 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWST: Weakly Supervised Transducer for Automatic Speech Recognition
Nov 06, 2025The Recurrent Neural Network-Transducer (RNN-T) is widely adopted in end-to-end (E2E) automatic speech recognition (ASR) tasks but depends heavily on large-scale, high-quality annotated data, which are often costly and difficult to obtain. To mitigate this reliance, we propose a Weakly Supervised Transducer (WST), which integrates a flexible training graph designed to robustly handle errors in the transcripts without requiring additional confidence estimation or auxiliary pre-trained models. Empirical evaluations on synthetic and industrial datasets reveal that WST effectively maintains performance even with transcription error rates of up to 70%, consistently outperforming existing Connectionist Temporal Classification (CTC)-based weakly supervised approaches, such as Bypass Temporal Classification (BTC) and Omni-Temporal Classification (OTC). These results demonstrate the practical utility and robustness of WST in realistic ASR settings. The implementation will be publicly available.
AutoRing: Imitation Learning--based Autonomous Intraocular Foreign Body Removal Manipulation with Eye Surgical Robot
Aug 27, 2025Intraocular foreign body removal demands millimeter-level precision in confined intraocular spaces, yet existing robotic systems predominantly rely on manual teleoperation with steep learning curves. To address the challenges of autonomous manipulation (particularly kinematic uncertainties from variable motion scaling and variation of the Remote Center of Motion (RCM) point), we propose AutoRing, an imitation learning framework for autonomous intraocular foreign body ring manipulation. Our approach integrates dynamic RCM calibration to resolve coordinate-system inconsistencies caused by intraocular instrument variation and introduces the RCM-ACT architecture, which combines action-chunking transformers with real-time kinematic realignment. Trained solely on stereo visual data and instrument kinematics from expert demonstrations in a biomimetic eye model, AutoRing successfully completes ring grasping and positioning tasks without explicit depth sensing. Experimental validation demonstrates end-to-end autonomy under uncalibrated microscopy conditions. The results provide a viable framework for developing intelligent eye-surgical systems capable of complex intraocular procedures.
Knowing or Guessing? Robust Medical Visual Question Answering via Joint Consistency and Contrastive Learning
Aug 26, 2025In high-stakes medical applications, consistent answering across diverse question phrasings is essential for reliable diagnosis. However, we reveal that current Medical Vision-Language Models (Med-VLMs) exhibit concerning fragility in Medical Visual Question Answering, as their answers fluctuate significantly when faced with semantically equivalent rephrasings of medical questions. We attribute this to two limitations: (1) insufficient alignment of medical concepts, leading to divergent reasoning patterns, and (2) hidden biases in training data that prioritize syntactic shortcuts over semantic understanding. To address these challenges, we construct RoMed, a dataset built upon original VQA datasets containing 144k questions with variations spanning word-level, sentence-level, and semantic-level perturbations. When evaluating state-of-the-art (SOTA) models like LLaVA-Med on RoMed, we observe alarming performance drops (e.g., a 40\% decline in Recall) compared to original VQA benchmarks, exposing critical robustness gaps. To bridge this gap, we propose Consistency and Contrastive Learning (CCL), which integrates two key components: (1) knowledge-anchored consistency learning, aligning Med-VLMs with medical knowledge rather than shallow feature patterns, and (2) bias-aware contrastive learning, mitigating data-specific priors through discriminative representation refinement. CCL achieves SOTA performance on three popular VQA benchmarks and notably improves answer consistency by 50\% on the challenging RoMed test set, demonstrating significantly enhanced robustness. Code will be released.
