 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARport: An Augmented Reality System for Markerless Image-Guided Port Placement in Robotic Surgery
Feb 15, 2026Purpose: Precise port placement is a critical step in robot-assisted surgery, where port configuration influences both visual access to the operative field and instrument maneuverability. To bridge the gap between preoperative planning and intraoperative execution, we present ARport, an augmented reality (AR) system that automatically maps pre-planned trocar layouts onto the patient's body surface, providing intuitive spatial guidance during surgical preparation. Methods: ARport, implemented on an optical see-through head-mounted display (OST-HMD), operates without any external sensors or markers, simplifying setup and enhancing workflow integration. It reconstructs the operative scene from RGB, depth, and pose data captured by the OST-HMD, extracts the patient's body surface using a foundation model, and performs surface-based markerless registration to align preoperative anatomical models to the extracted patient's body surface, enabling in-situ visualization of planned trocar layouts. A demonstration video illustrating the overall workflow is available online. Results: In full-scale human-phantom experiments, ARport accurately overlaid pre-planned trocar sites onto the physical phantom, achieving consistent spatial correspondence between virtual plans and real anatomy. Conclusion: ARport provides a fully marker-free and hardware-minimal solution for visualizing preoperative trocar plans directly on the patient's body surface. The system facilitates efficient intraoperative setup and demonstrates potential for seamless integration into routine clinical workflows.
Toward Reliable AR-Guided Surgical Navigation: Interactive Deformation Modeling with Data-Driven Biomechanics and Prompts
Jun 11, 2025In augmented reality (AR)-guided surgical navigation, preoperative organ models are superimposed onto the patient's intraoperative anatomy to visualize critical structures such as vessels and tumors. Accurate deformation modeling is essential to maintain the reliability of AR overlays by ensuring alignment between preoperative models and the dynamically changing anatomy. Although the finite element method (FEM) offers physically plausible modeling, its high computational cost limits intraoperative applicability. Moreover, existing algorithms often fail to handle large anatomical changes, such as those induced by pneumoperitoneum or ligament dissection, leading to inaccurate anatomical correspondences and compromised AR guidance. To address these challenges, we propose a data-driven biomechanics algorithm that preserves FEM-level accuracy while improving computational efficiency. In addition, we introduce a novel human-in-the-loop mechanism into the deformation modeling process. This enables surgeons to interactively provide prompts to correct anatomical misalignments, thereby incorporating clinical expertise and allowing the model to adapt dynamically to complex surgical scenarios. Experiments on a publicly available dataset demonstrate that our algorithm achieves a mean target registration error of 3.42 mm. Incorporating surgeon prompts through the interactive framework further reduces the error to 2.78 mm, surpassing state-of-the-art methods in volumetric accuracy. These results highlight the ability of our framework to deliver efficient and accurate deformation modeling while enhancing surgeon-algorithm collaboration, paving the way for safer and more reliable computer-assisted surgeries.
A Review on Organ Deformation Modeling Approaches for Reliable Surgical Navigation using Augmented Reality
Aug 05, 2024Augmented Reality (AR) holds the potential to revolutionize surgical procedures by allowing surgeons to visualize critical structures within the patient's body. This is achieved through superimposing preoperative organ models onto the actual anatomy. Challenges arise from dynamic deformations of organs during surgery, making preoperative models inadequate for faithfully representing intraoperative anatomy. To enable reliable navigation in augmented surgery, modeling of intraoperative deformation to obtain an accurate alignment of the preoperative organ model with the intraoperative anatomy is indispensable. Despite the existence of various methods proposed to model intraoperative organ deformation, there are still few literature reviews that systematically categorize and summarize these approaches. This review aims to fill this gap by providing a comprehensive and technical-oriented overview of modeling methods for intraoperative organ deformation in augmented reality in surgery. Through a systematic search and screening process, 112 closely relevant papers were included in this review. By presenting the current status of organ deformation modeling methods and their clinical applications, this review seeks to enhance the understanding of organ deformation modeling in AR-guided surgery, and discuss the potential topics for future advancements.
