 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWST: Weakly Supervised Transducer for Automatic Speech Recognition
Nov 06, 2025The Recurrent Neural Network-Transducer (RNN-T) is widely adopted in end-to-end (E2E) automatic speech recognition (ASR) tasks but depends heavily on large-scale, high-quality annotated data, which are often costly and difficult to obtain. To mitigate this reliance, we propose a Weakly Supervised Transducer (WST), which integrates a flexible training graph designed to robustly handle errors in the transcripts without requiring additional confidence estimation or auxiliary pre-trained models. Empirical evaluations on synthetic and industrial datasets reveal that WST effectively maintains performance even with transcription error rates of up to 70%, consistently outperforming existing Connectionist Temporal Classification (CTC)-based weakly supervised approaches, such as Bypass Temporal Classification (BTC) and Omni-Temporal Classification (OTC). These results demonstrate the practical utility and robustness of WST in realistic ASR settings. The implementation will be publicly available.
Deploying self-supervised learning in the wild for hybrid automatic speech recognition
May 17, 2022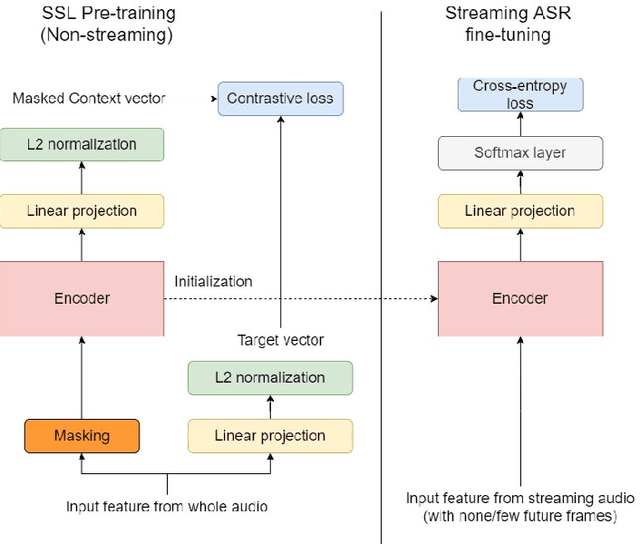
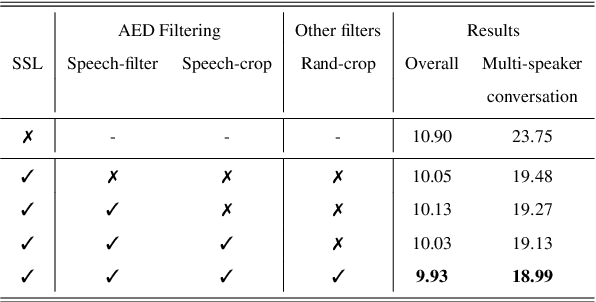
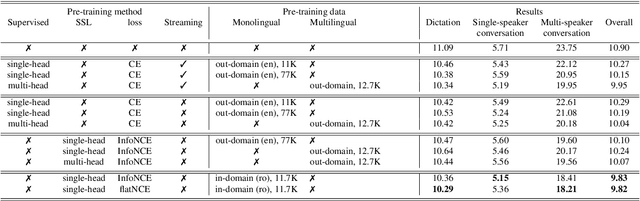
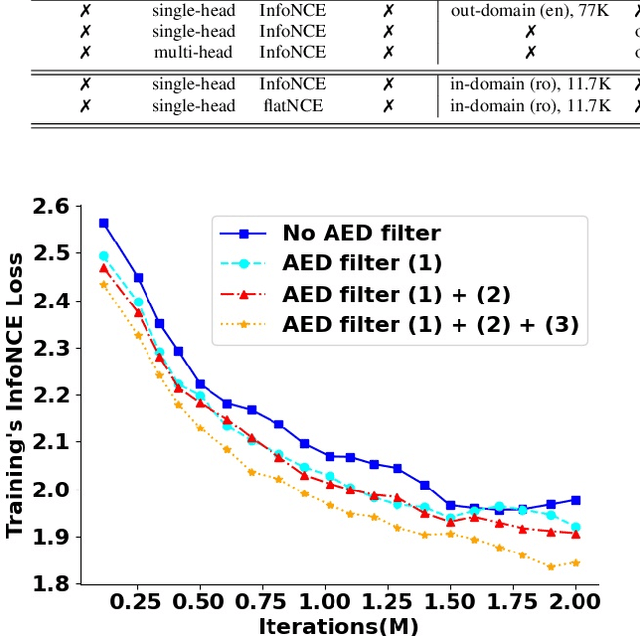
Self-supervised learning (SSL) methods have proven to be very successful in automatic speech recognition (ASR). These great improvements have been reported mostly based on highly curated datasets such as LibriSpeech for non-streaming End-to-End ASR models. However, the pivotal characteristics of SSL is to be utilized for any untranscribed audio data. In this paper, we provide a full exploration on how to utilize uncurated audio data in SSL from data pre-processing to deploying an streaming hybrid ASR model. More specifically, we present (1) the effect of Audio Event Detection (AED) model in data