 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphPO: Graph-based Policy Optimization for Reasoning Models
Jun 17, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a standard paradigm for enhancing the capability of large reasoning models. RLVR typically samples responses independently and optimizes the policy using from final answers. This paradigm has two limitations. First, independently responses often contain similar intermediate reasoning steps, causing redundant exploration and wasted computation. Second, sparse final-answer rewards make it hard to identify useful steps. Tree-based methods partly address this problem by sharing prefixes and comparing branches from the same prefix to provide fine-grained signals. However, tree branches are still expanded independently. When different branches reach similar reasoning states, they cannot share information and repeat similar exploration. Moreover, tree-based methods ignore such dispersion and only perform local comparisons within separate branches, which can lead to higher variance in advantage estimation. To address this challenge, we propose GraphPO (Graph-based Policy Optimization), a novel RL framework that represents rollouts as a directed acyclic graph, with reasoning steps as edges and semantic states summarized from the reasoning paths as nodes. GraphPO merges semantically equivalent reasoning paths into equivalence classes, allowing them to share suffixes and reallocating budget away from redundant expansions to diverse exploration. Furthermore, we assign efficiency advantages to incoming edges and correctness advantages to outgoing edges, thereby improving inference efficiency while deriving process supervision from outcome. Theory shows that GraphPO reduces advantage-estimation variance and enhances reasoning efficiency. Experiments on three LLMs across reasoning and agentic search benchmarks show that GraphPO consistently outperforms chain- and tree-based baselines with the same token budgets or response budgets.
Perceptual Flow Network for Visually Grounded Reasoning
May 04, 2026Despite the success of Large-Vision Language Models (LVLMs), general optimization objectives (e.g., standard MLE) fail to constrain visual trajectories, leading to language bias and hallucination. To mitigate this, current methods introduce geometric priors from visual experts as additional supervision. However, we observe that such supervision is typically suboptimal: it is biased toward geometric precision and offers limited reasoning utility. To bridge this gap, we propose Perceptual Flow Network (PFlowNet), which eschews rigid alignment with the expert priors and achieves interpretable yet more effective visual reasoning. Specifically, PFlowNet decouples perception from reasoning to establish a self-conditioned generation process. Based on this, it integrates multi-dimensional rewards with vicinal geometric shaping via variational reinforcement learning, thereby facilitating reasoning-oriented perceptual behaviors while preserving visual reliability. PFlowNet delivers a provable performance guarantee and competitive empirical results, particularly setting new SOTA records on V* Bench (90.6%) and MME-RealWorld-lite (67.0%).
TC-AE: Unlocking Token Capacity for Deep Compression Autoencoders
Apr 08, 2026We propose TC-AE, a ViT-based architecture for deep compression autoencoders. Existing methods commonly increase the channel number of latent representations to maintain reconstruction quality under high compression ratios. However, this strategy often leads to latent representation collapse, which degrades generative performance. Instead of relying on increasingly complex architectures or multi-stage training schemes, TC-AE addresses this challenge from the perspective of the token space, the key bridge between pixels and image latents, through two complementary innovations: Firstly, we study token number scaling by adjusting the patch size in ViT under a fixed latent budget, and identify aggressive token-to-latent compression as the key factor that limits effective scaling. To address this issue, we decompose token-to-latent compression into two stages, reducing structural information loss and enabling effective token number scaling for generation. Secondly, to further mitigate latent representation collapse, we enhance the semantic structure of image tokens via joint self-supervised training, leading to more generative-friendly latents. With these designs, TC-AE achieves substantially improved reconstruction and generative performance under deep compression. We hope our research will advance ViT-based tokenizer for visual generation.
