 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Secret Common Randomness Extraction
Oct 02, 2025This paper studies the problem of extracting common randomness (CR) or secret keys from correlated random sources observed by two legitimate parties, Alice and Bob, through public discussion in the presence of an eavesdropper, Eve. We propose a practical two-stage CR extraction framework. In the first stage, the variational probabilistic quantization (VPQ) step is introduced, where Alice and Bob employ probabilistic neural network (NN) encoders to map their observations into discrete, nearly uniform random variables (RVs) with high agreement probability while minimizing information leakage to Eve. This is realized through a variational learning objective combined with adversarial training. In the second stage, a secure sketch using code-offset construction reconciles the encoder outputs into identical secret keys, whose secrecy is guaranteed by the VPQ objective. As a representative application, we study physical layer key (PLK) generation. Beyond the traditional methods, which rely on the channel reciprocity principle and require two-way channel probing, thus suffering from large protocol overhead and being unsuitable in high mobility scenarios, we propose a sensing-based PLK generation method for integrated sensing and communications (ISAC) systems, where paired range-angle (RA) maps measured at Alice and Bob serve as correlated sources. The idea is verified through both end-to-end simulations and real-world software-defined radio (SDR) measurements, including scenarios where Eve has partial knowledge about Bob's position. The results demonstrate the feasibility and convincing performance of both the proposed CR extraction framework and sensing-based PLK generation method.
AutoRing: Imitation Learning--based Autonomous Intraocular Foreign Body Removal Manipulation with Eye Surgical Robot
Aug 27, 2025Intraocular foreign body removal demands millimeter-level precision in confined intraocular spaces, yet existing robotic systems predominantly rely on manual teleoperation with steep learning curves. To address the challenges of autonomous manipulation (particularly kinematic uncertainties from variable motion scaling and variation of the Remote Center of Motion (RCM) point), we propose AutoRing, an imitation learning framework for autonomous intraocular foreign body ring manipulation. Our approach integrates dynamic RCM calibration to resolve coordinate-system inconsistencies caused by intraocular instrument variation and introduces the RCM-ACT architecture, which combines action-chunking transformers with real-time kinematic realignment. Trained solely on stereo visual data and instrument kinematics from expert demonstrations in a biomimetic eye model, AutoRing successfully completes ring grasping and positioning tasks without explicit depth sensing. Experimental validation demonstrates end-to-end autonomy under uncalibrated microscopy conditions. The results provide a viable framework for developing intelligent eye-surgical systems capable of complex intraocular procedures.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Dynamic Snake Upsampling Operater and Boundary-Skeleton Weighted Loss for Tubular Structure Segmentation
