 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoVE: Translating Laughter and Tears via Mixture of Vocalization Experts in Speech-to-Speech Translation
Apr 19, 2026Recent Speech-to-Speech Translation (S2ST) systems achieve strong semantic accuracy yet consistently strip away non-verbal vocalizations (NVs), such as laughter and crying that convey pragmatic intent, which severely limits real-world utility. We address this via three contributions. First, we propose a synthesis pipeline for building scalable expressive datasets to overcome the data scarcity limitation. Second, we propose MoVE, a Mixture-of-LoRA-Experts architecture with expressive-specialized adapters and a soft-weighting router that blends experts for capturing hybrid expressive states. Third, we show pretrained AudioLLMs enable striking data efficiency: 30 minutes of curated data is enough for strong performance. On English-Chinese S2ST, while comparing with strong baselines, MoVE reproduces target NVs in 76% of cases and achieves the highest human-rated naturalness and emotional fidelity among all compared systems, where existing S2ST systems preserve at most 14% of NVs.
Joint Fullband-Subband Modeling for High-Resolution SingFake Detection
Apr 06, 2026Rapid advances in singing voice synthesis have increased unauthorized imitation risks, creating an urgent need for better Singing Voice Deepfake (SingFake) Detection, also known as SVDD. Unlike speech, singing contains complex pitch, wide dynamic range, and timbral variations. Conventional 16 kHz-sampled detectors prove inadequate, as they discard vital high-frequency information. This study presents the first systematic analysis of high-resolution (44.1 kHz sampling rate) audio for SVDD. We propose a joint fullband-subband modeling framework: the fullband captures global context, while subband-specific experts isolate fine-grained synthesis artifacts unevenly distributed across the spectrum. Experiments on the WildSVDD dataset demonstrate that high-frequency subbands provide essential complementary cues. Our framework significantly outperforms 16 kHz-sampled models, proving that high-resolution audio and strategic subband integration are critical for robust in-the-wild detection.
How Auditory Knowledge in LLM Backbones Shapes Audio Language Models: A Holistic Evaluation
Mar 19, 2026Large language models (LLMs) have been widely used as knowledge backbones of Large Audio Language Models (LALMs), yet how much auditory knowledge they encode through text-only pre-training and how this affects downstream performance remains unclear. We study this gap by comparing different LLMs under two text-only and one audio-grounded setting: (1) direct probing on AKB-2000, a curated benchmark testing the breadth and depth of auditory knowledge; (2) cascade evaluation, where LLMs reason over text descriptions from an audio captioner; and (3) audio-grounded evaluation, where each LLM is fine-tuned into a Large Audio Language Model (LALM) with an audio encoder. Our findings reveal that auditory knowledge varies substantially across families, and text-only results are strongly correlated with audio performance. Our work provides empirical grounding for a comprehensive understanding of LLMs in audio research.
How Does Instrumental Music Help SingFake Detection?
Sep 18, 2025Although many models exist to detect singing voice deepfakes (SingFake), how these models operate, particularly with instrumental accompaniment, is unclear. We investigate how instrumental music affects SingFake detection from two perspectives. To investigate the behavioral effect, we test different backbones, unpaired instrumental tracks, and frequency subbands. To analyze the representational effect, we probe how fine-tuning alters encoders' speech and music capabilities. Our results show that instrumental accompaniment acts mainly as data augmentation rather than providing intrinsic cues (e.g., rhythm or harmony). Furthermore, fine-tuning increases reliance on shallow speaker features while reducing sensitivity to content, paralinguistic, and semantic information. These insights clarify how models exploit vocal versus instrumental cues and can inform the design of more interpretable and robust SingFake detection systems.
DeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025



We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
Detecting the Undetectable: Assessing the Efficacy of Current Spoof Detection Methods Against Seamless Speech Edits
Jan 07, 2025



Neural speech editing advancements have raised concerns about their misuse in spoofing attacks. Traditional partially edited speech corpora primarily focus on cut-and-paste edits, which, while maintaining speaker consistency, often introduce detectable discontinuities. Recent methods, like A\textsuperscript{3}T and Voicebox, improve transitions by leveraging contextual information. To foster spoofing detection research, we introduce the Speech INfilling Edit (SINE) dataset, created with Voicebox. We detailed the process of re-implementing Voicebox training and dataset creation. Subjective evaluations confirm that speech edited using this novel technique is more challenging to detect than conventional cut-and-paste methods. Despite human difficulty, experimental results demonstrate that self-supervised-based detectors can achieve remarkable performance in detection, localization, and generalization across different edit methods. The dataset and related models will be made publicly available.
Generative Speech Foundation Model Pretraining for High-Quality Speech Extraction and Restoration
Sep 25, 2024