SSPO: Self-traced Step-wise Preference Optimization for Process Supervision and Reasoning Compression
Aug 18, 2025Test-time scaling has proven effective in further enhancing the performance of pretrained Large Language Models (LLMs). However, mainstream post-training methods (i.e., reinforcement learning (RL) with chain-of-thought (CoT) reasoning) often incur substantial computational overhead due to auxiliary models and overthinking. In this paper, we empirically reveal that the incorrect answers partially stem from verbose reasoning processes lacking correct self-fix, where errors accumulate across multiple reasoning steps. To this end, we propose Self-traced Step-wise Preference Optimization (SSPO), a pluggable RL process supervision framework that enables fine-grained optimization of each reasoning step. Specifically, SSPO requires neither auxiliary models nor stepwise manual annotations. Instead, it leverages step-wise preference signals generated by the model itself to guide the optimization process for reasoning compression. Experiments demonstrate that the generated reasoning sequences from SSPO are both accurate and succinct, effectively mitigating overthinking behaviors without compromising model performance across diverse domains and languages.
RecGPT Technical Report
Jul 30, 2025



Recommender systems are among the most impactful applications of artificial intelligence, serving as critical infrastructure connecting users, merchants, and platforms. However, most current industrial systems remain heavily reliant on historical co-occurrence patterns and log-fitting objectives, i.e., optimizing for past user interactions without explicitly modeling user intent. This log-fitting approach often leads to overfitting to narrow historical preferences, failing to capture users' evolving and latent interests. As a result, it reinforces filter bubbles and long-tail phenomena, ultimately harming user experience and threatening the sustainability of the whole recommendation ecosystem. To address these challenges, we rethink the overall design paradigm of recommender systems and propose RecGPT, a next-generation framework that places user intent at the center of the recommendation pipeline. By integrating large language models (LLMs) into key stages of user interest mining, item retrieval, and explanation generation, RecGPT transforms log-fitting recommendation into an intent-centric process. To effectively align general-purpose LLMs to the above domain-specific recommendation tasks at scale, RecGPT incorporates a multi-stage training paradigm, which integrates reasoning-enhanced pre-alignment and self-training evolution, guided by a Human-LLM cooperative judge system. Currently, RecGPT has been fully deployed on the Taobao App. Online experiments demonstrate that RecGPT achieves consistent performance gains across stakeholders: users benefit from increased content diversity and satisfaction, merchants and the platform gain greater exposure and conversions. These comprehensive improvement results across all stakeholders validates that LLM-driven, intent-centric design can foster a more sustainable and mutually beneficial recommendation ecosystem.
Uncertainty-Aware Complex Scientific Table Data Extraction
Jul 02, 2025Table structure recognition (TSR) and optical character recognition (OCR) play crucial roles in extracting structured data from tables in scientific documents. However, existing extraction frameworks built on top of TSR and OCR methods often fail to quantify the uncertainties of extracted results. To obtain highly accurate data for scientific domains, all extracted data must be manually verified, which can be time-consuming and labor-intensive. We propose a framework that performs uncertainty-aware data extraction for complex scientific tables, built on conformal prediction, a model-agnostic method for uncertainty quantification (UQ). We explored various uncertainty scoring methods to aggregate the uncertainties introduced by TSR and OCR. We rigorously evaluated the framework using a standard benchmark and an in-house dataset consisting of complex scientific tables in six scientific domains. The results demonstrate the effectiveness of using UQ for extraction error detection, and by manually verifying only 47\% of extraction results, the data quality can be improved by 30\%. Our work quantitatively demonstrates the role of UQ with the potential of improving the efficiency in the human-machine cooperation process to obtain scientifically usable data from complex tables in scientific documents. All code and data are available on GitHub at https://github.com/lamps-lab/TSR-OCR-UQ/tree/main.
