 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniDirector: General Multi-Shot Camera Cloning without Cross-Paired Data
Jun 11, 2026Cloning camera motion from reference videos is an important task in video generation, as videos provide intuitive and precise control. Existing methods either directly use parametric representations that fail to handle multi-shot generation or synthesize cross-paired data, which suffer from data scarcity, resulting in poor performance in complicated camera motion cloning. To address these issues, we introduce a general camera motion representation that encodes cameras as grid motion videos. This camera grid represents the camera parameters visually and supports the integration of diverse trajectories for multi-shot video generation. Building upon this, we propose OmniDirector, a unified framework trained on a million-scale camera grid-video pairs that coordinates characters, actions, and cameras to provide director-level control for multimodal diffusion transformers. Furthermore, we design a novel hierarchical prompt expansion agent that harmoniously integrates different control signals by systematically describing camera motion and visual content through understanding signal relationships. Extensive experiments demonstrate the superior performance and outstanding controllability of our framework. Project page: https://ymlinfeng.github.io/OmniDirector.github.io/
ARGUS: Stacked Multi-View Identity Mosaic Injection for Subject-Preserving Video Generation
Jun 10, 2026Subject-preserving video generation is not solved by frontal-face similarity alone: a generated person must remain recognizable across motion, large viewpoint changes, expression shifts, occlusion, scale variation, and conflicts among text, first-frame, and identity references. We argue that the central bottleneck is the point-reference paradigm, which collapses identity into a single static observation entangled with pose, accessories, lighting, background, and camera statistics. We introduce Argus, a Wan-based framework centered on Stacked Multi-View Identity Mosaic Injection (SMII). SMII converts MLLM-selected image/video identity evidence into a 3*3 stacked mosaic, synchronizes the mosaic with the current diffusion time, and injects it as negative-time read-only memory in Wan's native token space. This turns identity from an external clean adapter or a single reference image into a compact dynamic distribution. Around SMII, an MLLM Identity Director selects informative identity moments and resolves condition conflicts, while no-cross-pair counterfactual training, Temporal Identity Annealing, and Adaptive Self-Likeness Guidance improve robustness without paired subject-video supervision. We further release HardID-Celeb, a public-figure identity-stress benchmark, and introduce YawScore and OccScore to probe large-yaw and first-frame-occlusion robustness. Argus achieves state-of-the-art results on OpenS2V-Eval Human-Domain, reaching 64.38 Total Score, 71.86 FaceSim, 51.62 NexusScore, and 79.14 NaturalScore. On HardID-Celeb, Argus obtains 76.80 FaceSim and improves YawScore and OccScore by 12.60 and 15.10 points over the strongest baselines, demonstrating that dynamic identity memory and large-scale counterfactual self-supervision are highly effective for subject-preserving video generation.
Equilibrium Residuals Expose Three Regimes of Matrix-Game Strategic Reasoning in Language Models
May 11, 2026Large language models can score well on named game-theory benchmarks while failing on the same strategic computation once semantic cues are removed. We show this gap with procedurally generated zero-sum matrix games: a model that recognizes familiar games drops to 34%, 18%, and 2% success on anonymous $2{\times}2$, $3{\times}3$, and $5{\times}5$ payoff matrices. The benchmark separates semantic recall, learned approximate Nash computation, and an output-interface bottleneck that limits scale. Training only on $2{\times}2$ and $3{\times}3$ games, supervised fine-tuning raises unseen $5{\times}5$--$7{\times}7$ success from 2% to 61%, while exploitability-reward training averages 37% with high seed variance. We prove that the exploitability residual is $2$-Lipschitz in payoff perturbations, unlike discontinuous vertex-returning LP equilibrium selectors, explaining why residual training can transfer under payoff shifts even when formatting instability limits mean performance. A dominated-action padding experiment provides causal evidence: trained models solve $3{\times}3$ games embedded in much larger matrices, while random-padded controls fail and dense $12{\times}12$ games remain near failure. Procedural evaluation is therefore necessary for measuring strategic reasoning, and residual rewards expose a real but format-limited route to approximate equilibrium computation.
