 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning
Jul 22, 2025



Recent advances in multimodal large language models (MLLMs) have shown impressive reasoning capabilities. However, further enhancing existing MLLMs necessitates high-quality vision-language datasets with carefully curated task complexities, which are both costly and challenging to scale. Although recent self-improving models that iteratively refine themselves offer a feasible solution, they still suffer from two core challenges: (i) most existing methods augment visual or textual data separately, resulting in discrepancies in data complexity (e.g., over-simplified diagrams paired with redundant textual descriptions); and (ii) the evolution of data and models is also separated, leading to scenarios where models are exposed to tasks with mismatched difficulty levels. To address these issues, we propose C2-Evo, an automatic, closed-loop self-improving framework that jointly evolves both training data and model capabilities. Specifically, given a base dataset and a base model, C2-Evo enhances them by a cross-modal data evolution loop and a data-model evolution loop. The former loop expands the base dataset by generating complex multimodal problems that combine structured textual sub-problems with iteratively specified geometric diagrams, while the latter loop adaptively selects the generated problems based on the performance of the base model, to conduct supervised fine-tuning and reinforcement learning alternately. Consequently, our method continuously refines its model and training data, and consistently obtains considerable performance gains across multiple mathematical reasoning benchmarks. Our code, models, and datasets will be released.
Enhancing Cross-task Transfer of Large Language Models via Activation Steering
Jul 17, 2025



Large language models (LLMs) have shown impressive abilities in leveraging pretrained knowledge through prompting, but they often struggle with unseen tasks, particularly in data-scarce scenarios. While cross-task in-context learning offers a direct solution for transferring knowledge across tasks, it still faces critical challenges in terms of robustness, scalability, and efficiency. In this paper, we investigate whether cross-task transfer can be achieved via latent space steering without parameter updates or input expansion. Through an analysis of activation patterns in the latent space of LLMs, we observe that the enhanced activations induced by in-context examples have consistent patterns across different tasks. Inspired by these findings, we propose CAST, a novel Cross-task Activation Steering Transfer framework that enables effective transfer by manipulating the model's internal activation states. Our approach first selects influential and diverse samples from high-resource tasks, then utilizes their contrastive representation-enhanced activations to adapt LLMs to low-resource tasks. Extensive experiments across both cross-domain and cross-lingual transfer settings show that our method outperforms competitive baselines and demonstrates superior scalability and lower computational costs.
AdvMIM: Adversarial Masked Image Modeling for Semi-Supervised Medical Image Segmentation
Jun 25, 2025Vision Transformer has recently gained tremendous popularity in medical image segmentation task due to its superior capability in capturing long-range dependencies. However, transformer requires a large amount of labeled data to be effective, which hinders its applicability in annotation scarce semi-supervised learning scenario where only limited labeled data is available. State-of-the-art semi-supervised learning methods propose combinatorial CNN-Transformer learning to cross teach a transformer with a convolutional neural network, which achieves promising results. However, it remains a challenging task to effectively train the transformer with limited labeled data. In this paper, we propose an adversarial masked image modeling method to fully unleash the potential of transformer for semi-supervised medical image segmentation. The key challenge in semi-supervised learning with transformer lies in the lack of sufficient supervision signal. To this end, we propose to construct an auxiliary masked domain from original domain with masked image modeling and train the transformer to predict the entire segmentation mask with masked inputs to increase supervision signal. We leverage the original labels from labeled data and pseudo-labels from unlabeled data to learn the masked domain. To further benefit the original domain from masked domain, we provide a theoretical analysis of our method from a multi-domain learning perspective and devise a novel adversarial training loss to reduce the domain gap between the original and masked domain, which boosts semi-supervised learning performance. We also extend adversarial masked image modeling to CNN network. Extensive experiments on three public medical image segmentation datasets demonstrate the effectiveness of our method, where our method outperforms existing methods significantly. Our code is publicly available at https://github.com/zlheui/AdvMIM.
