 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMing-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025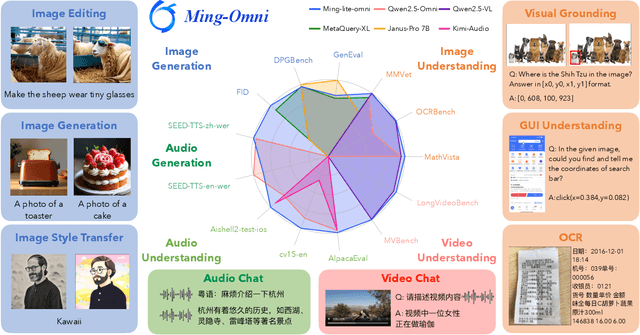
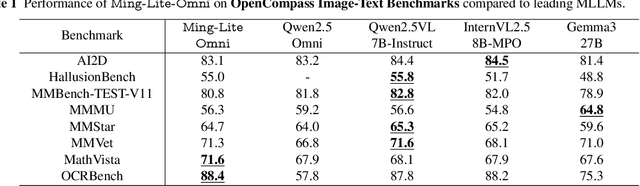
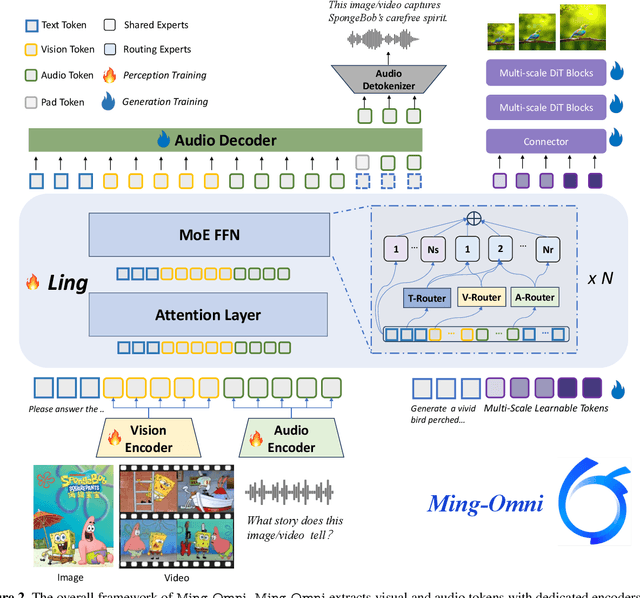
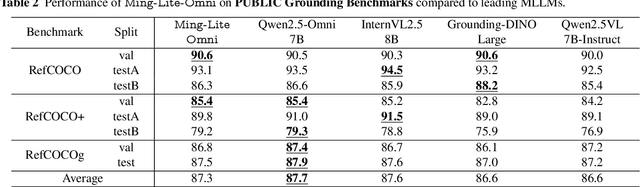
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
SegAgent: Exploring Pixel Understanding Capabilities in MLLMs by Imitating Human Annotator Trajectories
Mar 11, 2025While MLLMs have demonstrated adequate image understanding capabilities, they still struggle with pixel-level comprehension, limiting their practical applications. Current evaluation tasks like VQA and visual grounding remain too coarse to assess fine-grained pixel comprehension accurately. Though segmentation is foundational for pixel-level understanding, existing methods often require MLLMs to generate implicit tokens, decoded through external pixel decoders. This approach disrupts the MLLM's text output space, potentially compromising language capabilities and reducing flexibility and extensibility, while failing to reflect the model's intrinsic pixel-level understanding. Thus, we introduce the Human-Like Mask Annotation Task (HLMAT), a new paradigm where MLLMs mimic human annotators using interactive segmentation tools. Modeling segmentation as a multi-step Markov Decision Process, HLMAT enables MLLMs to iteratively generate text-based click points, achieving high-quality masks without architectural changes or implicit tokens. Through this setup, we develop SegAgent, a model fine-tuned on human-like annotation trajectories, which achieves performance comparable to state-of-the-art (SOTA) methods and supports additional tasks like mask refinement and annotation filtering. HLMAT provides a protocol for assessing fine-grained pixel understanding in MLLMs and introduces a vision-centric, multi-step decision-making task that facilitates exploration of MLLMs' visual reasoning abilities. Our adaptations of policy improvement method StaR and PRM-guided tree search further enhance model robustness in complex segmentation tasks, laying a foundation for future advancements in fine-grained visual perception and multi-step decision-making for MLLMs.