TriC-Motion: Tri-Domain Causal Modeling Grounded Text-to-Motion Generation
Feb 09, 2026Text-to-motion generation, a rapidly evolving field in computer vision, aims to produce realistic and text-aligned motion sequences. Current methods primarily focus on spatial-temporal modeling or independent frequency domain analysis, lacking a unified framework for joint optimization across spatial, temporal, and frequency domains. This limitation hinders the model's ability to leverage information from all domains simultaneously, leading to suboptimal generation quality. Additionally, in motion generation frameworks, motion-irrelevant cues caused by noise are often entangled with features that contribute positively to generation, thereby leading to motion distortion. To address these issues, we propose Tri-Domain Causal Text-to-Motion Generation (TriC-Motion), a novel diffusion-based framework integrating spatial-temporal-frequency-domain modeling with causal intervention. TriC-Motion includes three core modeling modules for domain-specific modeling, namely Temporal Motion Encoding, Spatial Topology Modeling, and Hybrid Frequency Analysis. After comprehensive modeling, a Score-guided Tri-domain Fusion module integrates valuable information from the triple domains, simultaneously ensuring temporal consistency, spatial topology, motion trends, and dynamics. Moreover, the Causality-based Counterfactual Motion Disentangler is meticulously designed to expose motion-irrelevant cues to eliminate noise, disentangling the real modeling contributions of each domain for superior generation. Extensive experimental results validate that TriC-Motion achieves superior performance compared to state-of-the-art methods, attaining an outstanding R@1 of 0.612 on the HumanML3D dataset. These results demonstrate its capability to generate high-fidelity, coherent, diverse, and text-aligned motion sequences. Code is available at: https://caoyiyang1105.github.io/TriC-Motion/.
GO-MLVTON: Garment Occlusion-Aware Multi-Layer Virtual Try-On with Diffusion Models
Jan 20, 2026Existing Image-based virtual try-on (VTON) methods primarily focus on single-layer or multi-garment VTON, neglecting multi-layer VTON (ML-VTON), which involves dressing multiple layers of garments onto the human body with realistic deformation and layering to generate visually plausible outcomes. The main challenge lies in accurately modeling occlusion relationships between inner and outer garments to reduce interference from redundant inner garment features. To address this, we propose GO-MLVTON, the first multi-layer VTON method, introducing the Garment Occlusion Learning module to learn occlusion relationships and the StableDiffusion-based Garment Morphing & Fitting module to deform and fit garments onto the human body, producing high-quality multi-layer try-on results. Additionally, we present the MLG dataset for this task and propose a new metric named Layered Appearance Coherence Difference (LACD) for evaluation. Extensive experiments demonstrate the state-of-the-art performance of GO-MLVTON. Project page: https://upyuyang.github.io/go-mlvton/.
3SGen: Unified Subject, Style, and Structure-Driven Image Generation with Adaptive Task-specific Memory
Dec 22, 2025



Recent image generation approaches often address subject, style, and structure-driven conditioning in isolation, leading to feature entanglement and limited task transferability. In this paper, we introduce 3SGen, a task-aware unified framework that performs all three conditioning modes within a single model. 3SGen employs an MLLM equipped with learnable semantic queries to align text-image semantics, complemented by a VAE branch that preserves fine-grained visual details. At its core, an Adaptive Task-specific Memory (ATM) module dynamically disentangles, stores, and retrieves condition-specific priors, such as identity for subjects, textures for styles, and spatial layouts for structures, via a lightweight gating mechanism along with several scalable memory items. This design mitigates inter-task interference and naturally scales to compositional inputs. In addition, we propose 3SGen-Bench, a unified image-driven generation benchmark with standardized metrics for evaluating cross-task fidelity and controllability. Extensive experiments on our proposed 3SGen-Bench and other public benchmarks demonstrate our superior performance across diverse image-driven generation tasks.
