 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Residual Reweighting for Classifier Free Guidance in Flow-Matching Zero-Shot TTS
Jun 24, 2026Classifier-free guidance (CFG) is widely used in flow-matching-based zero-shot text-to-speech (TTS), where generation is typically controlled by two conditions: the target text and a prompt speech signal. Standard CFG strengthens these conditions jointly, while recent branch-selective guidance methods attempt to enhance text or speaker conditioning separately, often leading to a trade-off between text correctness and speaker similarity. In this paper, we revisit the CFG under independently masked text and speech-prompt conditions, and decompose the guidance field into text, speaker, and joint residuals. We show that conventional speaker-selective guidance entangles the speaker residual with the joint residual, which may disturb text-related generation. Based on this observation, we propose joint residual reweighting, which independently controls the speaker and joint residuals within the standard CFG framework. Experiments on F5-TTS and CosyVoice2 show that the proposed method improves speaker similarity while maintaining competitive text correctness, demonstrating the usefulness of the joint residual for balancing speaker fidelity and text accuracy in zero-shot TTS.
SPRI: SVD-Partitioned Residual Initialization for Data-Constrained MoE Upcycling
Jun 15, 2026Mixture-of-Experts (MoE) models enable efficient scaling, but training them from scratch remains prohibitively expensive. MoE upcycling mitigates this cost by converting pretrained dense models into sparse MoE models. However, existing upcycling methods typically rely on large-scale continued training and often perform poorly under data-constrained supervised adaptation, due to either homogeneous experts or overly disruptive perturbations to pretrained parameters. In this setting, effective upcycling must leverage pretrained weight structure while introducing sufficient diversity among routed experts. To this end, we propose SVD-Partitioned Residual Initialization (SPRI), which distributes SVD-partitioned residuals derived from pretrained feed-forward network (FFN) weights across routed experts, introducing controlled expert diversity grounded in pretrained spectral structure. We further introduce a two-stage training strategy to improve adaptation stability. We evaluate SPRI on multilingual speech-to-text translation, where limited supervised data challenges MoE upcycling and multiple target languages provide natural routing heterogeneity. On CoVoST2 across 15 En-to-XX directions, SPRI improves average BLEU and COMET over fully fine-tuned dense models by 2.58 and 3.32 points, respectively, and outperforms the prior best MoE upcycling baseline by 3.39 BLEU and 4.34 COMET points.
VividVoice: A Unified Framework for Scene-Aware Visually-Driven Speech Synthesis
Feb 01, 2026We introduce and define a novel task-Scene-Aware Visually-Driven Speech Synthesis, aimed at addressing the limitations of existing speech generation models in creating immersive auditory experiences that align with the real physical world. To tackle the two core challenges of data scarcity and modality decoupling, we propose VividVoice, a unified generative framework. First, we constructed a large-scale, high-quality hybrid multimodal dataset, Vivid-210K, which, through an innovative programmatic pipeline, establishes a strong correlation between visual scenes, speaker identity, and audio for the first time. Second, we designed a core alignment module, D-MSVA, which leverages a decoupled memory bank architecture and a cross-modal hybrid supervision strategy to achieve fine-grained alignment from visual scenes to timbre and environmental acoustic features. Both subjective and objective experimental results provide strong evidence that VividVoice significantly outperforms existing baseline models in terms of audio fidelity, content clarity, and multimodal consistency. Our demo is available at https://chengyuann.github.io/VividVoice/.
ReStyle-TTS: Relative and Continuous Style Control for Zero-Shot Speech Synthesis
Jan 07, 2026Zero-shot text-to-speech models can clone a speaker's timbre from a short reference audio, but they also strongly inherit the speaking style present in the reference. As a result, synthesizing speech with a desired style often requires carefully selecting reference audio, which is impractical when only limited or mismatched references are available. While recent controllable TTS methods attempt to address this issue, they typically rely on absolute style targets and discrete textual prompts, and therefore do not support continuous and reference-relative style control. We propose ReStyle-TTS, a framework that enables continuous and reference-relative style control in zero-shot TTS. Our key insight is that effective style control requires first reducing the model's implicit dependence on reference style before introducing explicit control mechanisms. To this end, we introduce Decoupled Classifier-Free Guidance (DCFG), which independently controls text and reference guidance, reducing reliance on reference style while preserving text fidelity. On top of this, we apply style-specific LoRAs together with Orthogonal LoRA Fusion to enable continuous and disentangled multi-attribute control, and introduce a Timbre Consistency Optimization module to mitigate timbre drift caused by weakened reference guidance. Experiments show that ReStyle-TTS enables user-friendly, continuous, and relative control over pitch, energy, and multiple emotions while maintaining intelligibility and speaker timbre, and performs robustly in challenging mismatched reference-target style scenarios.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025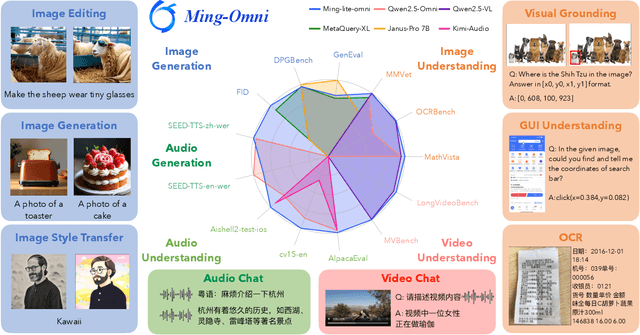
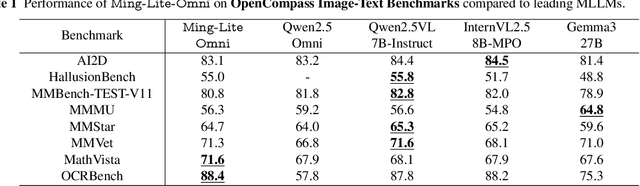
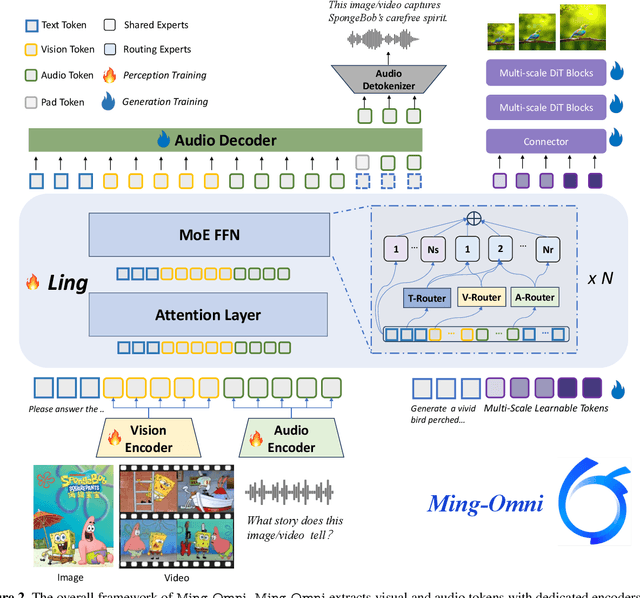
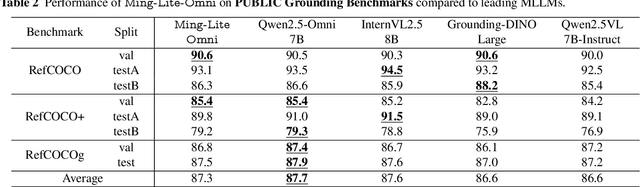
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.