Mitigating Hallucination of Large Vision-Language Models via Dynamic Logits Calibration
Jun 26, 2025Large Vision-Language Models (LVLMs) have demonstrated significant advancements in multimodal understanding, yet they are frequently hampered by hallucination-the generation of text that contradicts visual input. Existing training-free decoding strategies exhibit critical limitations, including the use of static constraints that do not adapt to semantic drift during generation, inefficiency stemming from the need for multiple forward passes, and degradation of detail due to overly rigid intervention rules. To overcome these challenges, this paper introduces Dynamic Logits Calibration (DLC), a novel training-free decoding framework designed to dynamically align text generation with visual evidence at inference time. At the decoding phase, DLC step-wise employs CLIP to assess the semantic alignment between the input image and the generated text sequence. Then, the Relative Visual Advantage (RVA) of candidate tokens is evaluated against a dynamically updated contextual baseline, adaptively adjusting output logits to favor tokens that are visually grounded. Furthermore, an adaptive weighting mechanism, informed by a real-time context alignment score, carefully balances the visual guidance while ensuring the overall quality of the textual output. Extensive experiments conducted across diverse benchmarks and various LVLM architectures (such as LLaVA, InstructBLIP, and MiniGPT-4) demonstrate that DLC significantly reduces hallucinations, outperforming current methods while maintaining high inference efficiency by avoiding multiple forward passes. Overall, we present an effective and efficient decoding-time solution to mitigate hallucinations, thereby enhancing the reliability of LVLMs for more practices. Code will be released on Github.
CAPO: Reinforcing Consistent Reasoning in Medical Decision-Making
Jun 15, 2025



In medical visual question answering (Med-VQA), achieving accurate responses relies on three critical steps: precise perception of medical imaging data, logical reasoning grounded in visual input and textual questions, and coherent answer derivation from the reasoning process. Recent advances in general vision-language models (VLMs) show that large-scale reinforcement learning (RL) could significantly enhance both reasoning capabilities and overall model performance. However, their application in medical domains is hindered by two fundamental challenges: 1) misalignment between perceptual understanding and reasoning stages, and 2) inconsistency between reasoning pathways and answer generation, both compounded by the scarcity of high-quality medical datasets for effective large-scale RL. In this paper, we first introduce Med-Zero-17K, a curated dataset for pure RL-based training, encompassing over 30 medical image modalities and 24 clinical tasks. Moreover, we propose a novel large-scale RL framework for Med-VLMs, Consistency-Aware Preference Optimization (CAPO), which integrates rewards to ensure fidelity between perception and reasoning, consistency in reasoning-to-answer derivation, and rule-based accuracy for final responses. Extensive experiments on both in-domain and out-of-domain scenarios demonstrate the superiority of our method over strong VLM baselines, showcasing strong generalization capability to 3D Med-VQA benchmarks and R1-like training paradigms.
Med-U1: Incentivizing Unified Medical Reasoning in LLMs via Large-scale Reinforcement Learning
Jun 14, 2025



Medical Question-Answering (QA) encompasses a broad spectrum of tasks, including multiple choice questions (MCQ), open-ended text generation, and complex computational reasoning. Despite this variety, a unified framework for delivering high-quality medical QA has yet to emerge. Although recent progress in reasoning-augmented large language models (LLMs) has shown promise, their ability to achieve comprehensive medical understanding is still largely unexplored. In this paper, we present Med-U1, a unified framework for robust reasoning across medical QA tasks with diverse output formats, ranging from MCQs to complex generation and computation tasks. Med-U1 employs pure large-scale reinforcement learning with mixed rule-based binary reward functions, incorporating a length penalty to manage output verbosity. With multi-objective reward optimization, Med-U1 directs LLMs to produce concise and verifiable reasoning chains. Empirical results reveal that Med-U1 significantly improves performance across multiple challenging Med-QA benchmarks, surpassing even larger specialized and proprietary models. Furthermore, Med-U1 demonstrates robust generalization to out-of-distribution (OOD) tasks. Extensive analysis presents insights into training strategies, reasoning chain length control, and reward design for medical LLMs. The code will be released.