pre-processing pipeline (2) analysis on choosing optimizer and learning rate scheduling (3) comparison of recently developed contrastive losses, (4) comparison of various pre-training strategies such as utilization of in-domain versus out-domain pre-training data, monolingual versus multilingual pre-training data, multi-head multilingual SSL versus single-head multilingual SSL and supervised pre-training versus SSL. The experimental results show that SSL pre-training with in-domain uncurated data can achieve better performance in comparison to all the alternative out-domain pre-training strategies.
Exploring Transformers for Large-Scale Speech Recognition
May 19, 2020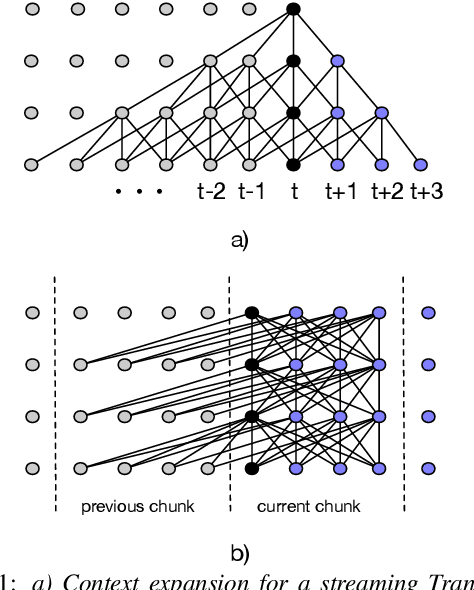
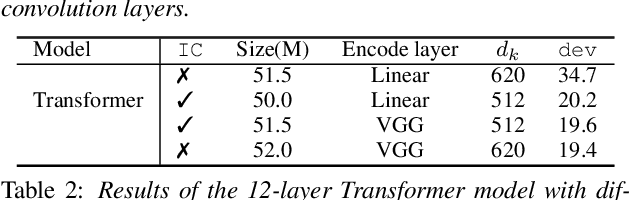
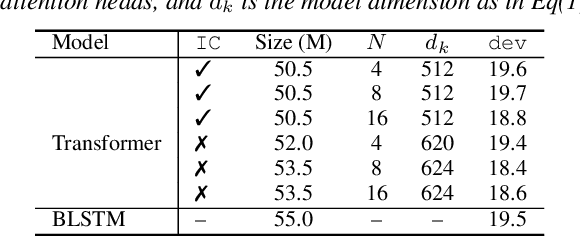
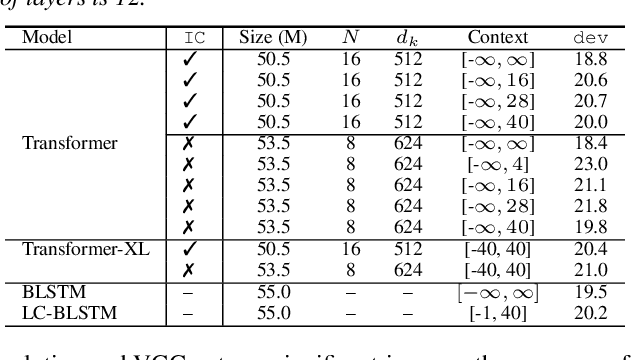
While recurrent neural networks still largely define state-of-the-art speech recognition systems, the Transformer network has been proven to be a competitive alternative, especially in the offline condition. Most studies with Transformers have been constrained in a relatively small scale setting, and some forms of data argumentation approaches are usually applied to combat the data sparsity issue. In this paper, we aim at understanding the behaviors of Transformers in the large-scale speech recognition setting, where we have used around 65,000 hours of training data. We investigated various aspects on scaling up Transformers, including model initialization, warmup training as well as different Layer Normalization strategies. In the streaming condition, we compared the widely used attention mask based future context lookahead approach to the Transformer-XL network. From our experiments, we show that Transformers can achieve around 6% relative word error rate (WER) reduction compared to the BLSTM baseline in the offline fashion, while in the streaming fashion, Transformer-XL is comparable to LC-BLSTM with 800 millisecond latency constraint.
