 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCR-Router: Efficient Role-Aware Context Routing for Multi-Agent LLM Systems with Structured Memory
Aug 06, 2025Multi-agent large language model (LLM) systems have shown strong potential in complex reasoning and collaborative decision-making tasks. However, most existing coordination schemes rely on static or full-context routing strategies, which lead to excessive token consumption, redundant memory exposure, and limited adaptability across interaction rounds. We introduce RCR-Router, a modular and role-aware context routing framework designed to enable efficient, adaptive collaboration in multi-agent LLMs. To our knowledge, this is the first routing approach that dynamically selects semantically relevant memory subsets for each agent based on its role and task stage, while adhering to a strict token budget. A lightweight scoring policy guides memory selection, and agent outputs are iteratively integrated into a shared memory store to facilitate progressive context refinement. To better evaluate model behavior, we further propose an Answer Quality Score metric that captures LLM-generated explanations beyond standard QA accuracy. Experiments on three multi-hop QA benchmarks -- HotPotQA, MuSiQue, and 2WikiMultihop -- demonstrate that RCR-Router reduces token usage (up to 30%) while improving or maintaining answer quality. These results highlight the importance of structured memory routing and output-aware evaluation in advancing scalable multi-agent LLM systems.
Modality-Aware Feature Matching: A Comprehensive Review of Single- and Cross-Modality Techniques
Jul 30, 2025



Feature matching is a cornerstone task in computer vision, essential for applications such as image retrieval, stereo matching, 3D reconstruction, and SLAM. This survey comprehensively reviews modality-based feature matching, exploring traditional handcrafted methods and emphasizing contemporary deep learning approaches across various modalities, including RGB images, depth images, 3D point clouds, LiDAR scans, medical images, and vision-language interactions. Traditional methods, leveraging detectors like Harris corners and descriptors such as SIFT and ORB, demonstrate robustness under moderate intra-modality variations but struggle with significant modality gaps. Contemporary deep learning-based methods, exemplified by detector-free strategies like CNN-based SuperPoint and transformer-based LoFTR, substantially improve robustness and adaptability across modalities. We highlight modality-aware advancements, such as geometric and depth-specific descriptors for depth images, sparse and dense learning methods for 3D point clouds, attention-enhanced neural networks for LiDAR scans, and specialized solutions like the MIND descriptor for complex medical image matching. Cross-modal applications, particularly in medical image registration and vision-language tasks, underscore the evolution of feature matching to handle increasingly diverse data interactions.
Recognizing Actions from Robotic View for Natural Human-Robot Interaction
Jul 30, 2025



Natural Human-Robot Interaction (N-HRI) requires robots to recognize human actions at varying distances and states, regardless of whether the robot itself is in motion or stationary. This setup is more flexible and practical than conventional human action recognition tasks. However, existing benchmarks designed for traditional action recognition fail to address the unique complexities in N-HRI due to limited data, modalities, task categories, and diversity of subjects and environments. To address these challenges, we introduce ACTIVE (Action from Robotic View), a large-scale dataset tailored specifically for perception-centric robotic views prevalent in mobile service robots. ACTIVE comprises 30 composite action categories, 80 participants, and 46,868 annotated video instances, covering both RGB and point cloud modalities. Participants performed various human actions in diverse environments at distances ranging from 3m to 50m, while the camera platform was also mobile, simulating real-world scenarios of robot perception with varying camera heights due to uneven ground. This comprehensive and challenging benchmark aims to advance action and attribute recognition research in N-HRI. Furthermore, we propose ACTIVE-PC, a method that accurately perceives human actions at long distances using Multilevel Neighborhood Sampling, Layered Recognizers, Elastic Ellipse Query, and precise decoupling of kinematic interference from human actions. Experimental results demonstrate the effectiveness of ACTIVE-PC. Our code is available at: https://github.com/wangzy01/ACTIVE-Action-from-Robotic-View.
