 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Evolving Framework for Efficient Terminal Agents via Observational Context Compression
Apr 21, 2026As model capabilities advance, research has increasingly shifted toward long-horizon, multi-turn terminal-centric agentic tasks, where raw environment feedback is often preserved in the interaction history to support future decisions. However, repeatedly retaining such feedback introduces substantial redundancy and causes cumulative token cost to grow quadratically with the number of steps, hindering long-horizon reasoning. Although observation compression can mitigate this issue, the heterogeneity of terminal environments makes heuristic-based or fixed-prompt methods difficult to generalize. We propose TACO, a plug-and-play, self-evolving Terminal Agent Compression framework that automatically discovers and refines compression rules from interaction trajectories for existing terminal agents. Experiments on TerminalBench (TB 1.0 and TB 2.0) and four additional terminal-related benchmarks (i.e., SWE-Bench Lite, CompileBench, DevEval, and CRUST-Bench) show that TACO consistently improves performance across mainstream agent frameworks and strong backbone models. With MiniMax-2.5, it improves performance on most benchmarks while reducing token overhead by around 10%. On TerminalBench, it brings consistent gains of 1%-4% across strong agentic models, and further improves accuracy by around 2%-3% under the same token budget. These results demonstrate the effectiveness and generalization of self-evolving, task-aware compression for terminal agents.
IQuest-Coder-V1 Technical Report
Mar 17, 2026In this report, we introduce the IQuest-Coder-V1 series-(7B/14B/40B/40B-Loop), a new family of code large language models (LLMs). Moving beyond static code representations, we propose the code-flow multi-stage training paradigm, which captures the dynamic evolution of software logic through different phases of the pipeline. Our models are developed through the evolutionary pipeline, starting with the initial pre-training consisting of code facts, repository, and completion data. Following that, we implement a specialized mid-training stage that integrates reasoning and agentic trajectories in 32k-context and repository-scale in 128k-context to forge deep logical foundations. The models are then finalized with post-training of specialized coding capabilities, which is bifurcated into two specialized paths: the thinking path (utilizing reasoning-driven RL) and the instruct path (optimized for general assistance). IQuest-Coder-V1 achieves state-of-the-art performance among competitive models across critical dimensions of code intelligence: agentic software engineering, competitive programming, and complex tool use. To address deployment constraints, the IQuest-Coder-V1-Loop variant introduces a recurrent mechanism designed to optimize the trade-off between model capacity and deployment footprint, offering an architecturally enhanced path for efficacy-efficiency trade-off. We believe the release of the IQuest-Coder-V1 series, including the complete white-box chain of checkpoints from pre-training bases to the final thinking and instruction models, will advance research in autonomous code intelligence and real-world agentic systems.
Large-Scale Terminal Agentic Trajectory Generation from Dockerized Environments
Feb 03, 2026Training agentic models for terminal-based tasks critically depends on high-quality terminal trajectories that capture realistic long-horizon interactions across diverse domains. However, constructing such data at scale remains challenging due to two key requirements: \textbf{\emph{Executability}}, since each instance requires a suitable and often distinct Docker environment; and \textbf{\emph{Verifiability}}, because heterogeneous task outputs preclude unified, standardized verification. To address these challenges, we propose \textbf{TerminalTraj}, a scalable pipeline that (i) filters high-quality repositories to construct Dockerized execution environments, (ii) generates Docker-aligned task instances, and (iii) synthesizes agent trajectories with executable validation code. Using TerminalTraj, we curate 32K Docker images and generate 50,733 verified terminal trajectories across eight domains. Models trained on this data with the Qwen2.5-Coder backbone achieve consistent performance improvements on TerminalBench (TB), with gains of up to 20\% on TB~1.0 and 10\% on TB~2.0 over their respective backbones. Notably, \textbf{TerminalTraj-32B} achieves strong performance among models with fewer than 100B parameters, reaching 35.30\% on TB~1.0 and 22.00\% on TB~2.0, and demonstrates improved test-time scaling behavior. All code and data are available at https://github.com/Wusiwei0410/TerminalTraj.
