 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecGPT-V2 Technical Report
Dec 16, 2025



Large language models (LLMs) have demonstrated remarkable potential in transforming recommender systems from implicit behavioral pattern matching to explicit intent reasoning. While RecGPT-V1 successfully pioneered this paradigm by integrating LLM-based reasoning into user interest mining and item tag prediction, it suffers from four fundamental limitations: (1) computational inefficiency and cognitive redundancy across multiple reasoning routes; (2) insufficient explanation diversity in fixed-template generation; (3) limited generalization under supervised learning paradigms; and (4) simplistic outcome-focused evaluation that fails to match human standards. To address these challenges, we present RecGPT-V2 with four key innovations. First, a Hierarchical Multi-Agent System restructures intent reasoning through coordinated collaboration, eliminating cognitive duplication while enabling diverse intent coverage. Combined with Hybrid Representation Inference that compresses user-behavior contexts, our framework reduces GPU consumption by 60% and improves exclusive recall from 9.39% to 10.99%. Second, a Meta-Prompting framework dynamically generates contextually adaptive prompts, improving explanation diversity by +7.3%. Third, constrained reinforcement learning mitigates multi-reward conflicts, achieving +24.1% improvement in tag prediction and +13.0% in explanation acceptance. Fourth, an Agent-as-a-Judge framework decomposes assessment into multi-step reasoning, improving human preference alignment. Online A/B tests on Taobao demonstrate significant improvements: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER. RecGPT-V2 establishes both the technical feasibility and commercial viability of deploying LLM-powered intent reasoning at scale, bridging the gap between cognitive exploration and industrial utility.
RecGPT Technical Report
Jul 30, 2025



Recommender systems are among the most impactful applications of artificial intelligence, serving as critical infrastructure connecting users, merchants, and platforms. However, most current industrial systems remain heavily reliant on historical co-occurrence patterns and log-fitting objectives, i.e., optimizing for past user interactions without explicitly modeling user intent. This log-fitting approach often leads to overfitting to narrow historical preferences, failing to capture users' evolving and latent interests. As a result, it reinforces filter bubbles and long-tail phenomena, ultimately harming user experience and threatening the sustainability of the whole recommendation ecosystem. To address these challenges, we rethink the overall design paradigm of recommender systems and propose RecGPT, a next-generation framework that places user intent at the center of the recommendation pipeline. By integrating large language models (LLMs) into key stages of user interest mining, item retrieval, and explanation generation, RecGPT transforms log-fitting recommendation into an intent-centric process. To effectively align general-purpose LLMs to the above domain-specific recommendation tasks at scale, RecGPT incorporates a multi-stage training paradigm, which integrates reasoning-enhanced pre-alignment and self-training evolution, guided by a Human-LLM cooperative judge system. Currently, RecGPT has been fully deployed on the Taobao App. Online experiments demonstrate that RecGPT achieves consistent performance gains across stakeholders: users benefit from increased content diversity and satisfaction, merchants and the platform gain greater exposure and conversions. These comprehensive improvement results across all stakeholders validates that LLM-driven, intent-centric design can foster a more sustainable and mutually beneficial recommendation ecosystem.
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025
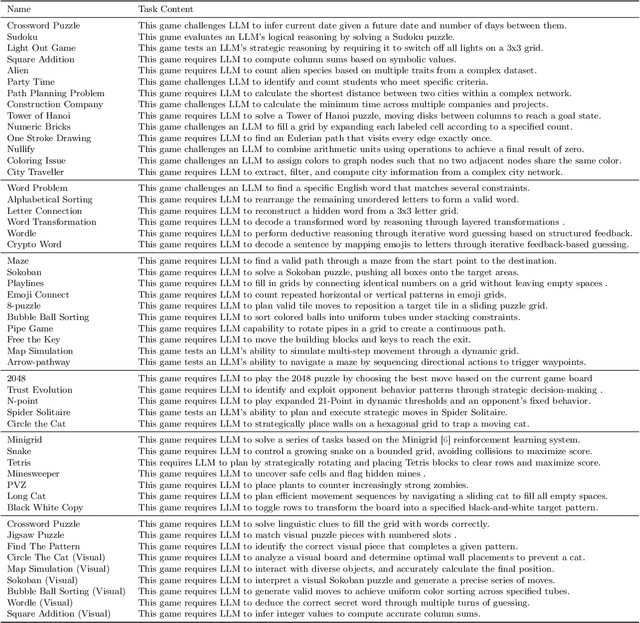
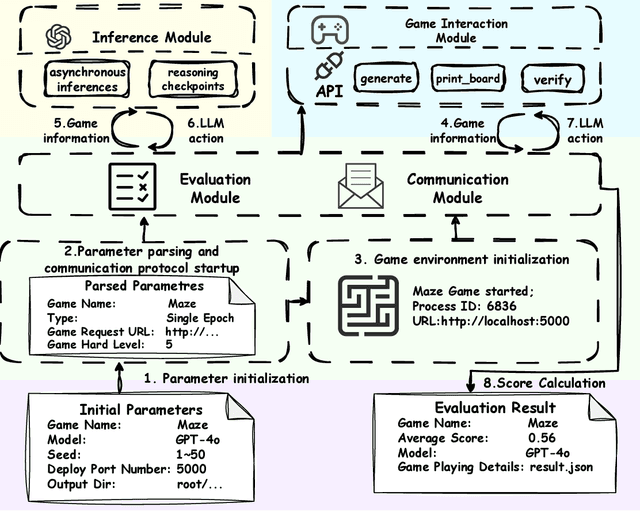

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
Participatory AI, Public Sector AI, Differential Privacy, Conversational Interfaces, Explainable AI, Citizen Engagement in AI
Apr 30, 2025



This paper introduces a conversational interface system that enables participatory design of differentially private AI systems in public sector applications. Addressing the challenge of balancing mathematical privacy guarantees with democratic accountability, we propose three key contributions: (1) an adaptive $\epsilon$-selection protocol leveraging TOPSIS multi-criteria decision analysis to align citizen preferences with differential privacy (DP) parameters, (2) an explainable noise-injection framework featuring real-time Mean Absolute Error (MAE) visualizations and GPT-4-powered impact analysis, and (3) an integrated legal-compliance mechanism that dynamically modulates privacy budgets based on evolving regulatory constraints. Our results advance participatory AI practices by demonstrating how conversational interfaces can enhance public engagement in algorithmic privacy mechanisms, ensuring that privacy-preserving AI in public sector governance remains both mathematically robust and democratically accountable.