ARGenSeg: Image Segmentation with Autoregressive Image Generation Model
Oct 23, 2025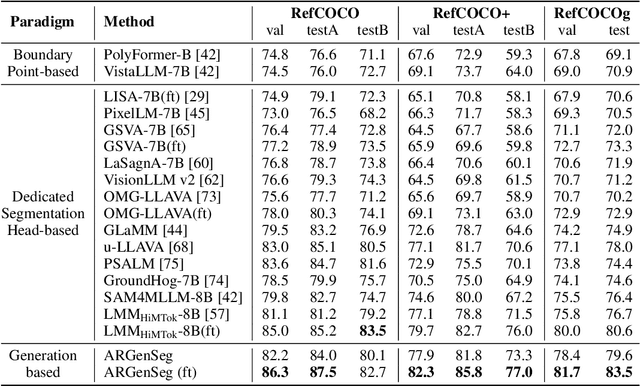
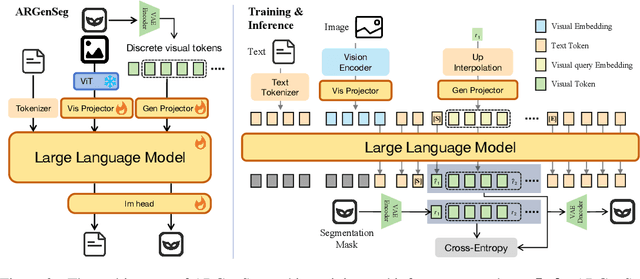


We propose a novel AutoRegressive Generation-based paradigm for image Segmentation (ARGenSeg), achieving multimodal understanding and pixel-level perception within a unified framework. Prior works integrating image segmentation into multimodal large language models (MLLMs) typically employ either boundary points representation or dedicated segmentation heads. These methods rely on discrete representations or semantic prompts fed into task-specific decoders, which limits the ability of the MLLM to capture fine-grained visual details. To address these challenges, we introduce a segmentation framework for MLLM based on image generation, which naturally produces dense masks for target objects. We leverage MLLM to output visual tokens and detokenize them into images using an universal VQ-VAE, making the segmentation fully dependent on the pixel-level understanding of the MLLM. To reduce inference latency, we employ a next-scale-prediction strategy to generate required visual tokens in parallel. Extensive experiments demonstrate that our method surpasses prior state-of-the-art approaches on multiple segmentation datasets with a remarkable boost in inference speed, while maintaining strong understanding capabilities.
PruneHal: Reducing Hallucinations in Multi-modal Large Language Models through Adaptive KV Cache Pruning
Oct 22, 2025While multi-modal large language models (MLLMs) have made significant progress in recent years, the issue of hallucinations remains a major challenge. To mitigate this phenomenon, existing solutions either introduce additional data for further training or incorporate external or internal information during inference. However, these approaches inevitably introduce extra computational costs. In this paper, we observe that hallucinations in MLLMs are strongly associated with insufficient attention allocated to visual tokens. In particular, the presence of redundant visual tokens disperses the model's attention, preventing it from focusing on the most informative ones. As a result, critical visual cues are often under-attended, which in turn exacerbates the occurrence of hallucinations. Building on this observation, we propose \textbf{PruneHal}, a training-free, simple yet effective method that leverages adaptive KV cache pruning to