Data-driven and machine-learning based prediction of wave propagation behavior in dam-break flood
Sep 19, 2022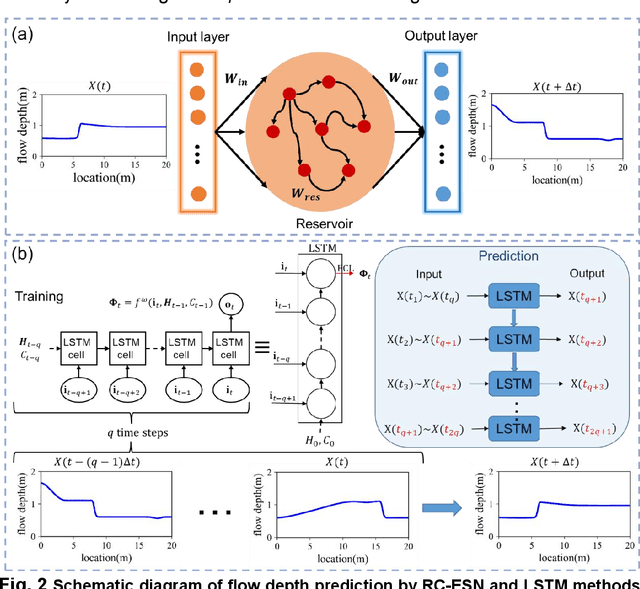
The computational prediction of wave propagation in dam-break floods is a long-standing problem in hydrodynamics and hydrology. Until now, conventional numerical models based on Saint-Venant equations are the dominant approaches. Here we show that a machine learning model that is well-trained on a minimal amount of data, can help predict the long-term dynamic behavior of a one-dimensional dam-break flood with satisfactory accuracy. For this purpose, we solve the Saint-Venant equations for a one-dimensional dam-break flood scenario using the Lax-Wendroff numerical scheme and train the reservoir computing echo state network (RC-ESN) with the dataset by the simulation results consisting of time-sequence flow depths. We demonstrate a good prediction ability of the RC-ESN model, which ahead predicts wave propagation behavior 286 time-steps in the dam-break flood with a root mean square error (RMSE) smaller than 0.01, outperforming the conventional long short-term memory (LSTM) model which reaches a comparable RMSE of only 81 time-steps ahead. To show the performance of the RC-ESN model, we also provide a sensitivity analysis of the prediction accuracy concerning the key parameters including training set size, reservoir size, and spectral radius. Results indicate that the RC-ESN are less dependent on the training set size, a medium reservoir size K=1200~2600 is sufficient. We confirm that the spectral radius \r{ho} shows a complex influence on the prediction accuracy and suggest a smaller spectral radius \r{ho} currently. By changing the initial flow depth of the dam break, we also obtained the conclusion that the prediction horizon of RC-ESN is larger than that of LSTM.
Learning Aligned Cross-Modal Representation for Generalized Zero-Shot Classification
Dec 24, 2021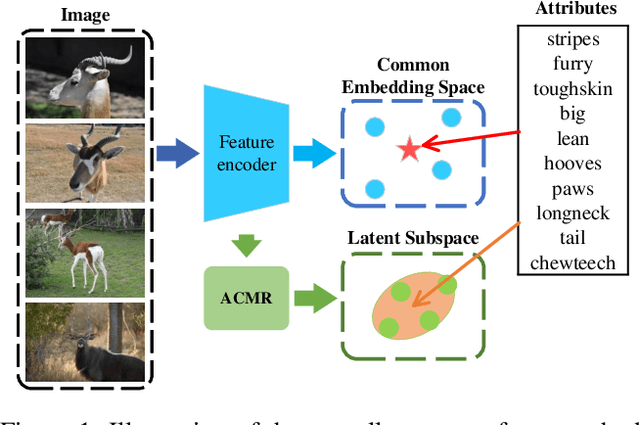
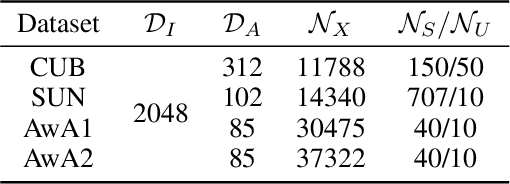
