 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Parameters Matter: Masking Diffusion Models for Enhancing Generation Ability
May 06, 2025



The diffusion models, in early stages focus on constructing basic image structures, while the refined details, including local features and textures, are generated in later stages. Thus the same network layers are forced to learn both structural and textural information simultaneously, significantly differing from the traditional deep learning architectures (e.g., ResNet or GANs) which captures or generates the image semantic information at different layers. This difference inspires us to explore the time-wise diffusion models. We initially investigate the key contributions of the U-Net parameters to the denoising process and identify that properly zeroing out certain parameters (including large parameters) contributes to denoising, substantially improving the generation quality on the fly. Capitalizing on this discovery, we propose a simple yet effective method-termed ``MaskUNet''- that enhances generation quality with negligible parameter numbers. Our method fully leverages timestep- and sample-dependent effective U-Net parameters. To optimize MaskUNet, we offer two fine-tuning strategies: a training-based approach and a training-free approach, including tailored networks and optimization functions. In zero-shot inference on the COCO dataset, MaskUNet achieves the best FID score and further demonstrates its effectiveness in downstream task evaluations. Project page: https://gudaochangsheng.github.io/MaskUnet-Page/
A Survey on Progress in LLM Alignment from the Perspective of Reward Design
May 05, 2025The alignment of large language models (LLMs) with human values and intentions represents a core challenge in current AI research, where reward mechanism design has become a critical factor in shaping model behavior. This study conducts a comprehensive investigation of reward mechanisms in LLM alignment through a systematic theoretical framework, categorizing their development into three key phases: (1) feedback (diagnosis), (2) reward design (prescription), and (3) optimization (treatment). Through a four-dimensional analysis encompassing construction basis, format, expression, and granularity, this research establishes a systematic classification framework that reveals evolutionary trends in reward modeling. The field of LLM alignment faces several persistent challenges, while recent advances in reward design are driving significant paradigm shifts. Notable developments include the transition from reinforcement learning-based frameworks to novel optimization paradigms, as well as enhanced capabilities to address complex alignment scenarios involving multimodal integration and concurrent task coordination. Finally, this survey outlines promising future research directions for LLM alignment through innovative reward design strategies.
NeuroLoc: Encoding Navigation Cells for 6-DOF Camera Localization
May 02, 2025



Recently, camera localization has been widely adopted in autonomous robotic navigation due to its efficiency and convenience. However, autonomous navigation in unknown environments often suffers from scene ambiguity, environmental disturbances, and dynamic object transformation in camera localization. To address this problem, inspired by the biological brain navigation mechanism (such as grid cells, place cells, and head direction cells), we propose a novel neurobiological camera location method, namely NeuroLoc. Firstly, we designed a Hebbian learning module driven by place cells to save and replay historical information, aiming to restore the details of historical representations and solve the issue of scene fuzziness. Secondly, we utilized the head direction cell-inspired internal direction learning as multi-head attention embedding to help restore the true orientation in similar scenes. Finally, we added a 3D grid center prediction in the pose regression module to reduce the final wrong prediction. We evaluate the proposed NeuroLoc on commonly used benchmark indoor and outdoor datasets. The experimental results show that our NeuroLoc can enhance the robustness in complex environments and improve the performance of pose regression by using only a single image.
SDVPT: Semantic-Driven Visual Prompt Tuning for Open-World Object Counting
Apr 24, 2025



Open-world object counting leverages the robust text-image alignment of pre-trained vision-language models (VLMs) to enable counting of arbitrary categories in images specified by textual queries. However, widely adopted naive fine-tuning strategies concentrate exclusively on text-image consistency for categories contained in training, which leads to limited generalizability for unseen categories. In this work, we propose a plug-and-play Semantic-Driven Visual Prompt Tuning framework (SDVPT) that transfers knowledge from the training set to unseen categories with minimal overhead in parameters and inference time. First, we introduce a two-stage visual prompt learning strategy composed of Category-Specific Prompt Initialization (CSPI) and Topology-Guided Prompt Refinement (TGPR). The CSPI generates category-specific visual prompts, and then TGPR distills latent structural patterns from the VLM's text encoder to refine these prompts. During inference, we dynamically synthesize the visual prompts for unseen categories based on the semantic correlation between unseen and training categories, facilitating robust text-image alignment for unseen categories. Extensive experiments integrating SDVPT with all available open-world object counting models demonstrate its effectiveness and adaptability across three widely used datasets: FSC-147, CARPK, and PUCPR+.
WeatherGen: A Unified Diverse Weather Generator for LiDAR Point Clouds via Spider Mamba Diffusion
Apr 18, 2025