May 13, 2025Accurate segmentation of tubular topological structures (e.g., fissures and vasculature) is critical in various fields to guarantee dependable downstream quantitative analysis and modeling. However, in dense prediction tasks such as semantic segmentation and super-resolution, conventional upsampling operators cannot accommodate the slenderness of tubular structures and the curvature of morphology. This paper introduces a dynamic snake upsampling operators and a boundary-skeleton weighted loss tailored for topological tubular structures. Specifically, we design a snake upsampling operators based on an adaptive sampling domain, which dynamically adjusts the sampling stride according to the feature map and selects a set of subpixel sampling points along the serpentine path, enabling more accurate subpixel-level feature recovery for tubular structures. Meanwhile, we propose a skeleton-to-boundary increasing weighted loss that trades off main body and boundary weight allocation based on mask class ratio and distance field, preserving main body overlap while enhancing focus on target topological continuity and boundary alignment precision. Experiments across various domain datasets and backbone networks show that this plug-and-play dynamic snake upsampling operator and boundary-skeleton weighted loss boost both pixel-wise segmentation accuracy and topological consistency of results.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
PTQ4ViT: Post-Training Quantization Framework for Vision Transformers
Nov 24, 2021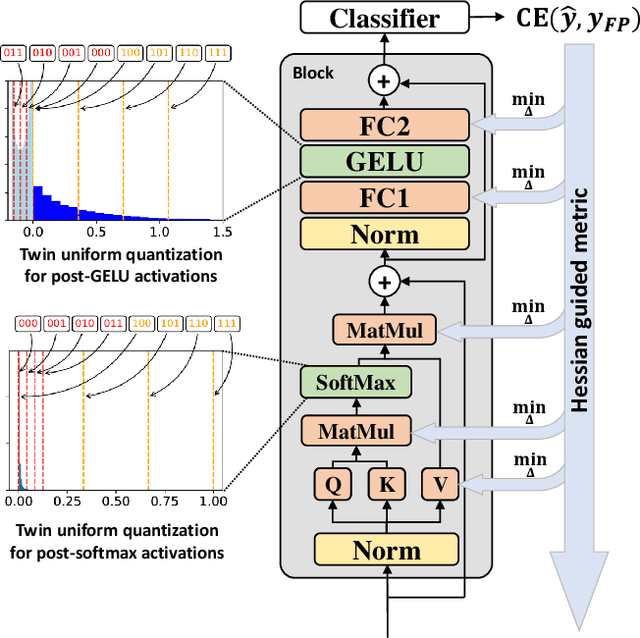
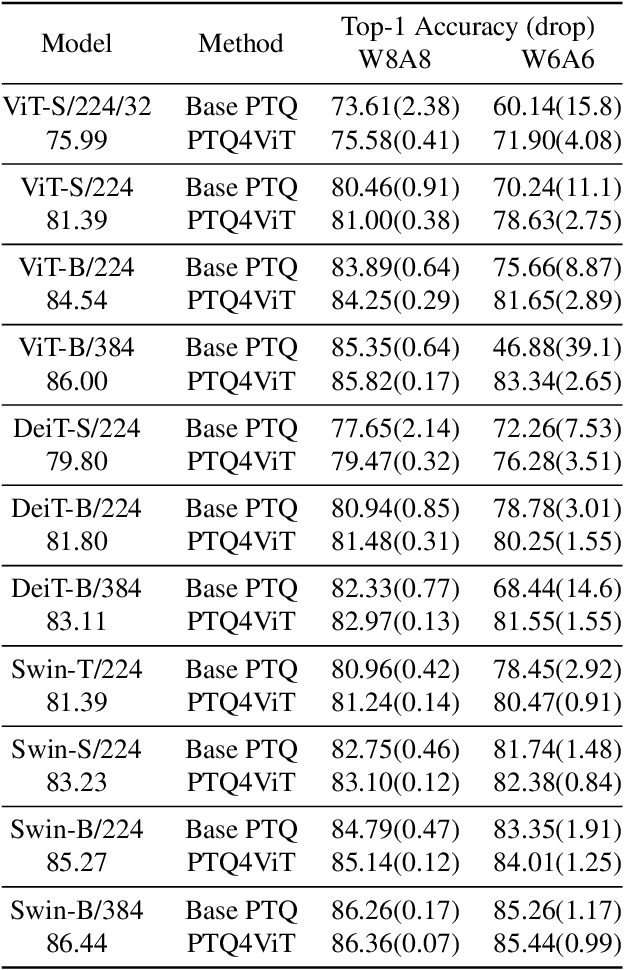
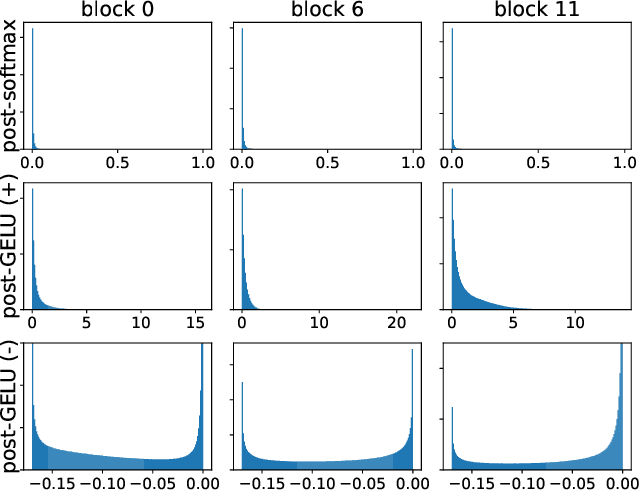
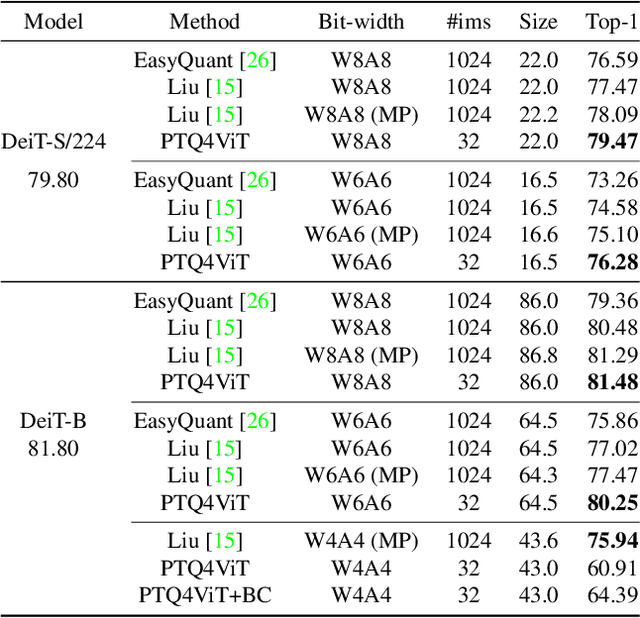
Quantization is one of the most effective methods to compress neural networks, which has achieved great success on convolutional neural networks (CNNs). Recently, vision transformers have demonstrated great potential in computer vision. However, previous post-training quantization methods performed not well on vision transformer, resulting in more than 1% accuracy drop even in 8-bit quantization. Therefore, we analyze the problems of quantization on vision transformers. We observe the distributions of activation values after softmax and GELU functions are quite different from the Gaussian distribution. We also observe that common quantization metrics, such as MSE and cosine distance, are inaccurate to determine the optimal scaling factor. In this paper, we propose the twin uniform quantization method to reduce the quantization error on these activation values. And we propose to use a Hessian guided metric to evaluate different scaling factors, which improves the accuracy of calibration with a small cost. To enable the fast quantization of vision transformers, we develop an efficient framework, PTQ4ViT. Experiments show the quantized vision transformers achieve near-lossless prediction accuracy (less than 0.5% drop at 8-bit quantization) on the ImageNet classification task.
