 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdamHD: Decoupled Huber Decay Regularization for Language Model Pre-Training
Nov 18, 2025Adaptive optimizers with decoupled weight decay, such as AdamW, are the de facto standard for pre-training large transformer-based generative models. Yet the quadratic nature of the $\ell_2$ penalty embedded in weight decay drives all parameters toward the origin at the same rate, making the update vulnerable to rare but extreme gradient directions and often over-penalizing well-conditioned coordinates. We propose AdamHuberDecay, a drop-in replacement for AdamW that substitutes the $\ell_2$ penalty with a decoupled smooth Huber regularizer. The resulting update decays parameters quadratically while their magnitude remains below a threshold $δ$, and linearly ($\ell_1$-like) once they exceed $δ$, yielding (i) bounded regularization gradients, (ii) invariance to per-coordinate second-moment rescaling, and (iii) stronger sparsity pressure on overgrown weights. We derive the closed-form decoupled Huber decay step and show how to integrate it with any Adam-family optimizer at $O(1)$ extra cost. Extensive experiments on GPT-2 and GPT-3 pre-training demonstrate that AdamHuberDecay (a) converges 10-15% faster in wall-clock time, (b) reduces validation perplexity by up to 4 points, (c) delivers performance improvements of 2.5-4.7% across downstream tasks, and (d) yields visibly sparser weight histograms that translate into 20-30% memory savings after magnitude pruning, without tuning the decay coefficient beyond the default grid used for AdamW. Ablations confirm robustness to outlier gradients and large-batch regimes, together with theoretical analyses that bound the expected parameter norm under noisy updates. AdamHuberDecay therefore provides a simple, principled path toward more efficient and resilient training of next-generation foundational generative transformers.
* 39th Conference on Neural Information Processing Systems (NeurIPS 2025) Workshop: GPU-Accelerated and Scalable Optimization (ScaleOpt)
Toward Reliable AR-Guided Surgical Navigation: Interactive Deformation Modeling with Data-Driven Biomechanics and Prompts
Jun 11, 2025In augmented reality (AR)-guided surgical navigation, preoperative organ models are superimposed onto the patient's intraoperative anatomy to visualize critical structures such as vessels and tumors. Accurate deformation modeling is essential to maintain the reliability of AR overlays by ensuring alignment between preoperative models and the dynamically changing anatomy. Although the finite element method (FEM) offers physically plausible modeling, its high computational cost limits intraoperative applicability. Moreover, existing algorithms often fail to handle large anatomical changes, such as those induced by pneumoperitoneum or ligament dissection, leading to inaccurate anatomical correspondences and compromised AR guidance. To address these challenges, we propose a data-driven biomechanics algorithm that preserves FEM-level accuracy while improving computational efficiency. In addition, we introduce a novel human-in-the-loop mechanism into the deformation modeling process. This enables surgeons to interactively provide prompts to correct anatomical misalignments, thereby incorporating clinical expertise and allowing the model to adapt dynamically to complex surgical scenarios. Experiments on a publicly available dataset demonstrate that our algorithm achieves a mean target registration error of 3.42 mm. Incorporating surgeon prompts through the interactive framework further reduces the error to 2.78 mm, surpassing state-of-the-art methods in volumetric accuracy. These results highlight the ability of our framework to deliver efficient and accurate deformation modeling while enhancing surgeon-algorithm collaboration, paving the way for safer and more reliable computer-assisted surgeries.
Zero-Shot and Few-Shot Learning for Lung Cancer Multi-Label Classification using Vision Transformer
May 31, 2022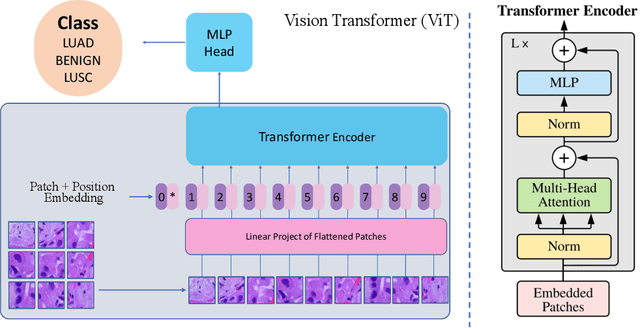
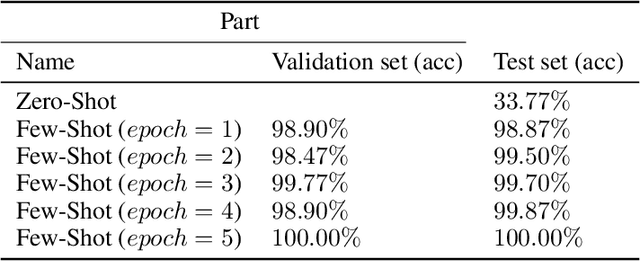
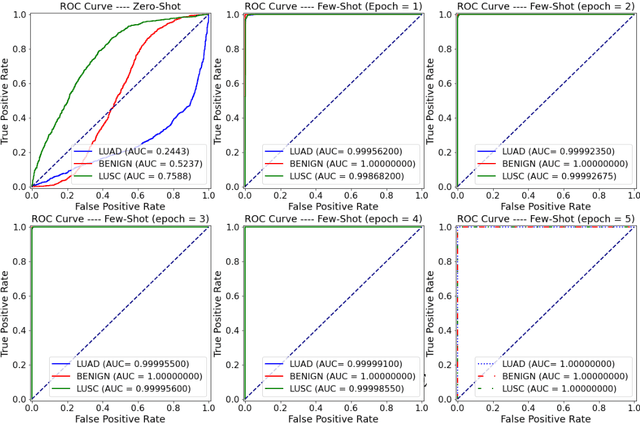
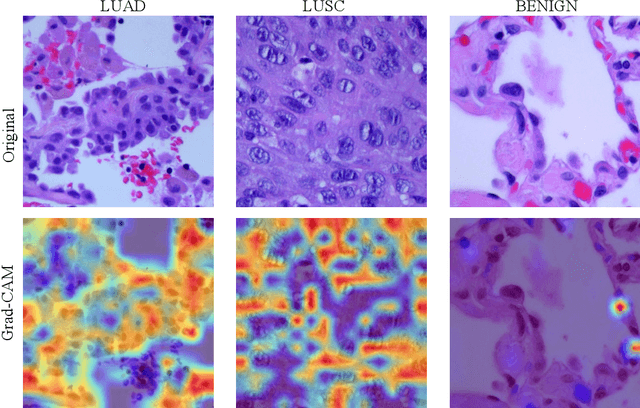
Lung cancer is the leading cause of cancer-related death worldwide. Lung adenocarcinoma (LUAD) and lung squamous cell carcinoma (LUSC) are the most common histologic subtypes of non-small-cell lung cancer (NSCLC). Histology is an essential tool for lung cancer diagnosis. Pathologists make classifications according to the dominant subtypes. Although morphology remains the standard for diagnosis, significant tool needs to be developed to elucidate the diagnosis. In our study, we utilize the pre-trained Vision Transformer (ViT) model to classify multiple label lung cancer on histologic slices (from dataset LC25000), in both Zero-Shot and Few-Shot settings. Then we compare the performance of Zero-Shot and Few-Shot ViT on accuracy, precision, recall, sensitivity and specificity. Our study show that the pre-trained ViT model has a good performance in Zero-Shot setting, a competitive accuracy ($99.87\%$) in Few-Shot setting ({epoch = 1}) and an optimal result ($100.00\%$ on both validation set and test set) in Few-Shot seeting ({epoch = 5}).