FADE: A Dataset for Detecting Falling Objects around Buildings in Video
Aug 11, 2024



Falling objects from buildings can cause severe injuries to pedestrians due to the great impact force they exert. Although surveillance cameras are installed around some buildings, it is challenging for humans to capture such events in surveillance videos due to the small size and fast motion of falling objects, as well as the complex background. Therefore, it is necessary to develop methods to automatically detect falling objects around buildings in surveillance videos. To facilitate the investigation of falling object detection, we propose a large, diverse video dataset called FADE (FAlling Object DEtection around Buildings) for the first time. FADE contains 1,881 videos from 18 scenes, featuring 8 falling object categories, 4 weather conditions, and 4 video resolutions. Additionally, we develop a new object detection method called FADE-Net, which effectively leverages motion information and produces small-sized but high-quality proposals for detecting falling objects around buildings. Importantly, our method is extensively evaluated and analyzed by comparing it with the previous approaches used for generic object detection, video object detection, and moving object detection on the FADE dataset. Experimental results show that the proposed FADE-Net significantly outperforms other methods, providing an effective baseline for future research. The dataset and code are publicly available at https://fadedataset.github.io/FADE.github.io/.
M2-RAAP: A Multi-Modal Recipe for Advancing Adaptation-based Pre-training towards Effective and Efficient Zero-shot Video-text Retrieval
Jan 31, 2024



We present a Multi-Modal Recipe for Advancing Adaptation-based Pre-training towards effective and efficient zero-shot video-text retrieval, dubbed M2-RAAP. Upon popular image-text models like CLIP, most current adaptation-based video-text pre-training methods are confronted by three major issues, i.e., noisy data corpus, time-consuming pre-training, and limited performance gain. Towards this end, we conduct a comprehensive study including four critical steps in video-text pre-training. Specifically, we investigate 1) data filtering and refinement, 2) video input type selection, 3) temporal modeling, and 4) video feature enhancement. We then summarize this empirical study into the M2-RAAP recipe, where our technical contributions lie in 1) the data filtering and text re-writing pipeline resulting in 1M high-quality bilingual video-text pairs, 2) the replacement of video inputs with key-frames to accelerate pre-training, and 3) the Auxiliary-Caption-Guided (ACG) strategy to enhance video features. We conduct extensive experiments by adapting three image-text foundation models on two refined video-text datasets from different languages, validating the robustness and reproducibility of M2-RAAP for adaptation-based pre-training. Results demonstrate that M2-RAAP yields superior performance with significantly reduced data (-90%) and time consumption (-95%), establishing a new SOTA on four English zero-shot retrieval datasets and two Chinese ones. We are preparing our refined bilingual data annotations and codebase, which will be available at https://github.com/alipay/Ant-Multi-Modal-Framework/tree/main/prj/M2_RAAP.
SOAR: Scene-debiasing Open-set Action Recognition
Sep 03, 2023



Deep learning models have a risk of utilizing spurious clues to make predictions, such as recognizing actions based on the background scene. This issue can severely degrade the open-set action recognition performance when the testing samples have different scene distributions from the training samples. To mitigate this problem, we propose a novel method, called Scene-debiasing Open-set Action Recognition (SOAR), which features an adversarial scene reconstruction module and an adaptive adversarial scene classification module. The former prevents the decoder from reconstructing the video background given video features, and thus helps reduce the background information in feature learning. The latter aims to confuse scene type classification given video features, with a specific emphasis on the action foreground, and helps to learn scene-invariant information. In addition, we design an experiment to quantify the scene bias. The results indicate that the current open-set action recognizers are biased toward the scene, and our proposed SOAR method better mitigates such bias. Furthermore, our extensive experiments demonstrate that our method outperforms state-of-the-art methods, and the ablation studies confirm the effectiveness of our proposed modules.