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
Toward Reliable AR-Guided Surgical Navigation: Interactive Deformation Modeling with Data-Driven Biomechanics and Prompts
Jun 11, 2025In augmented reality (AR)-guided surgical navigation, preoperative organ models are superimposed onto the patient's intraoperative anatomy to visualize critical structures such as vessels and tumors. Accurate deformation modeling is essential to maintain the reliability of AR overlays by ensuring alignment between preoperative models and the dynamically changing anatomy. Although the finite element method (FEM) offers physically plausible modeling, its high computational cost limits intraoperative applicability. Moreover, existing algorithms often fail to handle large anatomical changes, such as those induced by pneumoperitoneum or ligament dissection, leading to inaccurate anatomical correspondences and compromised AR guidance. To address these challenges, we propose a data-driven biomechanics algorithm that preserves FEM-level accuracy while improving computational efficiency. In addition, we introduce a novel human-in-the-loop mechanism into the deformation modeling process. This enables surgeons to interactively provide prompts to correct anatomical misalignments, thereby incorporating clinical expertise and allowing the model to adapt dynamically to complex surgical scenarios. Experiments on a publicly available dataset demonstrate that our algorithm achieves a mean target registration error of 3.42 mm. Incorporating surgeon prompts through the interactive framework further reduces the error to 2.78 mm, surpassing state-of-the-art methods in volumetric accuracy. These results highlight the ability of our framework to deliver efficient and accurate deformation modeling while enhancing surgeon-algorithm collaboration, paving the way for safer and more reliable computer-assisted surgeries.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025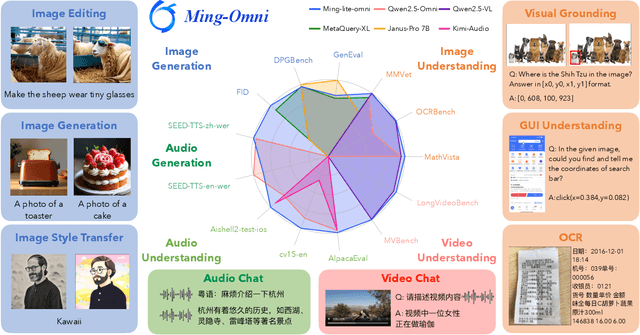
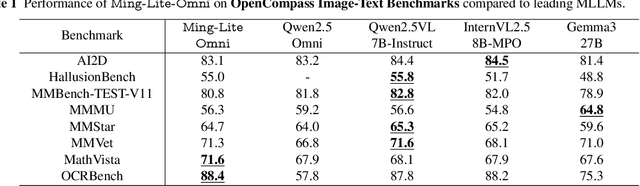
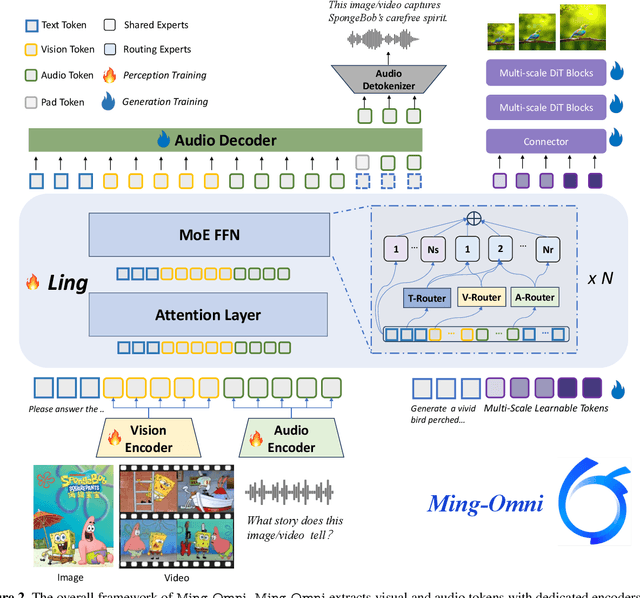
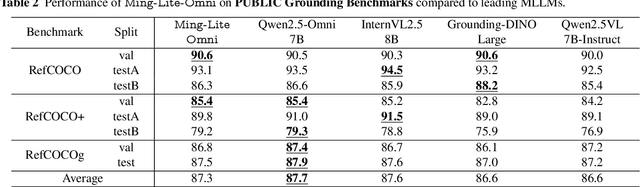
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Patient-Specific Deep Reinforcement Learning for Automatic Replanning in Head-and-Neck Cancer Proton Therapy
Jun 11, 2025Anatomical changes during intensity-modulated proton therapy (IMPT) for head-and-neck cancer (HNC) can shift Bragg peaks, risking tumor underdosing and organ-at-risk overdosing. As a result, treatment replanning is often required to maintain clinically acceptable treatment quality. However, current manual replanning processes are resource-intensive and time-consuming. We propose a patient-specific deep reinforcement learning (DRL) framework for automated IMPT replanning, with a reward-shaping mechanism based on a $150$-point plan quality score addressing competing clinical objectives. We formulate the planning process as an RL problem where agents learn control policies to adjust optimization priorities, maximizing plan quality. Unlike population-based approaches, our framework trains personalized agents for each patient using their planning CT (Computed Tomography) and augmented anatomies simulating anatomical changes (tumor progression and regression). This patient-specific approach leverages anatomical similarities throughout treatment, enabling effective plan adaptation. We implemented two DRL algorithms, Deep Q-Network and Proximal Policy Optimization, using dose-volume histograms (DVHs) as state representations and a $22$-dimensional action space of priority adjustments. Evaluation on five HNC patients using actual replanning CT data showed both DRL agents improved initial plan scores from $120.63 \pm 21.40$ to $139.78 \pm 6.84$ (DQN) and $142.74 \pm 5.16$ (PPO), surpassing manual replans generated by a human planner ($137.20 \pm 5.58$). Clinical validation confirms that improvements translate to better tumor coverage and OAR sparing across diverse anatomical changes. This work demonstrates DRL's potential in addressing geometric and dosimetric complexities of adaptive proton therapy, offering efficient offline adaptation solutions and advancing online adaptive proton therapy.
