To address this issue, we introduce a series of simple yet efficient models for improving the understanding of semantics of the input speeches by collectively exploiting the n-best speech interpretations from the ASR module.
Ensemble Multi-task Gaussian Process Regression with Multiple Latent Processes
May 09, 2018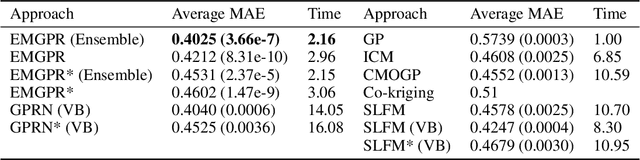
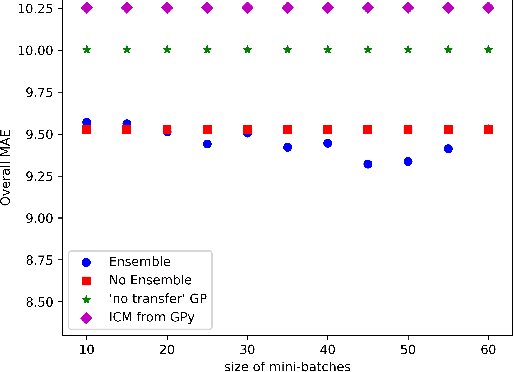
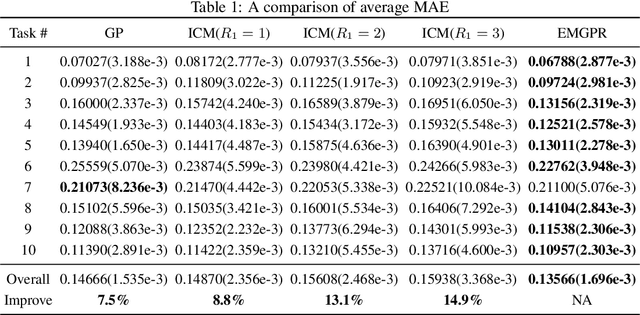
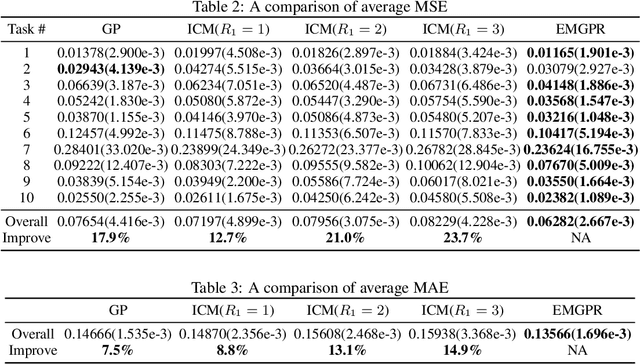
Multi-task/Multi-output learning seeks to exploit correlation among tasks to enhance performance over learning or solving each task independently. In this paper, we investigate this problem in the context of Gaussian Processes (GPs) and propose a new model which learns a mixture of latent processes by decomposing the covariance matrix into a sum of structured hidden components each of which is controlled by a latent GP over input features and a "weight" over tasks. From this sum structure, we propose a parallelizable parameter learning algorithm with a predetermined initialization for the "weights". We also notice that an ensemble parameter learning approach using mini-batches of training data not only reduces the computation complexity of learning but also improves the regression performance. We evaluate our model on two datasets, the smaller Swiss Jura dataset and another relatively larger ATMS dataset from NOAA. Substantial improvements are observed compared with established alternatives.