enhance the model's focus on critical visual information, thereby mitigating hallucinations. To the best of our knowledge, we are the first to apply token pruning for hallucination mitigation in MLLMs. Notably, our method don't require additional training and incurs nearly no extra inference cost. Moreover, PruneHal is model-agnostic and can be seamlessly integrated with different decoding strategies, including those specifically designed for hallucination mitigation. We evaluate PruneHal on several widely used hallucination evaluation benchmarks using four mainstream MLLMs, achieving robust and outstanding results that highlight the effectiveness and superiority of our method. Our code will be publicly available.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025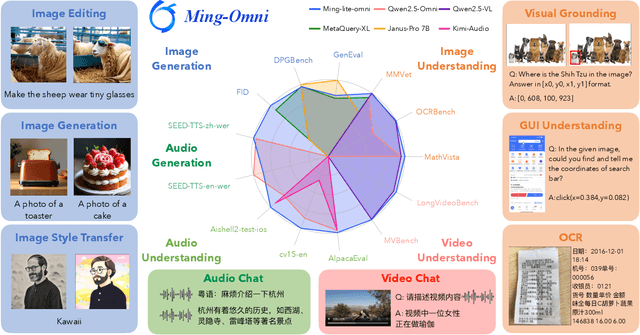
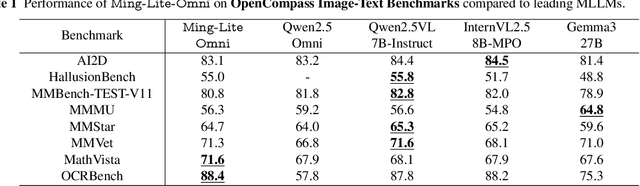
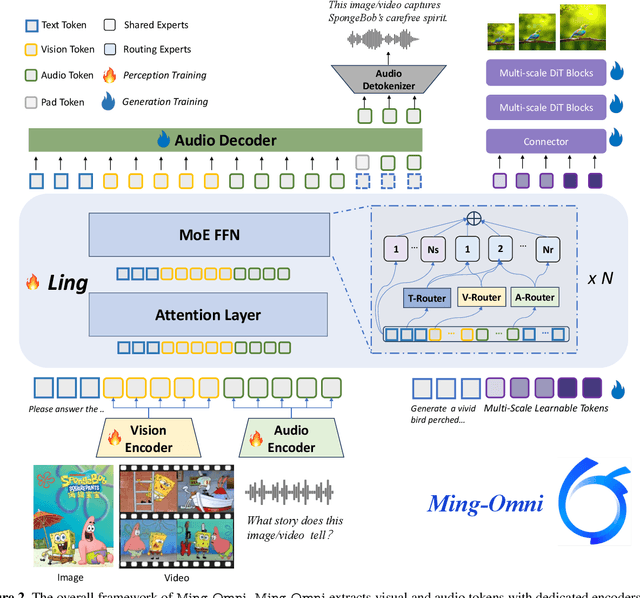
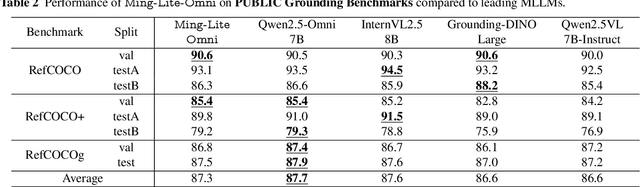
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Ming-Lite-Uni: Advancements in Unified Architecture for Natural Multimodal Interaction
May 05, 2025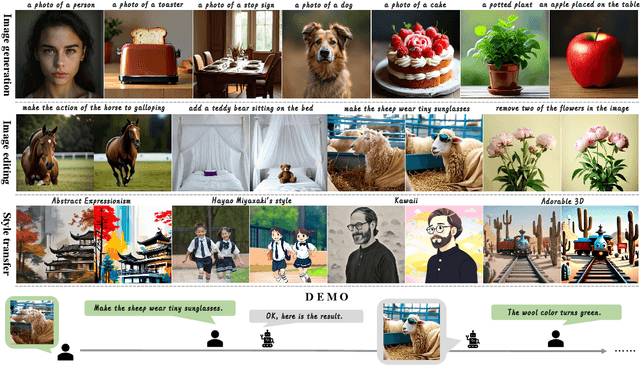

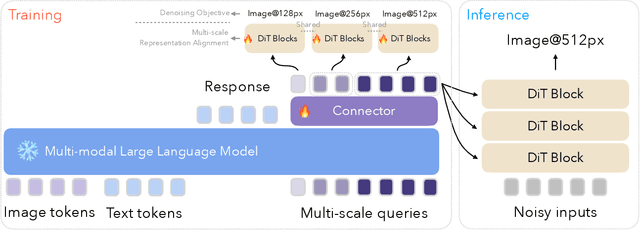
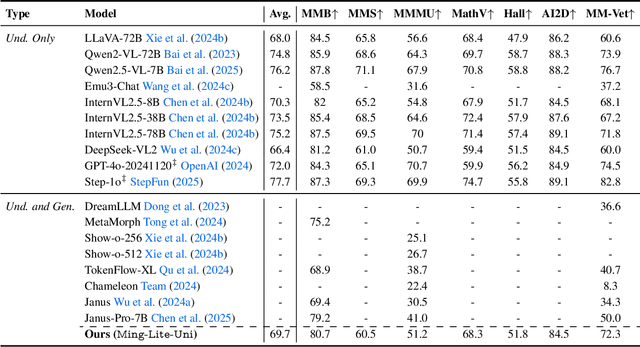
We introduce Ming-Lite-Uni, an open-source multimodal framework featuring a newly designed unified visual generator and a native multimodal autoregressive model tailored for unifying vision and language. Specifically, this project provides an open-source implementation of the integrated MetaQueries and M2-omni framework, while introducing the novel multi-scale learnable tokens and multi-scale representation alignment strategy. By leveraging a fixed MLLM and a learnable diffusion model, Ming-Lite-Uni enables native multimodal AR models to perform both text-to-image generation and instruction based image editing tasks, expanding their capabilities beyond pure visual understanding. Our experimental results demonstrate the strong performance of Ming-Lite-Uni and illustrate the impressive fluid nature of its interactive process. All code and model weights are open-sourced to foster further exploration within the community. Notably, this work aligns with concurrent multimodal AI milestones - such as ChatGPT-4o with native image generation updated in March 25, 2025 - underscoring the broader significance of unified models like Ming-Lite-Uni on the path toward AGI. Ming-Lite-Uni is in alpha stage and will soon be further refined.