IOSVLM: A 3D Vision-Language Model for Unified Dental Diagnosis from Intraoral Scans
Mar 17, 20263D intraoral scans (IOS) are increasingly adopted in routine dentistry due to abundant geometric evidence, and unified multi-disease diagnosis is desirable for clinical documentation and communication. While recent works introduce dental vision-language models (VLMs) to enable unified diagnosis and report generation on 2D images or multi-view images rendered from IOS, they do not fully leverage native 3D geometry. Such work is necessary and also challenging, due to: (i) heterogeneous scan forms and the complex IOS topology, (ii) multi-disease co-occurrence with class imbalance and fine-grained morphological ambiguity, (iii) limited paired 3D IOS-text data. Thus, we present IOSVLM, an end-to-end 3D VLM that represents scans as point clouds and follows a 3D encoder-projector-LLM design for unified diagnosis and generative visual question-answering (VQA), together with IOSVQA, a large-scale multi-source IOS diagnosis VQA dataset comprising 19,002 cases and 249,055 VQA pairs over 23 oral diseases and heterogeneous scan types. To address the distribution gap between color-free IOS data and color-dependent 3D pre-training, we propose a geometry-to-chromatic proxy that stabilizes fine-grained geometric perception and cross-modal alignment. A two-stage curriculum training strategy further enhances robustness. IOSVLM consistently outperforms strong baselines, achieving gains of at least +9.58% macro accuracy and +1.46% macro F1, indicating the effectiveness of direct 3D geometry modeling for IOS-based diagnosis.
When to Lock Attention: Training-Free KV Control in Video Diffusion
Mar 10, 2026Maintaining background consistency while enhancing foreground quality remains a core challenge in video editing. Injecting full-image information often leads to background artifacts, whereas rigid background locking severely constrains the model's capacity for foreground generation. To address this issue, we propose KV-Lock, a training-free framework tailored for DiT-based video diffusion models. Our core insight is that the hallucination metric (variance of denoising prediction) directly quantifies generation diversity, which is inherently linked to the classifier-free guidance (CFG) scale. Building upon this, KV-Lock leverages diffusion hallucination detection to dynamically schedule two key components: the fusion ratio between cached background key-values (KVs) and newly generated KVs, and the CFG scale. When hallucination risk is detected, KV-Lock strengthens background KV locking and simultaneously amplifies conditional guidance for foreground generation, thereby mitigating artifacts and improving generation fidelity. As a training-free, plug-and-play module, KV-Lock can be easily integrated into any pre-trained DiT-based models. Extensive experiments validate that our method outperforms existing approaches in improved foreground quality with high background fidelity across various video editing tasks.
GCAgent: Enhancing Group Chat Communication through Dialogue Agents System
Mar 05, 2026As a key form in online social platforms, group chat is a popular space for interest exchange or problem-solving, but its effectiveness is often hindered by inactivity and management challenges. While recent large language models (LLMs) have powered impressive one-to-one conversational agents, their seamlessly integration into multi-participant conversations remains unexplored. To address this gap, we introduce GCAgent, an LLM-driven system for enhancing group chats communication with both entertainment- and utility-oriented dialogue agents. The system comprises three tightly integrated modules: Agent Builder, which customizes agents to align with users' interests; Dialogue Manager, which coordinates dialogue states and manage agent invocations; and Interface Plugins, which reduce interaction barriers by three distinct tools. Through extensive experiment, GCAgent achieved an average score of 4.68 across various criteria and was preferred in 51.04\% of cases compared to its base model. Additionally, in real-world deployments over 350 days, it increased message volume by 28.80\%, significantly improving group activity and engagement. Overall, this work presents a practical blueprint for extending LLM-based dialogue agent from one-party chats to multi-party group scenarios.
EComStage: Stage-wise and Orientation-specific Benchmarking for Large Language Models in E-commerce
Jan 06, 2026Large Language Model (LLM)-based agents are increasingly deployed in e-commerce applications to assist customer services in tasks such as product inquiries, recommendations, and order management. Existing benchmarks primarily evaluate whether these agents successfully complete the final task, overlooking the intermediate reasoning stages that are crucial for effective decision-making. To address this gap, we propose EComStage, a unified benchmark for evaluating agent-capable LLMs across the comprehensive stage-wise reasoning process: Perception (understanding user intent), Planning (formulating an action plan), and Action (executing the decision). EComStage evaluates LLMs through seven separate representative tasks spanning diverse e-commerce scenarios, with all samples human-annotated and quality-checked. Unlike prior benchmarks that focus only on customer-oriented interactions, EComStage also evaluates merchant-oriented scenarios, including promotion management, content review, and operational support relevant to real-world applications. We evaluate a wide range of over 30 LLMs, spanning from 1B to over 200B parameters, including open-source models and closed-source APIs, revealing stage/orientation-specific strengths and weaknesses. Our results provide fine-grained, actionable insights for designing and optimizing LLM-based agents in real-world e-commerce settings.
