 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIDENT: Enhancing Large Language Model Safety with Tri-Dimensional Diversified Red-Teaming Data Synthesis
May 30, 2025



Large Language Models (LLMs) excel in various natural language processing tasks but remain vulnerable to generating harmful content or being exploited for malicious purposes. Although safety alignment datasets have been introduced to mitigate such risks through supervised fine-tuning (SFT), these datasets often lack comprehensive risk coverage. Most existing datasets focus primarily on lexical diversity while neglecting other critical dimensions. To address this limitation, we propose a novel analysis framework to systematically measure the risk coverage of alignment datasets across three essential dimensions: Lexical Diversity, Malicious Intent, and Jailbreak Tactics. We further introduce TRIDENT, an automated pipeline that leverages persona-based, zero-shot LLM generation to produce diverse and comprehensive instructions spanning these dimensions. Each harmful instruction is paired with an ethically aligned response, resulting in two datasets: TRIDENT-Core, comprising 26,311 examples, and TRIDENT-Edge, with 18,773 examples. Fine-tuning Llama 3.1-8B on TRIDENT-Edge demonstrates substantial improvements, achieving an average 14.29% reduction in Harm Score, and a 20% decrease in Attack Success Rate compared to the best-performing baseline model fine-tuned on the WildBreak dataset.
EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions
May 29, 2025



Large language models (LLMs) frequently refuse to respond to pseudo-malicious instructions: semantically harmless input queries triggering unnecessary LLM refusals due to conservative safety alignment, significantly impairing user experience. Collecting such instructions is crucial for evaluating and mitigating over-refusals, but existing instruction curation methods, like manual creation or instruction rewriting, either lack scalability or fail to produce sufficiently diverse and effective refusal-inducing prompts. To address these limitations, we introduce EVOREFUSE, a prompt optimization approach that generates diverse pseudo-malicious instructions consistently eliciting confident refusals across LLMs. EVOREFUSE employs an evolutionary algorithm exploring the instruction space in more diverse directions than existing methods via mutation strategies and recombination, and iteratively evolves seed instructions to maximize evidence lower bound on LLM refusal probability. Using EVOREFUSE, we create two novel datasets: EVOREFUSE-TEST, a benchmark of 582 pseudo-malicious instructions that outperforms the next-best benchmark with 140.41% higher average refusal triggering rate across 9 LLMs, 34.86% greater lexical diversity, and 40.03% improved LLM response confidence scores; and EVOREFUSE-ALIGN, which provides 3,000 pseudo-malicious instructions with responses for supervised and preference-based alignment training. LLAMA3.1-8B-INSTRUCT supervisedly fine-tuned on EVOREFUSE-ALIGN achieves up to 14.31% fewer over-refusals than models trained on the second-best alignment dataset, without compromising safety. Our analysis with EVOREFUSE-TEST reveals models trigger over-refusals by overly focusing on sensitive keywords while ignoring broader context.
Saec: Similarity-Aware Embedding Compression in Recommendation Systems
Feb 26, 2019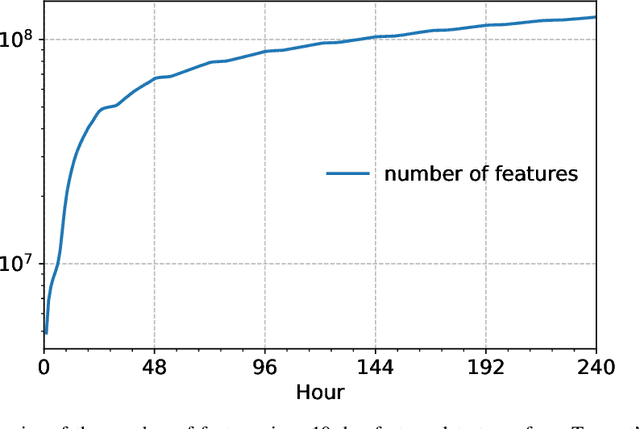
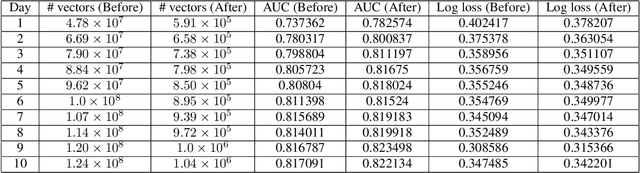
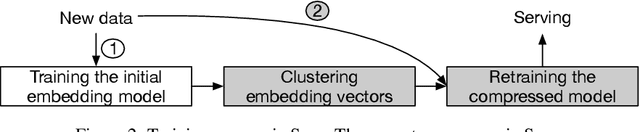
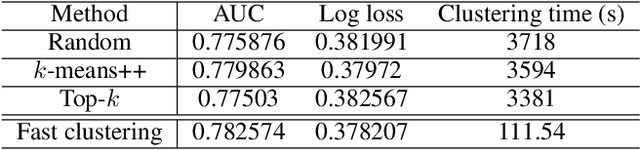
Production recommendation systems rely on embedding methods to represent various features. An impeding challenge in practice is that the large embedding matrix incurs substantial memory footprint in serving as the number of features grows over time. We propose a similarity-aware embedding matrix compression method called Saec to address this challenge. Saec clusters similar features within a field to reduce the embedding matrix size. Saec also adopts a fast clustering optimization based on feature frequency to drastically improve clustering time. We implement and evaluate Saec on Numerous, the production distributed machine learning system in Tencent, with 10-day worth of feature data from QQ mobile browser. Testbed experiments show that Saec reduces the number of embedding vectors by two orders of magnitude, compresses the embedding size by ~27x, and delivers the same AUC and log loss performance.