3D-RAD: A Comprehensive 3D Radiology Med-VQA Dataset with Multi-Temporal Analysis and Diverse Diagnostic Tasks
Jun 11, 2025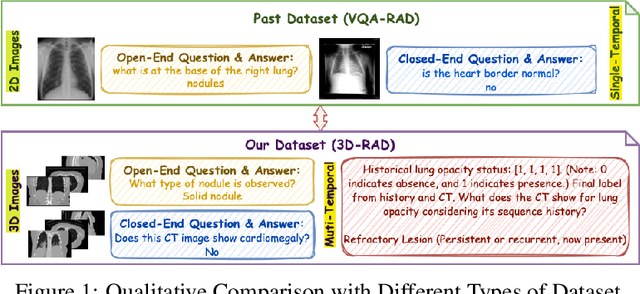
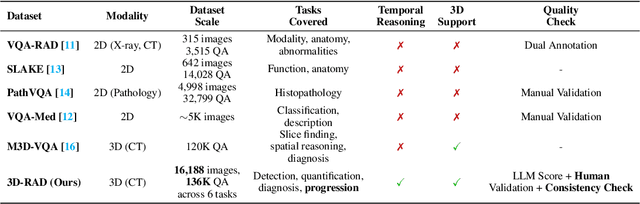
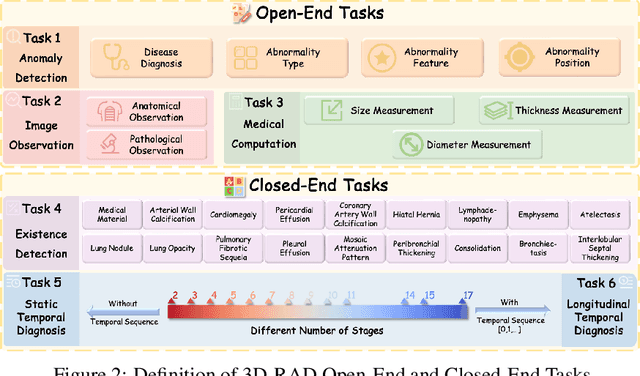
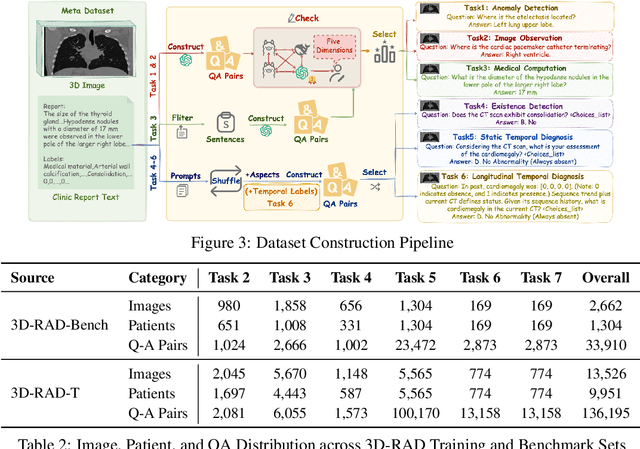
Medical Visual Question Answering (Med-VQA) holds significant potential for clinical decision support, yet existing efforts primarily focus on 2D imaging with limited task diversity. This paper presents 3D-RAD, a large-scale dataset designed to advance 3D Med-VQA using radiology CT scans. The 3D-RAD dataset encompasses six diverse VQA tasks: anomaly detection, image observation, medical computation, existence detection, static temporal diagnosis, and longitudinal temporal diagnosis. It supports both open- and closed-ended questions while introducing complex reasoning challenges, including computational tasks and multi-stage temporal analysis, to enable comprehensive benchmarking. Extensive evaluations demonstrate that existing vision-language models (VLMs), especially medical VLMs exhibit limited generalization, particularly in multi-temporal tasks, underscoring the challenges of real-world 3D diagnostic reasoning. To drive future advancements, we release a high-quality training set 3D-RAD-T of 136,195 expert-aligned samples, showing that fine-tuning on this dataset could significantly enhance model performance. Our dataset and code, aiming to catalyze multimodal medical AI research and establish a robust foundation for 3D medical visual understanding, are publicly available at https://github.com/Tang-xiaoxiao/M3D-RAD.