L-Vector: Neural Label Embedding for Domain Adaptation
Apr 25, 2020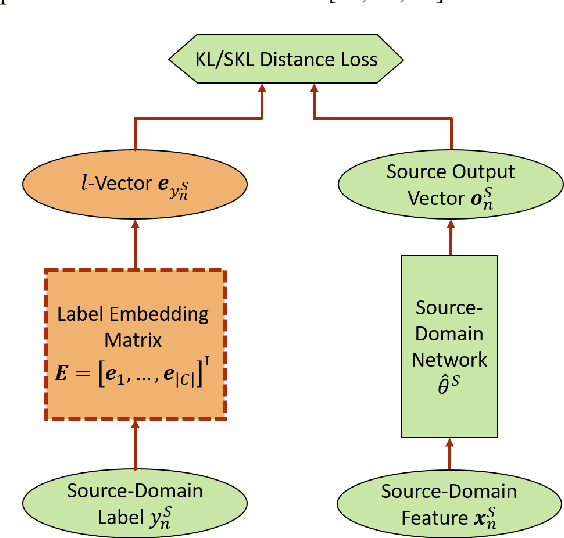
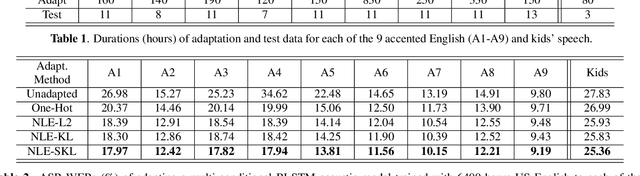
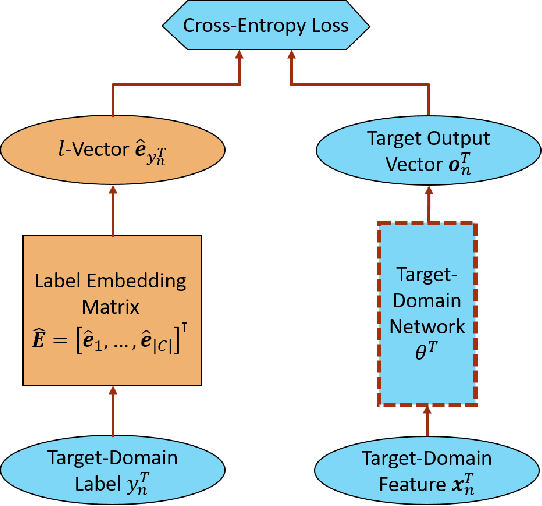
We propose a novel neural label embedding (NLE) scheme for the domain adaptation of a deep neural network (DNN) acoustic model with unpaired data samples from source and target domains. With NLE method, we distill the knowledge from a powerful source-domain DNN into a dictionary of label embeddings, or l-vectors, one for each senone class. Each l-vector is a representation of the senone-specific output distributions of the source-domain DNN and is learned to minimize the average L2, Kullback-Leibler (KL) or symmetric KL distance to the output vectors with the same label through simple averaging or standard back-propagation. During adaptation, the l-vectors serve as the soft targets to train the target-domain model with cross-entropy loss. Without parallel data constraint as in the teacher-student learning, NLE is specially suited for the situation where the paired target-domain data cannot be simulated from the source-domain data. We adapt a 6400 hours multi-conditional US English acoustic model to each of the 9 accented English (80 to 830 hours) and kids' speech (80 hours). NLE achieves up to 14.1% relative word error rate reduction over direct re-training with one-hot labels.