Stanza: Layer Separation for Distributed Training in Deep Learning
Jan 10, 2019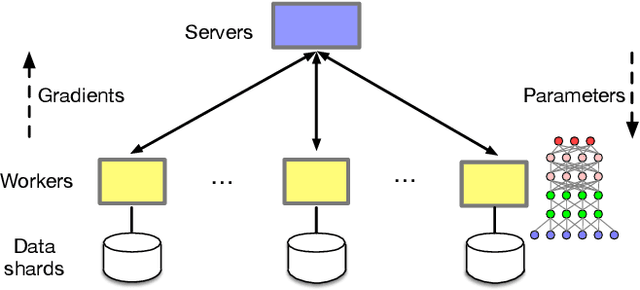
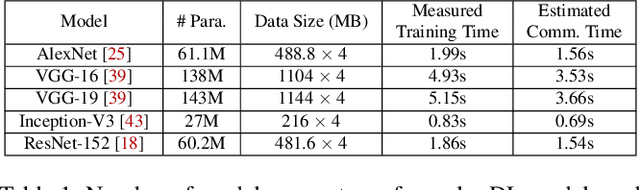
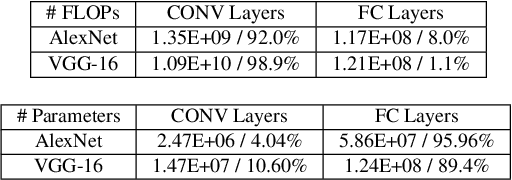
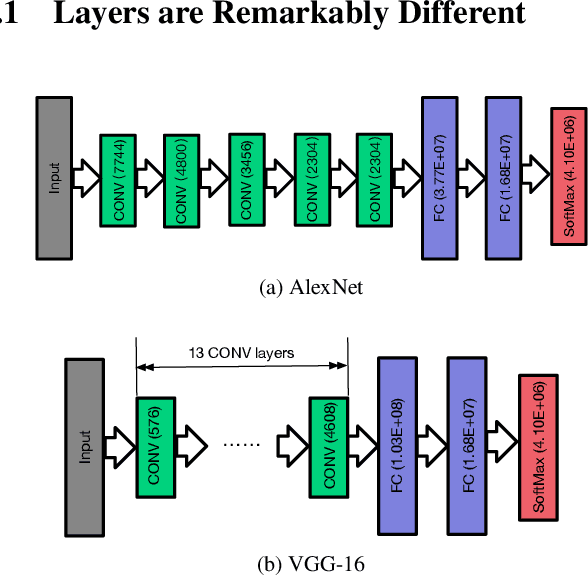
The parameter server architecture is prevalently used for distributed deep learning. Each worker machine in a parameter server system trains the complete model, which leads to a hefty amount of network data transfer between workers and servers. We empirically observe that the data transfer has a non-negligible impact on training time. To tackle the problem, we design a new distributed training system called Stanza. Stanza exploits the fact that in many models such as convolution neural networks, most data exchange is attributed to the fully connected layers, while most computation is carried out in convolutional layers. Thus, we propose layer separation in distributed training: the majority of the nodes just train the convolutional layers, and the rest train the fully connected layers only. Gradients and parameters of the fully connected layers no longer need to be exchanged across the cluster, thereby substantially reducing the data transfer volume. We implement Stanza on PyTorch and evaluate its performance on Azure and EC2. Results show that Stanza accelerates training significantly over current parameter server systems: on EC2 instances with Tesla V100 GPU and 10Gb bandwidth for example, Stanza is 1.34x--13.9x faster for common deep learning models.