Scaling Test-time Compute for LLM Agents
Jun 15, 2025Scaling test time compute has shown remarkable success in improving the reasoning abilities of large language models (LLMs). In this work, we conduct the first systematic exploration of applying test-time scaling methods to language agents and investigate the extent to which it improves their effectiveness. Specifically, we explore different test-time scaling strategies, including: (1) parallel sampling algorithms; (2) sequential revision strategies; (3) verifiers and merging methods; (4)strategies for diversifying rollouts.We carefully analyze and ablate the impact of different design strategies on applying test-time scaling on language agents, and have follow findings: 1. Scaling test time compute could improve the performance of agents. 2. Knowing when to reflect is important for agents. 3. Among different verification and result merging approaches, the list-wise method performs best. 4. Increasing diversified rollouts exerts a positive effect on the agent's task performance.
DocMMIR: A Framework for Document Multi-modal Information Retrieval
May 25, 2025The rapid advancement of unsupervised representation learning and large-scale pre-trained vision-language models has significantly improved cross-modal retrieval tasks. However, existing multi-modal information retrieval (MMIR) studies lack a comprehensive exploration of document-level retrieval and suffer from the absence of cross-domain datasets at this granularity. To address this limitation, we introduce DocMMIR, a novel multi-modal document retrieval framework designed explicitly to unify diverse document formats and domains, including Wikipedia articles, scientific papers (arXiv), and presentation slides, within a comprehensive retrieval scenario. We construct a large-scale cross-domain multimodal benchmark, comprising 450K samples, which systematically integrates textual and visual information. Our comprehensive experimental analysis reveals substantial limitations in current state-of-the-art MLLMs (CLIP, BLIP2, SigLIP-2, ALIGN) when applied to our tasks, with only CLIP demonstrating reasonable zero-shot performance. Furthermore, we conduct a systematic investigation of training strategies, including cross-modal fusion methods and loss functions, and develop a tailored approach to train CLIP on our benchmark. This results in a +31% improvement in MRR@10 compared to the zero-shot baseline. All our data and code are released in https://github.com/J1mL1/DocMMIR.
DeepMath-Creative: A Benchmark for Evaluating Mathematical Creativity of Large Language Models
May 13, 2025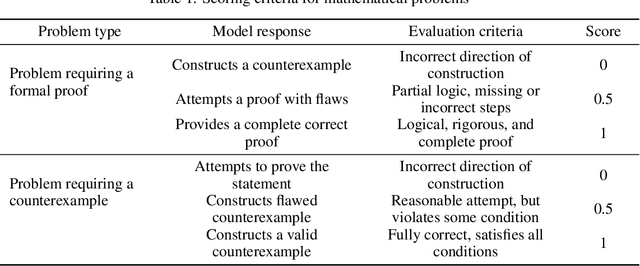
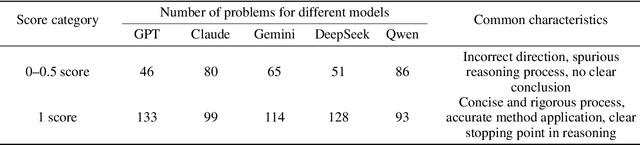
To advance the mathematical proficiency of large language models (LLMs), the DeepMath team has launched an open-source initiative aimed at developing an open mathematical LLM and systematically evaluating its mathematical creativity. This paper represents the initial contribution of this initiative. While recent developments in mathematical LLMs have predominantly emphasized reasoning skills, as evidenced by benchmarks on elementary to undergraduate-level mathematical tasks, the creative capabilities of these models have received comparatively little attention, and evaluation datasets remain scarce. To address this gap, we propose an evaluation criteria for mathematical creativity and introduce DeepMath-Creative, a novel, high-quality benchmark comprising constructive problems across algebra, geometry, analysis, and other domains. We conduct a systematic evaluation of mainstream LLMs' creative problem-solving abilities using this dataset. Experimental results show that even under lenient scoring criteria -- emphasizing core solution components and disregarding minor inaccuracies, such as small logical gaps, incomplete justifications, or redundant explanations -- the best-performing model, O3 Mini, achieves merely 70% accuracy, primarily on basic undergraduate-level constructive tasks. Performance declines sharply on more complex problems, with models failing to provide substantive strategies for open problems. These findings suggest that, although current LLMs display a degree of constructive proficiency on familiar and lower-difficulty problems, such performance is likely attributable to the recombination of memorized patterns rather than authentic creative insight or novel synthesis.