EVE: Efficient zero-shot text-based Video Editing with Depth Map Guidance and Temporal Consistency Constraints
Aug 21, 2023



Motivated by the superior performance of image diffusion models, more and more researchers strive to extend these models to the text-based video editing task. Nevertheless, current video editing tasks mainly suffer from the dilemma between the high fine-tuning cost and the limited generation capacity. Compared with images, we conjecture that videos necessitate more constraints to preserve the temporal consistency during editing. Towards this end, we propose EVE, a robust and efficient zero-shot video editing method. Under the guidance of depth maps and temporal consistency constraints, EVE derives satisfactory video editing results with an affordable computational and time cost. Moreover, recognizing the absence of a publicly available video editing dataset for fair comparisons, we construct a new benchmark ZVE-50 dataset. Through comprehensive experimentation, we validate that EVE could achieve a satisfactory trade-off between performance and efficiency. We will release our dataset and codebase to facilitate future researchers.
Generalized Relation Modeling for Transformer Tracking
Apr 21, 2023



Compared with previous two-stream trackers, the recent one-stream tracking pipeline, which allows earlier interaction between the template and search region, has achieved a remarkable performance gain. However, existing one-stream trackers always let the template interact with all parts inside the search region throughout all the encoder layers. This could potentially lead to target-background confusion when the extracted feature representations are not sufficiently discriminative. To alleviate this issue, we propose a generalized relation modeling method based on adaptive token division. The proposed method is a generalized formulation of attention-based relation modeling for Transformer tracking, which inherits the merits of both previous two-stream and one-stream pipelines whilst enabling more flexible relation modeling by selecting appropriate search tokens to interact with template tokens. An attention masking strategy and the Gumbel-Softmax technique are introduced to facilitate the parallel computation and end-to-end learning of the token division module. Extensive experiments show that our method is superior to the two-stream and one-stream pipelines and achieves state-of-the-art performance on six challenging benchmarks with a real-time running speed.
AiATrack: Attention in Attention for Transformer Visual Tracking
Jul 22, 2022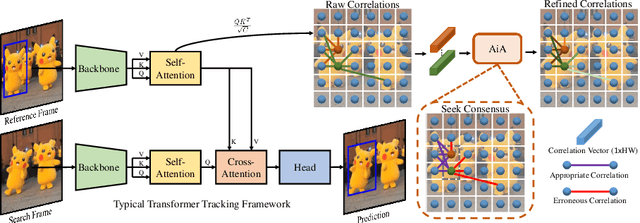
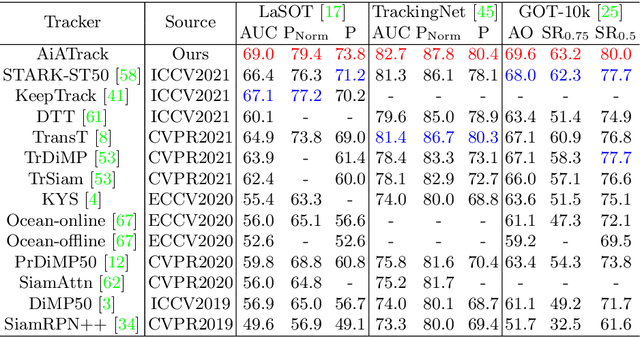
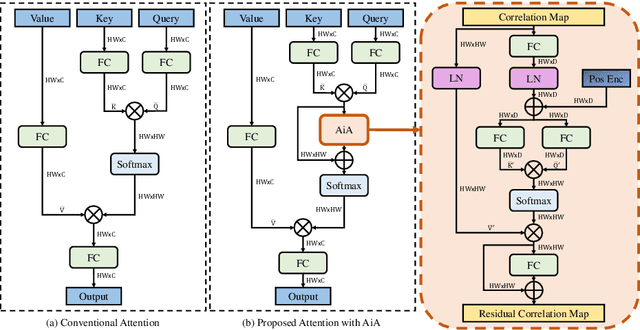
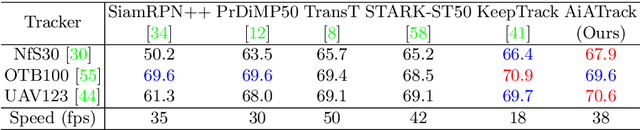
Transformer trackers have achieved impressive advancements recently, where the attention mechanism plays an important role. However, the independent correlation computation in the attention mechanism could result in noisy and ambiguous attention weights, which inhibits further performance improvement. To address this issue, we propose an attention in attention (AiA) module, which enhances appropriate correlations and suppresses erroneous ones by seeking consensus among all correlation vectors. Our AiA module can be readily applied to both self-attention blocks and cross-attention blocks to facilitate feature aggregation and information propagation for visual tracking. Moreover, we propose a streamlined Transformer tracking framework, dubbed AiATrack, by introducing efficient feature reuse and target-background embeddings to make full use of temporal references. Experiments show that our tracker achieves state-of-the-art performance on six tracking benchmarks while running at a real-time speed.