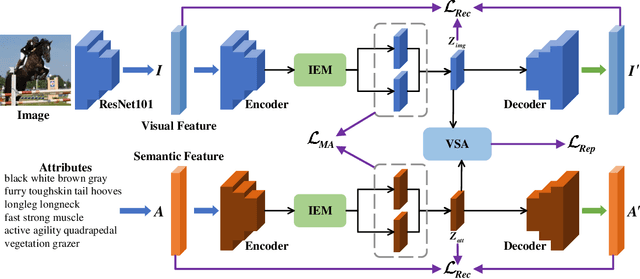
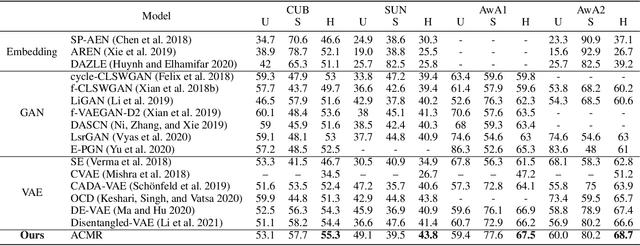
Learning a common latent embedding by aligning the latent spaces of cross-modal autoencoders is an effective strategy for Generalized Zero-Shot Classification (GZSC). However, due to the lack of fine-grained instance-wise annotations, it still easily suffer from the domain shift problem for the discrepancy between the visual representation of diversified images and the semantic representation of fixed attributes. In this paper, we propose an innovative autoencoder network by learning Aligned Cross-Modal Representations (dubbed ACMR) for GZSC. Specifically, we propose a novel Vision-Semantic Alignment (VSA) method to strengthen the alignment of cross-modal latent features on the latent subspaces guided by a learned classifier. In addition, we propose a novel Information Enhancement Module (IEM) to reduce the possibility of latent variables collapse meanwhile encouraging the discriminative ability of latent variables. Extensive experiments on publicly available datasets demonstrate the state-of-the-art performance of our method.
Primal-Dual Active-Set Methods for Isotonic Regression and Trend Filtering
Apr 03, 2016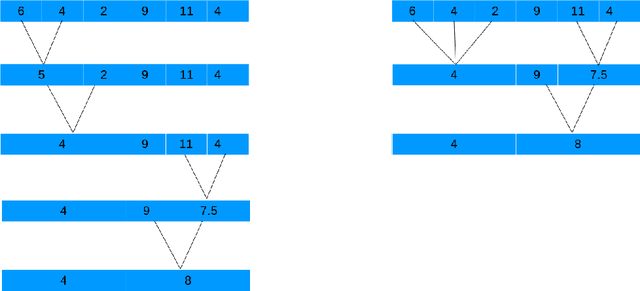

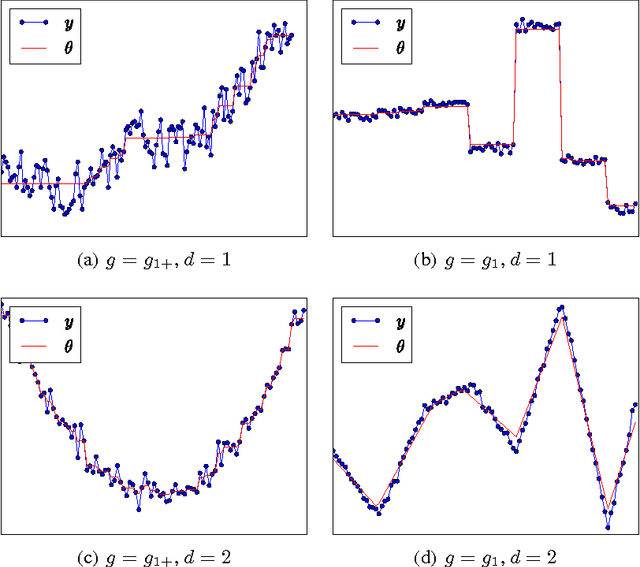

Isotonic regression (IR) is a non-parametric calibration method used in supervised learning. For performing large-scale IR, we propose a primal-dual active-set (PDAS) algorithm which, in contrast to the state-of-the-art Pool Adjacent Violators (PAV) algorithm, can be parallized and is easily warm-started thus well-suited in the online settings. We prove that, like the PAV algorithm, our PDAS algorithm for IR is convergent and has a work complexity of O(n), though our numerical experiments suggest that our PDAS algorithm is often faster than PAV. In addition, we propose PDAS variants (with safeguarding to ensure convergence) for solving related trend filtering (TF) problems, providing the results of experiments to illustrate their effectiveness.