Pro-AD: Learning Comprehensive Prototypes with Prototype-based Constraint for Multi-class Unsupervised Anomaly Detection
Jun 16, 2025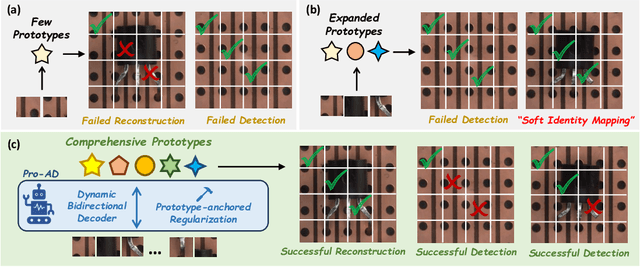

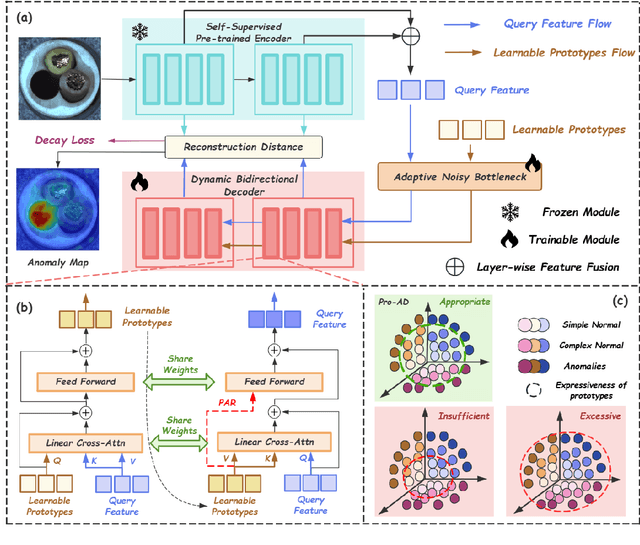

Prototype-based reconstruction methods for unsupervised anomaly detection utilize a limited set of learnable prototypes which only aggregates insufficient normal information, resulting in undesirable reconstruction. However, increasing the number of prototypes may lead to anomalies being well reconstructed through the attention mechanism, which we refer to as the "Soft Identity Mapping" problem. In this paper, we propose Pro-AD to address these issues and fully utilize the prototypes to boost the performance of anomaly detection. Specifically, we first introduce an expanded set of learnable prototypes to provide sufficient capacity for semantic information. Then we employ a Dynamic Bidirectional Decoder which integrates the process of the normal information aggregation and the target feature reconstruction via prototypes, with the aim of allowing the prototypes to aggregate more comprehensive normal semantic information from different levels of the image features and the target feature reconstruction to not only utilize its contextual information but also dynamically leverage the learned comprehensive prototypes. Additionally, to prevent the anomalies from being well reconstructed using sufficient semantic information through the attention mechanism, Pro-AD introduces a Prototype-based Constraint that applied within the target feature reconstruction process of the decoder, which further improves the performance of our approach. Extensive experiments on multiple challenging benchmarks demonstrate that our Pro-AD achieve state-of-the-art performance, highlighting its superior robustness and practical effectiveness for Multi-class Unsupervised Anomaly Detection task.
Rethinking Range-View LiDAR Segmentation in Adverse Weather
Jun 10, 2025



LiDAR segmentation has emerged as an important task to enrich multimedia experiences and analysis. Range-view-based methods have gained popularity due to their high computational efficiency and compatibility with real-time deployment. However, their generalized performance under adverse weather conditions remains underexplored, limiting their reliability in real-world environments. In this work, we identify and analyze the unique challenges that affect the generalization of range-view LiDAR segmentation in severe weather. To address these challenges, we propose a modular and lightweight framework that enhances robustness without altering the core architecture of existing models. Our method reformulates the initial stem block of standard range-view networks into two branches to process geometric attributes and reflectance intensity separately. Specifically, a Geometric Abnormality Suppression (GAS) module reduces the influence of weather-induced spatial noise, and a Reflectance Distortion Calibration (RDC) module corrects reflectance distortions through memory-guided adaptive instance normalization. The processed features are then fused and passed to the original segmentation pipeline. Extensive experiments on different benchmarks and baseline models demonstrate that our approach significantly improves generalization to adverse weather with minimal inference overhead, offering a practical and effective solution for real-world LiDAR segmentation.