Distilling Inter-Class Distance for Semantic Segmentation
May 07, 2022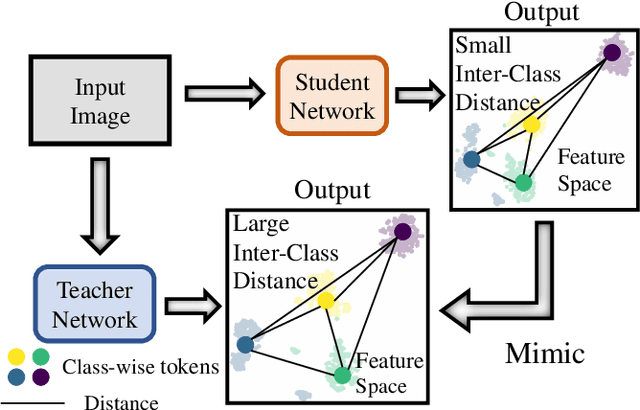
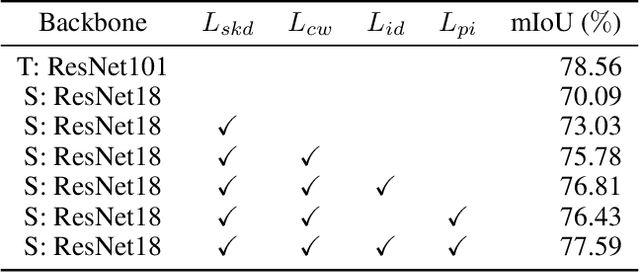
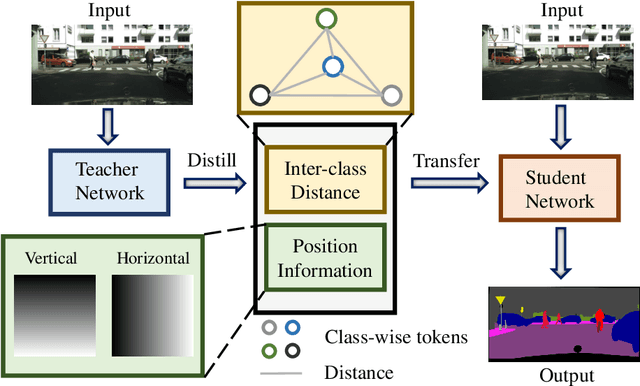
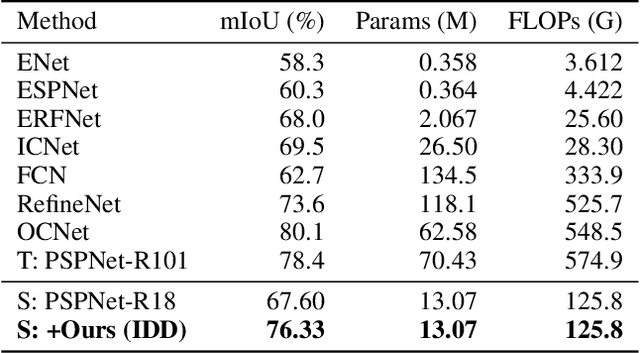
Knowledge distillation is widely adopted in semantic segmentation to reduce the computation cost.The previous knowledge distillation methods for semantic segmentation focus on pixel-wise feature alignment and intra-class feature variation distillation, neglecting to transfer the knowledge of the inter-class distance in the feature space, which is important for semantic segmentation. To address this issue, we propose an Inter-class Distance Distillation (IDD) method to transfer the inter-class distance in the feature space from the teacher network to the student network. Furthermore, semantic segmentation is a position-dependent task,thus we exploit a position information distillation module to help the student network encode more position information. Extensive experiments on three popular datasets: Cityscapes, Pascal VOC and ADE20K show that our method is helpful to improve the accuracy of semantic segmentation models and achieves the state-of-the-art performance. E.g. it boosts the benchmark model("PSPNet+ResNet18") by 7.50% in accuracy on the Cityscapes dataset.