* 5 pages, 2 figure, ICASSP 2020
Advances in Online Audio-Visual Meeting Transcription
Dec 10, 2019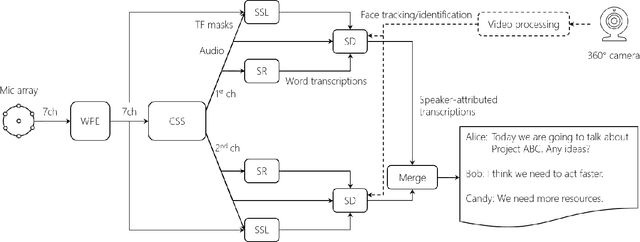

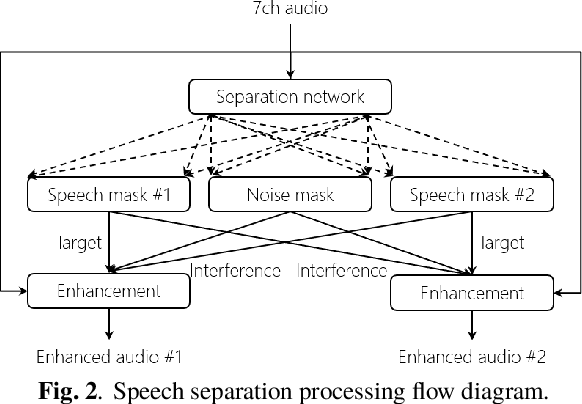
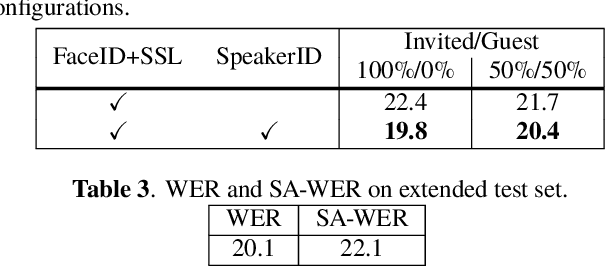
This paper describes a system that generates speaker-annotated transcripts of meetings by using a microphone array and a 360-degree camera. The hallmark of the system is its ability to handle overlapped speech, which has been an unsolved problem in realistic settings for over a decade. We show that this problem can be addressed by using a continuous speech separation approach. In addition, we describe an online audio-visual speaker diarization method that leverages face tracking and identification, sound source localization, speaker identification, and, if available, prior speaker information for robustness to various real world challenges. All components are integrated in a meeting transcription framework called SRD, which stands for "separate, recognize, and diarize". Experimental results using recordings of natural meetings involving up to 11 attendees are reported. The continuous speech separation improves a word error rate (WER) by 16.1% compared with a highly tuned beamformer. When a complete list of meeting attendees is available, the discrepancy between WER and speaker-attributed WER is only 1.0%, indicating accurate word-to-speaker association. This increases marginally to 1.6% when 50% of the attendees are unknown to the system.