This paper proposes a generative pretraining foundation model for high-quality speech restoration tasks. By directly operating on complex-valued short-time Fourier transform coefficients, our model does not rely on any vocoders for time-domain signal reconstruction. As a result, our model simplifies the synthesis process and removes the quality upper-bound introduced by any mel-spectrogram vocoder compared to prior work SpeechFlow. The proposed method is evaluated on multiple speech restoration tasks, including speech denoising, bandwidth extension, codec artifact removal, and target speaker extraction. In all scenarios, finetuning our pretrained model results in superior performance over strong baselines. Notably, in the target speaker extraction task, our model outperforms existing systems, including those leveraging SSL-pretrained encoders like WavLM. The code and the pretrained checkpoints are publicly available in the NVIDIA NeMo framework.
Maximizing Data Efficiency for Cross-Lingual TTS Adaptation by Self-Supervised Representation Mixing and Embedding Initialization
Jan 23, 2024This paper presents an effective transfer learning framework for language adaptation in text-to-speech systems, with a focus on achieving language adaptation using minimal labeled and unlabeled data. While many works focus on reducing the usage of labeled data, very few consider minimizing the usage of unlabeled data. By utilizing self-supervised features in the pretraining stage, replacing the noisy portion of pseudo labels with these features during fine-tuning, and incorporating an embedding initialization trick, our method leverages more information from unlabeled data compared to conventional approaches. Experimental results show that our framework is able to synthesize intelligible speech in unseen languages with only 4 utterances of labeled data and 15 minutes of unlabeled data. Our methodology continues to surpass conventional techniques, even when a greater volume of data is accessible. These findings highlight the potential of our data-efficient language adaptation framework.
Personalized Lightweight Text-to-Speech: Voice Cloning with Adaptive Structured Pruning
Mar 21, 2023Personalized TTS is an exciting and highly desired application that allows users to train their TTS voice using only a few recordings. However, TTS training typically requires many hours of recording and a large model, making it unsuitable for deployment on mobile devices. To overcome this limitation, related works typically require fine-tuning a pre-trained TTS model to preserve its ability to generate high-quality audio samples while adapting to the target speaker's voice. This process is commonly referred to as ``voice cloning.'' Although related works have achieved significant success in changing the TTS model's voice, they are still required to fine-tune from a large pre-trained model, resulting in a significant size for the voice-cloned model. In this paper, we propose applying trainable structured pruning to voice cloning. By training the structured pruning masks with voice-cloning data, we can produce a unique pruned model for each target speaker. Our experiments demonstrate that using learnable structured pruning, we can compress the model size to 7 times smaller while achieving comparable voice-cloning performance.
Few-Shot Cross-Lingual TTS Using Transferable Phoneme Embedding
Jun 27, 2022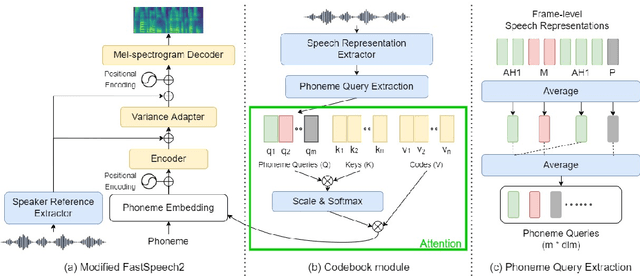
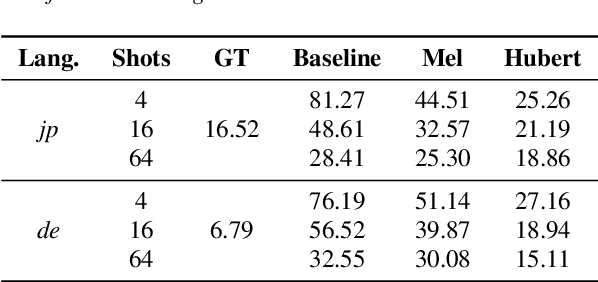
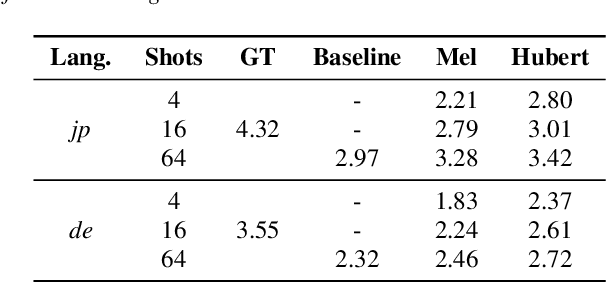
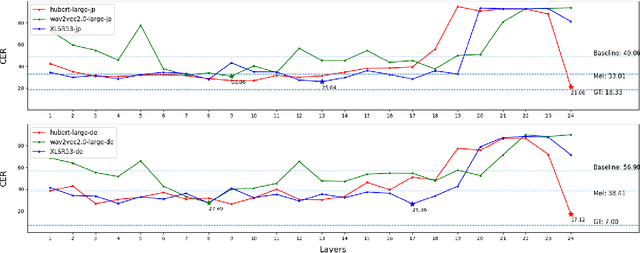
This paper studies a transferable phoneme embedding framework that aims to deal with the cross-lingual text-to-speech (TTS) problem under the few-shot setting. Transfer learning is a common approach when it comes to few-shot learning since training from scratch on few-shot training data is bound to overfit. Still, we find that the naive transfer learning approach fails to adapt to unseen languages under extremely few-shot settings, where less than 8 minutes of data is provided. We deal with the problem by proposing a framework that consists of a phoneme-based TTS model and a codebook module to project phonemes from different languages into a learned latent space. Furthermore, by utilizing phoneme-level averaged self-supervised learned features, we effectively improve the quality of synthesized speeches. Experiments show that using 4 utterances, which is about 30 seconds of data, is enough to synthesize intelligible speech when adapting to an unseen language using our framework.