3D scene perception demands a large amount of adverse-weather LiDAR data, yet the cost of LiDAR data collection presents a significant scaling-up challenge. To this end, a series of LiDAR simulators have been proposed. Yet, they can only simulate a single adverse weather with a single physical model, and the fidelity of the generated data is quite limited. This paper presents WeatherGen, the first unified diverse-weather LiDAR data diffusion generation framework, significantly improving fidelity. Specifically, we first design a map-based data producer, which can provide a vast amount of high-quality diverse-weather data for training purposes. Then, we utilize the diffusion-denoising paradigm to construct a diffusion model. Among them, we propose a spider mamba generator to restore the disturbed diverse weather data gradually. The spider mamba models the feature interactions by scanning the LiDAR beam circle or central ray, excellently maintaining the physical structure of the LiDAR data. Subsequently, following the generator to transfer real-world knowledge, we design a latent feature aligner. Afterward, we devise a contrastive learning-based controller, which equips weather control signals with compact semantic knowledge through language supervision, guiding the diffusion model to generate more discriminative data. Extensive evaluations demonstrate the high generation quality of WeatherGen. Through WeatherGen, we construct the mini-weather dataset, promoting the performance of the downstream task under adverse weather conditions. Code is available: https://github.com/wuyang98/weathergen
ProgRoCC: A Progressive Approach to Rough Crowd Counting
Apr 18, 2025



As the number of individuals in a crowd grows, enumeration-based techniques become increasingly infeasible and their estimates increasingly unreliable. We propose instead an estimation-based version of the problem: we label Rough Crowd Counting that delivers better accuracy on the basis of training data that is easier to acquire. Rough crowd counting requires only rough annotations of the number of targets in an image, instead of the more traditional, and far more expensive, per-target annotations. We propose an approach to the rough crowd counting problem based on CLIP, termed ProgRoCC. Specifically, we introduce a progressive estimation learning strategy that determines the object count through a coarse-to-fine approach. This approach delivers answers quickly, outperforms the state-of-the-art in semi- and weakly-supervised crowd counting. In addition, we design a vision-language matching adapter that optimizes key-value pairs by mining effective matches of two modalities to refine the visual features, thereby improving the final performance. Extensive experimental results on three widely adopted crowd counting datasets demonstrate the effectiveness of our method.
Anchor Token Matching: Implicit Structure Locking for Training-free AR Image Editing
Apr 14, 2025



Text-to-image generation has seen groundbreaking advancements with diffusion models, enabling high-fidelity synthesis and precise image editing through cross-attention manipulation. Recently, autoregressive (AR) models have re-emerged as powerful alternatives, leveraging next-token generation to match diffusion models. However, existing editing techniques designed for diffusion models fail to translate directly to AR models due to fundamental differences in structural control. Specifically, AR models suffer from spatial poverty of attention maps and sequential accumulation of structural errors during image editing, which disrupt object layouts and global consistency. In this work, we introduce Implicit Structure Locking (ISLock), the first training-free editing strategy for AR visual models. Rather than relying on explicit attention manipulation or fine-tuning, ISLock preserves structural blueprints by dynamically aligning self-attention patterns with reference images through the Anchor Token Matching (ATM) protocol. By implicitly enforcing structural consistency in latent space, our method ISLock enables structure-aware editing while maintaining generative autonomy. Extensive experiments demonstrate that ISLock achieves high-quality, structure-consistent edits without additional training and is superior or comparable to conventional editing techniques. Our findings pioneer the way for efficient and flexible AR-based image editing, further bridging the performance gap between diffusion and autoregressive generative models. The code will be publicly available at https://github.com/hutaiHang/ATM
SVG-IR: Spatially-Varying Gaussian Splatting for Inverse Rendering
Apr 09, 2025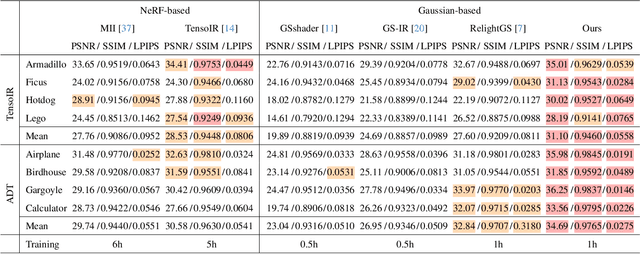
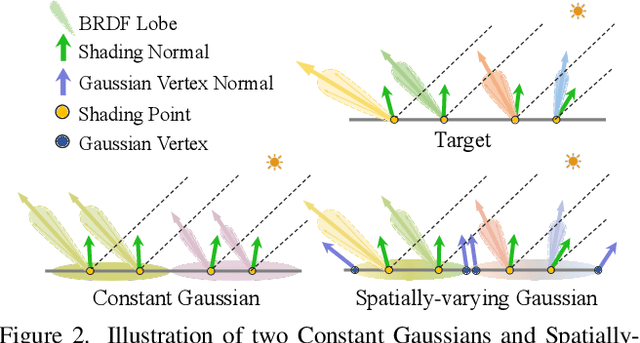
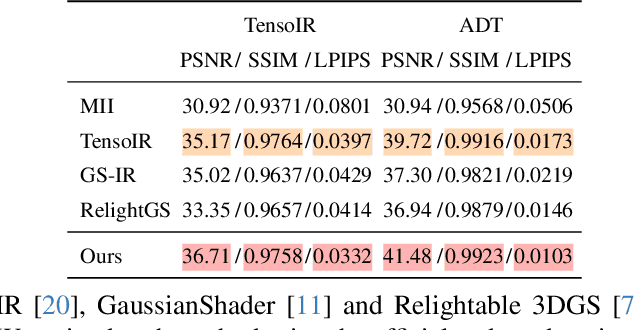