COIG-P: A High-Quality and Large-Scale Chinese Preference Dataset for Alignment with Human Values
Apr 07, 2025Aligning large language models (LLMs) with human preferences has achieved remarkable success. However, existing Chinese preference datasets are limited by small scale, narrow domain coverage, and lack of rigorous data validation. Additionally, the reliance on human annotators for instruction and response labeling significantly constrains the scalability of human preference datasets. To address these challenges, we design an LLM-based Chinese preference dataset annotation pipeline with no human intervention. Specifically, we crawled and carefully filtered 92k high-quality Chinese queries and employed 15 mainstream LLMs to generate and score chosen-rejected response pairs. Based on it, we introduce COIG-P (Chinese Open Instruction Generalist - Preference), a high-quality, large-scale Chinese preference dataset, comprises 1,009k Chinese preference pairs spanning 6 diverse domains: Chat, Code, Math, Logic, Novel, and Role. Building upon COIG-P, to reduce the overhead of using LLMs for scoring, we trained a 8B-sized Chinese Reward Model (CRM) and meticulously constructed a Chinese Reward Benchmark (CRBench). Evaluation results based on AlignBench \citep{liu2024alignbenchbenchmarkingchinesealignment} show that that COIG-P significantly outperforms other Chinese preference datasets, and it brings significant performance improvements ranging from 2% to 12% for the Qwen2/2.5 and Infinity-Instruct-3M-0625 model series, respectively. The results on CRBench demonstrate that our CRM has a strong and robust scoring ability. We apply it to filter chosen-rejected response pairs in a test split of COIG-P, and our experiments show that it is comparable to GPT-4o in identifying low-quality samples while maintaining efficiency and cost-effectiveness. Our codes and data are released in https://github.com/multimodal-art-projection/COIG-P.
ContrastScore: Towards Higher Quality, Less Biased, More Efficient Evaluation Metrics with Contrastive Evaluation
Apr 02, 2025Evaluating the quality of generated text automatically remains a significant challenge. Conventional reference-based metrics have been shown to exhibit relatively weak correlation with human evaluations. Recent research advocates the use of large language models (LLMs) as source-based metrics for natural language generation (NLG) assessment. While promising, LLM-based metrics, particularly those using smaller models, still fall short in aligning with human judgments. In this work, we introduce ContrastScore, a contrastive evaluation metric designed to enable higher-quality, less biased, and more efficient assessment of generated text. We evaluate ContrastScore on two NLG tasks: machine translation and summarization. Experimental results show that ContrastScore consistently achieves stronger correlation with human judgments than both single-model and ensemble-based baselines. Notably, ContrastScore based on Qwen 3B and 0.5B even outperforms Qwen 7B, despite having only half as many parameters, demonstrating its efficiency. Furthermore, it effectively mitigates common evaluation biases such as length and likelihood preferences, resulting in more robust automatic evaluation.
LongEval: A Comprehensive Analysis of Long-Text Generation Through a Plan-based Paradigm
Feb 26, 2025Large Language Models (LLMs) have achieved remarkable success in various natural language processing tasks, yet their ability to generate long-form content remains poorly understood and evaluated. Our analysis reveals that current LLMs struggle with length requirements and information density in long-text generation, with performance deteriorating as text length increases. To quantitively locate such a performance degradation and provide further insights on model development, we present LongEval, a benchmark that evaluates long-text generation through both direct and plan-based generation paradigms, inspired by cognitive and linguistic writing models. The comprehensive experiments in this work reveal interesting findings such as that while model size correlates with generation ability, the small-scale model (e.g., LongWriter), well-trained on long texts, has comparable performance. All code and datasets are released in https://github.com/Wusiwei0410/LongEval.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.