COM Adjustment Mechanism Control for Multi-Configuration Motion Stability of Unmanned Deformable Vehicle
May 27, 2025An unmanned deformable vehicle is a wheel-legged robot transforming between two configurations: vehicular and humanoid states, with different motion modes and stability characteristics. To address motion stability in multiple configurations, a center-of-mass adjustment mechanism was designed. Further, a motion stability hierarchical control algorithm was proposed, and an electromechanical model based on a two-degree-of-freedom center-of-mass adjustment mechanism was established. An unmanned-deformable-vehicle vehicular-state steady-state steering dynamics model and a gait planning kinematic model of humanoid state walking were established. A stability hierarchical control strategy was designed to realize the stability control. The results showed that the steady-state steering stability in vehicular state and the walking stability in humanoid state could be significantly improved by controlling the slider motion.
LMCD: Language Models are Zeroshot Cognitive Diagnosis Learners
May 27, 2025Cognitive Diagnosis (CD) has become a critical task in AI-empowered education, supporting personalized learning by accurately assessing students' cognitive states. However, traditional CD models often struggle in cold-start scenarios due to the lack of student-exercise interaction data. Recent NLP-based approaches leveraging pre-trained language models (PLMs) have shown promise by utilizing textual features but fail to fully bridge the gap between semantic understanding and cognitive profiling. In this work, we propose Language Models as Zeroshot Cognitive Diagnosis Learners (LMCD), a novel framework designed to handle cold-start challenges by harnessing large language models (LLMs). LMCD operates via two primary phases: (1) Knowledge Diffusion, where LLMs generate enriched contents of exercises and knowledge concepts (KCs), establishing stronger semantic links; and (2) Semantic-Cognitive Fusion, where LLMs employ causal attention mechanisms to integrate textual information and student cognitive states, creating comprehensive profiles for both students and exercises. These representations are efficiently trained with off-the-shelf CD models. Experiments on two real-world datasets demonstrate that LMCD significantly outperforms state-of-the-art methods in both exercise-cold and domain-cold settings. The code is publicly available at https://github.com/TAL-auroraX/LMCD
ChartSketcher: Reasoning with Multimodal Feedback and Reflection for Chart Understanding
May 25, 2025Charts are high-density visualization carriers for complex data, serving as a crucial medium for information extraction and analysis. Automated chart understanding poses significant challenges to existing multimodal large language models (MLLMs) due to the need for precise and complex visual reasoning. Current step-by-step reasoning models primarily focus on text-based logical reasoning for chart understanding. However, they struggle to refine or correct their reasoning when errors stem from flawed visual understanding, as they lack the ability to leverage multimodal interaction for deeper comprehension. Inspired by human cognitive behavior, we propose ChartSketcher, a multimodal feedback-driven step-by-step reasoning method designed to address these limitations. ChartSketcher is a chart understanding model that employs Sketch-CoT, enabling MLLMs to annotate intermediate reasoning steps directly onto charts using a programmatic sketching library, iteratively feeding these visual annotations back into the reasoning process. This mechanism enables the model to visually ground its reasoning and refine its understanding over multiple steps. We employ a two-stage training strategy: a cold start phase to learn sketch-based reasoning patterns, followed by off-policy reinforcement learning to enhance reflection and generalization. Experiments demonstrate that ChartSketcher achieves promising performance on chart understanding benchmarks and general vision tasks, providing an interactive and interpretable approach to chart comprehension.
Deliberation on Priors: Trustworthy Reasoning of Large Language Models on Knowledge Graphs
May 21, 2025Knowledge graph-based retrieval-augmented generation seeks to mitigate hallucinations in Large Language Models (LLMs) caused by insufficient or outdated knowledge. However, existing methods often fail to fully exploit the prior knowledge embedded in knowledge graphs (KGs), particularly their structural information and explicit or implicit constraints. The former can enhance the faithfulness of LLMs' reasoning, while the latter can improve the reliability of response generation. Motivated by these, we propose a trustworthy reasoning framework, termed Deliberation over Priors (DP), which sufficiently utilizes the priors contained in KGs. Specifically, DP adopts a progressive knowledge distillation strategy that integrates structural priors into LLMs through a combination of supervised fine-tuning and Kahneman-Tversky optimization, thereby improving the faithfulness of relation path generation. Furthermore, our framework employs a reasoning-introspection strategy, which guides LLMs to perform refined reasoning verification based on extracted constraint priors, ensuring the reliability of response generation. Extensive experiments on three benchmark datasets demonstrate that DP achieves new state-of-the-art performance, especially a Hit@1 improvement of 13% on the ComplexWebQuestions dataset, and generates highly trustworthy responses. We also conduct various analyses to verify its flexibility and practicality. The code is available at https://github.com/reml-group/Deliberation-on-Priors.