Efficient Text-Attributed Graph Learning through Selective Annotation and Graph Alignment
Jun 08, 2025In the realm of Text-attributed Graphs (TAGs), traditional graph neural networks (GNNs) often fall short due to the complex textual information associated with each node. Recent methods have improved node representations by leveraging large language models (LLMs) to enhance node text features, but these approaches typically require extensive annotations or fine-tuning across all nodes, which is both time-consuming and costly. To overcome these challenges, we introduce GAGA, an efficient framework for TAG representation learning. GAGA reduces annotation time and cost by focusing on annotating only representative nodes and edges. It constructs an annotation graph that captures the topological relationships among these annotations. Furthermore, GAGA employs a two-level alignment module to effectively integrate the annotation graph with the TAG, aligning their underlying structures. Experiments show that GAGA achieves classification accuracies on par with or surpassing state-of-the-art methods while requiring only 1% of the data to be annotated, demonstrating its high efficiency.
EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions
May 29, 2025



Large language models (LLMs) frequently refuse to respond to pseudo-malicious instructions: semantically harmless input queries triggering unnecessary LLM refusals due to conservative safety alignment, significantly impairing user experience. Collecting such instructions is crucial for evaluating and mitigating over-refusals, but existing instruction curation methods, like manual creation or instruction rewriting, either lack scalability or fail to produce sufficiently diverse and effective refusal-inducing prompts. To address these limitations, we introduce EVOREFUSE, a prompt optimization approach that generates diverse pseudo-malicious instructions consistently eliciting confident refusals across LLMs. EVOREFUSE employs an evolutionary algorithm exploring the instruction space in more diverse directions than existing methods via mutation strategies and recombination, and iteratively evolves seed instructions to maximize evidence lower bound on LLM refusal probability. Using EVOREFUSE, we create two novel datasets: EVOREFUSE-TEST, a benchmark of 582 pseudo-malicious instructions that outperforms the next-best benchmark with 140.41% higher average refusal triggering rate across 9 LLMs, 34.86% greater lexical diversity, and 40.03% improved LLM response confidence scores; and EVOREFUSE-ALIGN, which provides 3,000 pseudo-malicious instructions with responses for supervised and preference-based alignment training. LLAMA3.1-8B-INSTRUCT supervisedly fine-tuned on EVOREFUSE-ALIGN achieves up to 14.31% fewer over-refusals than models trained on the second-best alignment dataset, without compromising safety. Our analysis with EVOREFUSE-TEST reveals models trigger over-refusals by overly focusing on sensitive keywords while ignoring broader context.
SAM-R1: Leveraging SAM for Reward Feedback in Multimodal Segmentation via Reinforcement Learning
May 28, 2025Leveraging multimodal large models for image segmentation has become a prominent research direction. However, existing approaches typically rely heavily on manually annotated datasets that include explicit reasoning processes, which are costly and time-consuming to produce. Recent advances suggest that reinforcement learning (RL) can endow large models with reasoning capabilities without requiring such reasoning-annotated data. In this paper, we propose SAM-R1, a novel framework that enables multimodal large models to perform fine-grained reasoning in image understanding tasks. Our approach is the first to incorporate fine-grained segmentation settings during the training of multimodal reasoning models. By integrating task-specific, fine-grained rewards with a tailored optimization objective, we further enhance the model's reasoning and segmentation alignment. We also leverage the Segment Anything Model (SAM) as a strong and flexible reward provider to guide the learning process. With only 3k training samples, SAM-R1 achieves strong performance across multiple benchmarks, demonstrating the effectiveness of reinforcement learning in equipping multimodal models with segmentation-oriented reasoning capabilities.