Reconstructing 3D assets from images, known as inverse rendering (IR), remains a challenging task due to its ill-posed nature. 3D Gaussian Splatting (3DGS) has demonstrated impressive capabilities for novel view synthesis (NVS) tasks. Methods apply it to relighting by separating radiance into BRDF parameters and lighting, yet produce inferior relighting quality with artifacts and unnatural indirect illumination due to the limited capability of each Gaussian, which has constant material parameters and normal, alongside the absence of physical constraints for indirect lighting. In this paper, we present a novel framework called Spatially-vayring Gaussian Inverse Rendering (SVG-IR), aimed at enhancing both NVS and relighting quality. To this end, we propose a new representation-Spatially-varying Gaussian (SVG)-that allows per-Gaussian spatially varying parameters. This enhanced representation is complemented by a SVG splatting scheme akin to vertex/fragment shading in traditional graphics pipelines. Furthermore, we integrate a physically-based indirect lighting model, enabling more realistic relighting. The proposed SVG-IR framework significantly improves rendering quality, outperforming state-of-the-art NeRF-based methods by 2.5 dB in peak signal-to-noise ratio (PSNR) and surpassing existing Gaussian-based techniques by 3.5 dB in relighting tasks, all while maintaining a real-time rendering speed.
COIG-P: A High-Quality and Large-Scale Chinese Preference Dataset for Alignment with Human Values
Apr 07, 2025Aligning large language models (LLMs) with human preferences has achieved remarkable success. However, existing Chinese preference datasets are limited by small scale, narrow domain coverage, and lack of rigorous data validation. Additionally, the reliance on human annotators for instruction and response labeling significantly constrains the scalability of human preference datasets. To address these challenges, we design an LLM-based Chinese preference dataset annotation pipeline with no human intervention. Specifically, we crawled and carefully filtered 92k high-quality Chinese queries and employed 15 mainstream LLMs to generate and score chosen-rejected response pairs. Based on it, we introduce COIG-P (Chinese Open Instruction Generalist - Preference), a high-quality, large-scale Chinese preference dataset, comprises 1,009k Chinese preference pairs spanning 6 diverse domains: Chat, Code, Math, Logic, Novel, and Role. Building upon COIG-P, to reduce the overhead of using LLMs for scoring, we trained a 8B-sized Chinese Reward Model (CRM) and meticulously constructed a Chinese Reward Benchmark (CRBench). Evaluation results based on AlignBench \citep{liu2024alignbenchbenchmarkingchinesealignment} show that that COIG-P significantly outperforms other Chinese preference datasets, and it brings significant performance improvements ranging from 2% to 12% for the Qwen2/2.5 and Infinity-Instruct-3M-0625 model series, respectively. The results on CRBench demonstrate that our CRM has a strong and robust scoring ability. We apply it to filter chosen-rejected response pairs in a test split of COIG-P, and our experiments show that it is comparable to GPT-4o in identifying low-quality samples while maintaining efficiency and cost-effectiveness. Our codes and data are released in https://github.com/multimodal-art-projection/COIG-P.
TextCrafter: Accurately Rendering Multiple Texts in Complex Visual Scenes
Apr 01, 2025This paper explores the task of Complex Visual Text Generation (CVTG), which centers on generating intricate textual content distributed across diverse regions within visual images. In CVTG, image generation models often rendering distorted and blurred visual text or missing some visual text. To tackle these challenges, we propose TextCrafter, a novel multi-visual text rendering method. TextCrafter employs a progressive strategy to decompose complex visual text into distinct components while ensuring robust alignment between textual content and its visual carrier. Additionally, it incorporates a token focus enhancement mechanism to amplify the prominence of visual text during the generation process. TextCrafter effectively addresses key challenges in CVTG tasks, such as text confusion, omissions, and blurriness. Moreover, we present a new benchmark dataset, CVTG-2K, tailored to rigorously evaluate the performance of generative models on CVTG tasks. Extensive experiments demonstrate that our method surpasses state-of-the-art approaches.