Structured Agent Distillation for Large Language Model
May 20, 2025
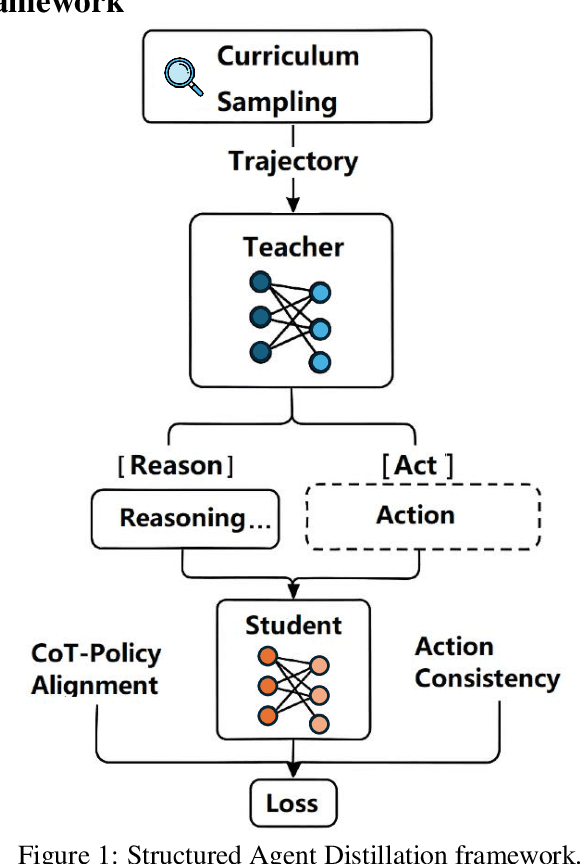

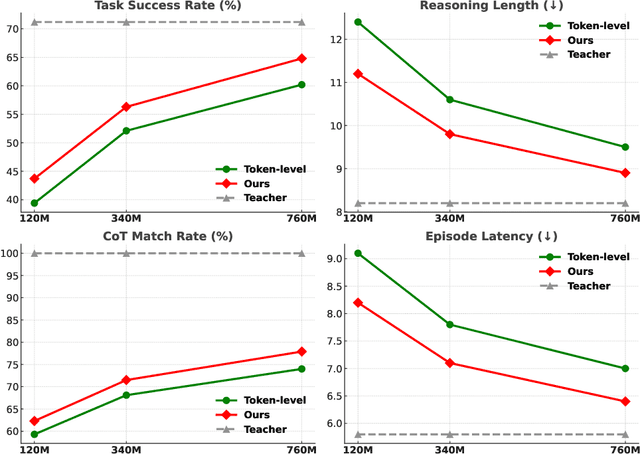
Large language models (LLMs) exhibit strong capabilities as decision-making agents by interleaving reasoning and actions, as seen in ReAct-style frameworks. Yet, their practical deployment is constrained by high inference costs and large model sizes. We propose Structured Agent Distillation, a framework that compresses large LLM-based agents into smaller student models while preserving both reasoning fidelity and action consistency. Unlike standard token-level distillation, our method segments trajectories into {[REASON]} and {[ACT]} spans, applying segment-specific losses to align each component with the teacher's behavior. This structure-aware supervision enables compact agents to better replicate the teacher's decision process. Experiments on ALFWorld, HotPotQA-ReAct, and WebShop show that our approach consistently outperforms token-level and imitation learning baselines, achieving significant compression with minimal performance drop. Scaling and ablation results further highlight the importance of span-level alignment for efficient and deployable agents.