Learning Dynamics via Graph Neural Networks for Human Pose Estimation and Tracking
Jun 07, 2021
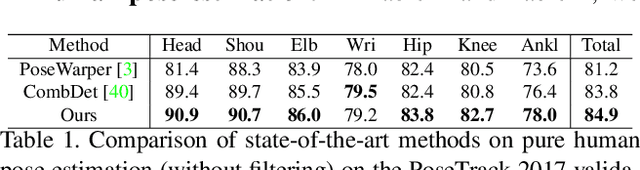
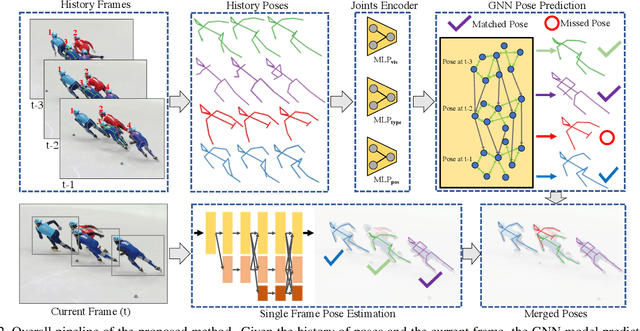
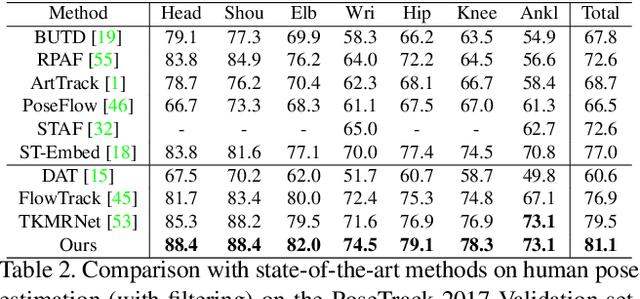
Multi-person pose estimation and tracking serve as crucial steps for video understanding. Most state-of-the-art approaches rely on first estimating poses in each frame and only then implementing data association and refinement. Despite the promising results achieved, such a strategy is inevitably prone to missed detections especially in heavily-cluttered scenes, since this tracking-by-detection paradigm is, by nature, largely dependent on visual evidences that are absent in the case of occlusion. In this paper, we propose a novel online approach to learning the pose dynamics, which are independent of pose detections in current fame, and hence may serve as a robust estimation even in challenging scenarios including occlusion. Specifically, we derive this prediction of dynamics through a graph neural network~(GNN) that explicitly accounts for both spatial-temporal and visual information. It takes as input the historical pose tracklets and directly predicts the corresponding poses in the following frame for each tracklet. The predicted poses will then be aggregated with the detected poses, if any, at the same frame so as to produce the final pose, potentially recovering the occluded joints missed by the estimator. Experiments on PoseTrack 2017 and PoseTrack 2018 datasets demonstrate that the proposed method achieves results superior to the state of the art on both human pose estimation and tracking tasks.