Low-Latency Speaker-Independent Continuous Speech Separation
Apr 13, 2019
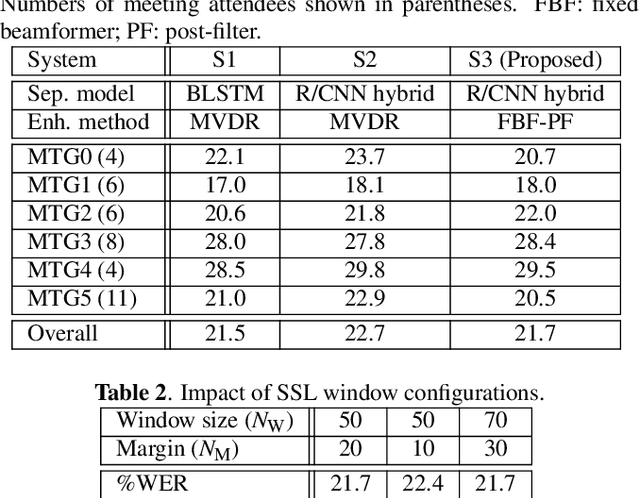

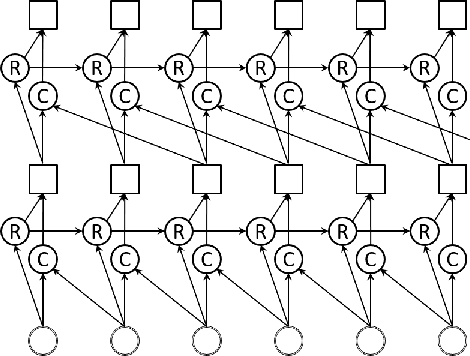
Speaker independent continuous speech separation (SI-CSS) is a task of converting a continuous audio stream, which may contain overlapping voices of unknown speakers, into a fixed number of continuous signals each of which contains no overlapping speech segment. A separated, or cleaned, version of each utterance is generated from one of SI-CSS's output channels nondeterministically without being split up and distributed to multiple channels. A typical application scenario is transcribing multi-party conversations, such as meetings, recorded with microphone arrays. The output signals can be simply sent to a speech recognition engine because they do not include speech overlaps. The previous SI-CSS method uses a neural network trained with permutation invariant training and a data-driven beamformer and thus requires much processing latency. This paper proposes a low-latency SI-CSS method whose performance is comparable to that of the previous method in a microphone array-based meeting transcription task.This is achieved (1) by using a new speech separation network architecture combined with a double buffering scheme and (2) by performing enhancement with a set of fixed beamformers followed by a neural post-filter.
Layer Trajectory LSTM
Aug 28, 2018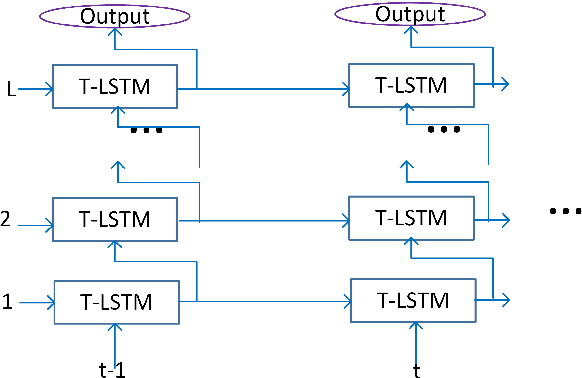
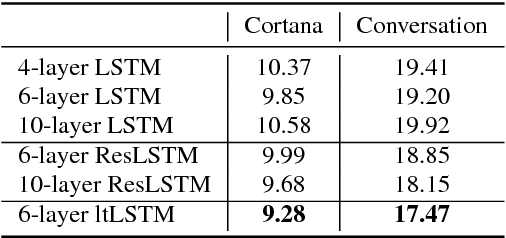
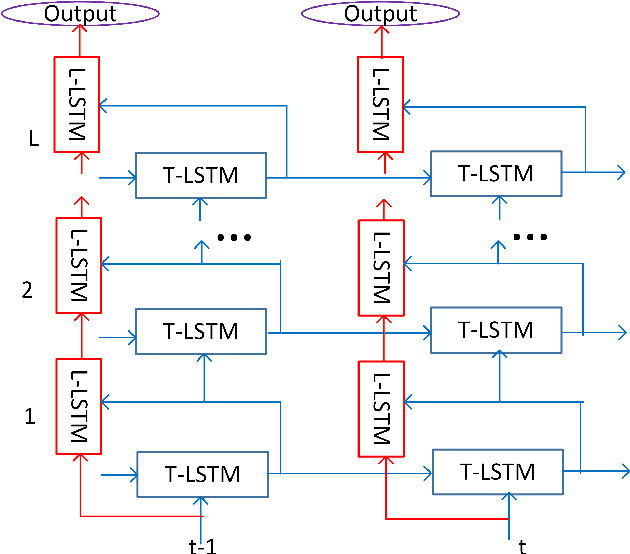
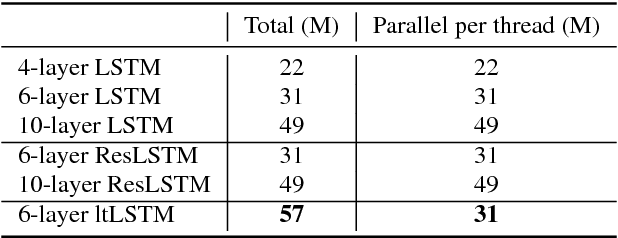
It is popular to stack LSTM layers to get better modeling power, especially when large amount of training data is available. However, an LSTM-RNN with too many vanilla LSTM layers is very hard to train and there still exists the gradient vanishing issue if the network goes too deep. This issue can be partially solved by adding skip connections between layers, such as residual LSTM. In