 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVividVoice: A Unified Framework for Scene-Aware Visually-Driven Speech Synthesis
Feb 01, 2026We introduce and define a novel task-Scene-Aware Visually-Driven Speech Synthesis, aimed at addressing the limitations of existing speech generation models in creating immersive auditory experiences that align with the real physical world. To tackle the two core challenges of data scarcity and modality decoupling, we propose VividVoice, a unified generative framework. First, we constructed a large-scale, high-quality hybrid multimodal dataset, Vivid-210K, which, through an innovative programmatic pipeline, establishes a strong correlation between visual scenes, speaker identity, and audio for the first time. Second, we designed a core alignment module, D-MSVA, which leverages a decoupled memory bank architecture and a cross-modal hybrid supervision strategy to achieve fine-grained alignment from visual scenes to timbre and environmental acoustic features. Both subjective and objective experimental results provide strong evidence that VividVoice significantly outperforms existing baseline models in terms of audio fidelity, content clarity, and multimodal consistency. Our demo is available at https://chengyuann.github.io/VividVoice/.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025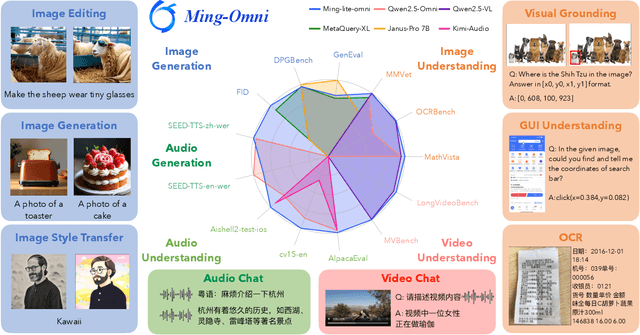
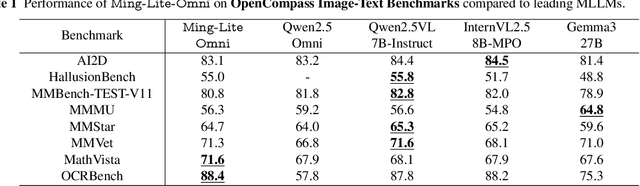
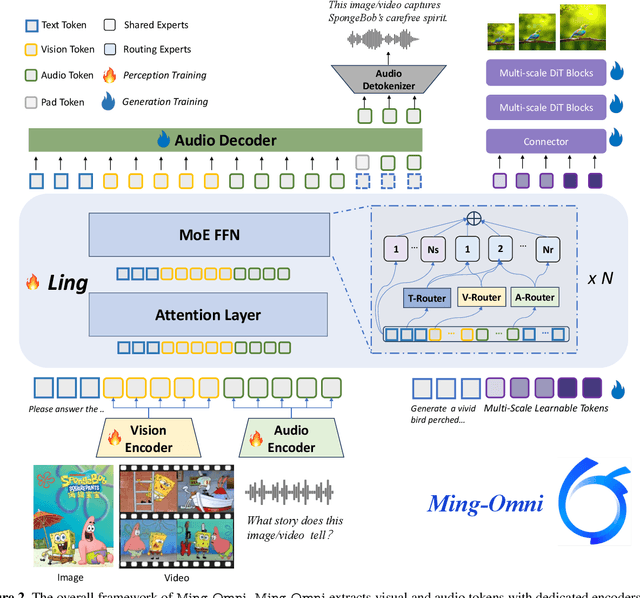
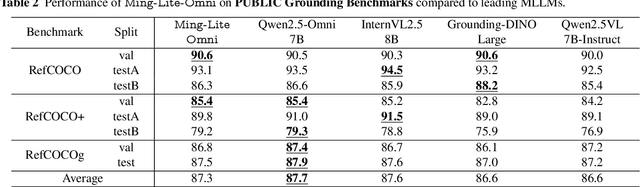
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Learning to Encode Evolutionary Knowledge for Automatic Commenting Long Novels
Apr 21, 2020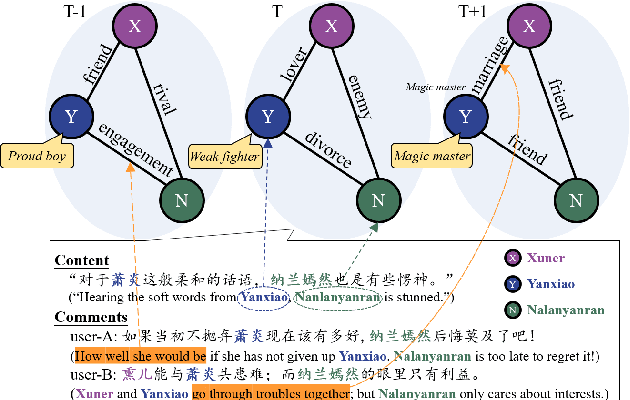
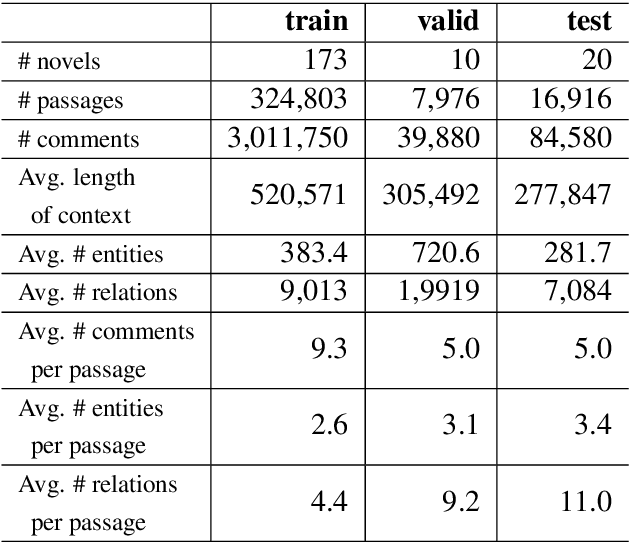
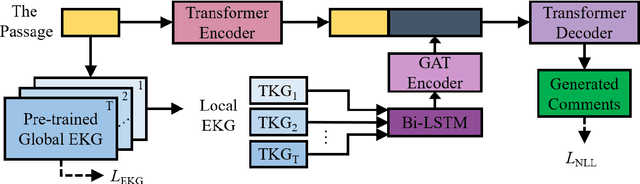
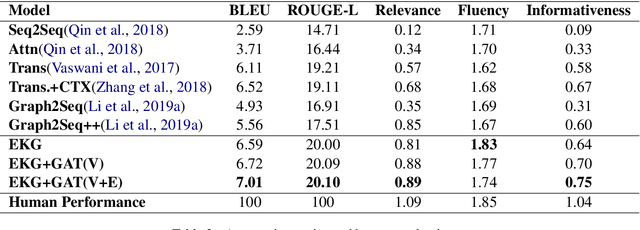
Static knowledge graph has been incorporated extensively into sequence-to-sequence framework for text generation. While effectively representing structured context, static knowledge graph failed to represent knowledge evolution, which is required in modeling dynamic events. In this paper, an automatic commenting task is proposed for long novels, which involves understanding context of more than tens of thousands of words. To model the dynamic storyline, especially the transitions of the characters and their relations, Evolutionary Knowledge Graph(EKG) is proposed and learned within a multi-task framework. Given a specific passage to comment, sequential modeling is used to incorporate historical and future embedding for context representation. Further, a graph-to-sequence model is designed to utilize the EKG for comment generation. Extensive experimental results show that our EKG-based method is superior to several strong baselines on both automatic and human evaluations.