PTQ-SL: Exploring the Sub-layerwise Post-training Quantization
Oct 18, 2021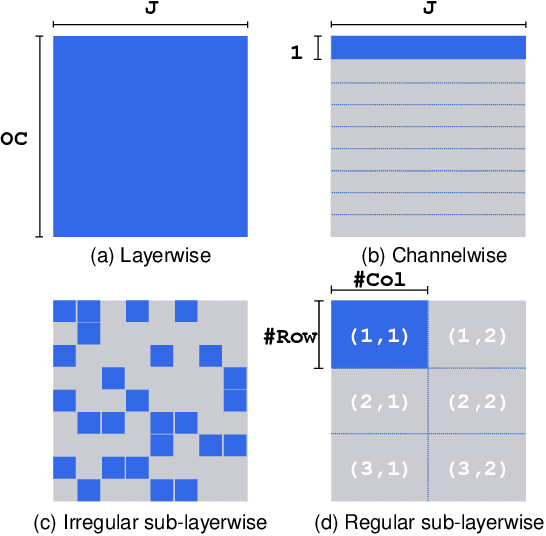
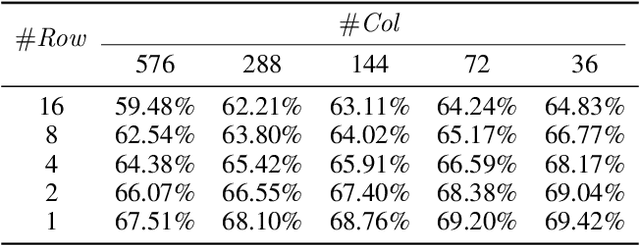
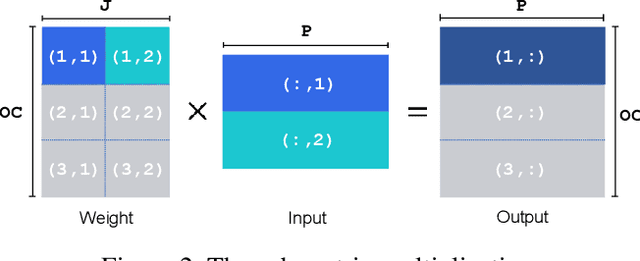
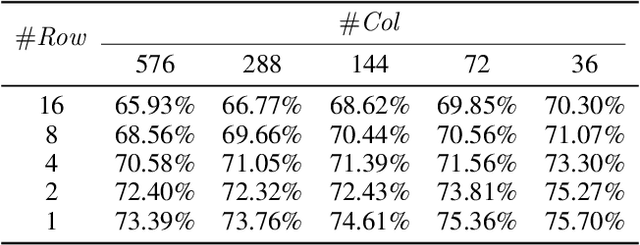
Network quantization is a powerful technique to compress convolutional neural networks. The quantization granularity determines how to share the scaling factors in weights, which affects the performance of network quantization. Most existing approaches share the scaling factors layerwisely or channelwisely for quantization of convolutional layers. Channelwise quantization and layerwise quantization have been widely used in various applications. However, other quantization granularities are rarely explored. In this paper, we will explore the sub-layerwise granularity that shares the scaling factor across multiple input and output channels. We propose an efficient post-training quantization method in sub-layerwise granularity (PTQ-SL). Then we systematically experiment on various granularities and observe that the prediction accuracy of the quantized neural network has a strong correlation with the granularity. Moreover, we find that adjusting the position of the channels can improve the performance of sub-layerwise quantization. Therefore, we propose a method to reorder the channels for sub-layerwise quantization. The experiments demonstrate that the sub-layerwise quantization with appropriate channel reordering can outperform the channelwise quantization.