this paper, we propose a layer trajectory LSTM (ltLSTM) which builds a layer-LSTM using all the layer outputs from a standard multi-layer time-LSTM. This layer-LSTM scans the outputs from time-LSTMs, and uses the summarized layer trajectory information for final senone classification. The forward-propagation of time-LSTM and layer-LSTM can be handled in two separate threads in parallel so that the network computation time is the same as the standard time-LSTM. With a layer-LSTM running through layers, a gated path is provided from the output layer to the bottom layer, alleviating the gradient vanishing issue. Trained with 30 thousand hours of EN-US Microsoft internal data, the proposed ltLSTM performed significantly better than the standard multi-layer LSTM and residual LSTM, with up to 9.0% relative word error rate reduction across different tasks.
Developing Far-Field Speaker System Via Teacher-Student Learning
Apr 14, 2018
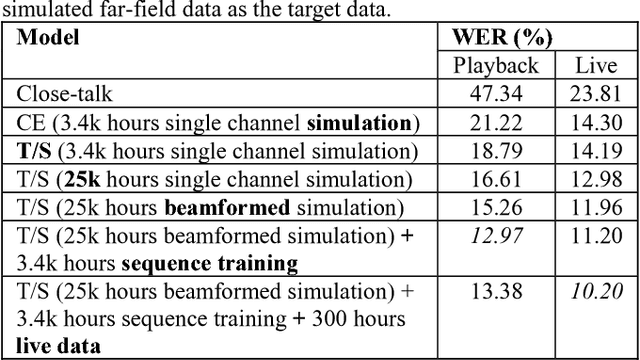
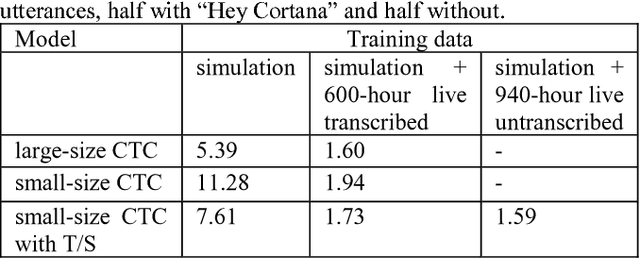
In this study, we develop the keyword spotting (KWS) and acoustic model (AM) components in a far-field speaker system. Specifically, we use teacher-student (T/S) learning to adapt a close-talk well-trained production AM to far-field by using parallel close-talk and simulated far-field data. We also use T/S learning to compress a large-size KWS model into a small-size one to fit the device computational cost. Without the need of transcription, T/S learning well utilizes untranscribed data to boost the model performance in both the AM adaptation and KWS model compression. We further optimize the models with sequence discriminative training and live data to reach the best performance of systems. The adapted AM improved from the baseline by 72.60% and 57.16% relative word error rate reduction on play-back and live test data, respectively. The final KWS model size was reduced by 27 times from a large-size KWS model without losing accuracy.