RedOne 2.0: Rethinking Domain-specific LLM Post-Training in Social Networking Services
Nov 10, 2025As a key medium for human interaction and information exchange, social networking services (SNS) pose unique challenges for large language models (LLMs): heterogeneous workloads, fast-shifting norms and slang, and multilingual, culturally diverse corpora that induce sharp distribution shift. Supervised fine-tuning (SFT) can specialize models but often triggers a ``seesaw'' between in-distribution gains and out-of-distribution robustness, especially for smaller models. To address these challenges, we introduce RedOne 2.0, an SNS-oriented LLM trained with a progressive, RL-prioritized post-training paradigm designed for rapid and stable adaptation. The pipeline consist in three stages: (1) Exploratory Learning on curated SNS corpora to establish initial alignment and identify systematic weaknesses; (2) Targeted Fine-Tuning that selectively applies SFT to the diagnosed gaps while mixing a small fraction of general data to mitigate forgetting; and (3) Refinement Learning that re-applies RL with SNS-centric signals to consolidate improvements and harmonize trade-offs across tasks. Across various tasks spanning three categories, our 4B scale model delivers an average improvements about 2.41 over the 7B sub-optimal baseline. Additionally, RedOne 2.0 achieves average performance lift about 8.74 from the base model with less than half the data required by SFT-centric method RedOne, evidencing superior data efficiency and stability at compact scales. Overall, RedOne 2.0 establishes a competitive, cost-effective baseline for domain-specific LLMs in SNS scenario, advancing capability without sacrificing robustness.
SynPo: Boosting Training-Free Few-Shot Medical Segmentation via High-Quality Negative Prompts
Jun 18, 2025The advent of Large Vision Models (LVMs) offers new opportunities for few-shot medical image segmentation. However, existing training-free methods based on LVMs fail to effectively utilize negative prompts, leading to poor performance on low-contrast medical images. To address this issue, we propose SynPo, a training-free few-shot method based on LVMs (e.g., SAM), with the core insight: improving the quality of negative prompts. To select point prompts in a more reliable confidence map, we design a novel Confidence Map Synergy Module by combining the strengths of DINOv2 and SAM. Based on the confidence map, we select the top-k pixels as the positive points set and choose the negative points set using a Gaussian distribution, followed by independent K-means clustering for both sets. Then, these selected points are leveraged as high-quality prompts for SAM to get the segmentation results. Extensive experiments demonstrate that SynPo achieves performance comparable to state-of-the-art training-based few-shot methods.
3D-RAD: A Comprehensive 3D Radiology Med-VQA Dataset with Multi-Temporal Analysis and Diverse Diagnostic Tasks
Jun 11, 2025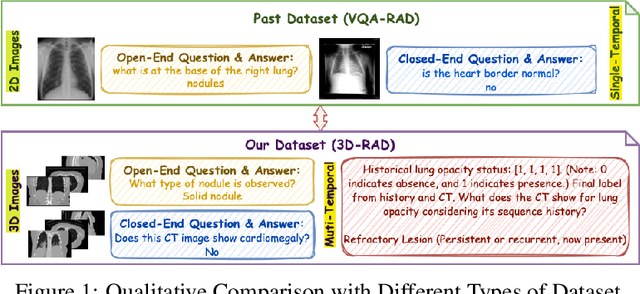
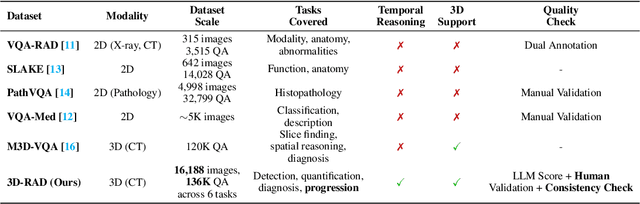
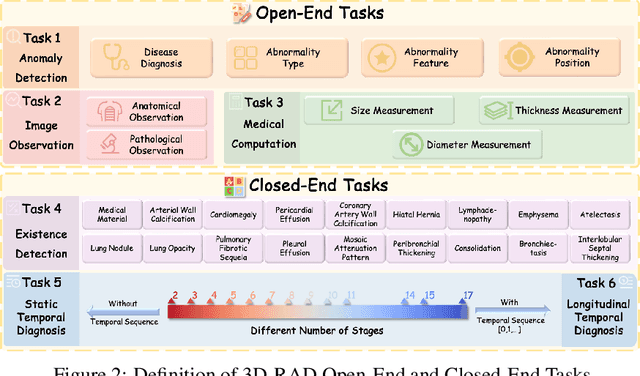
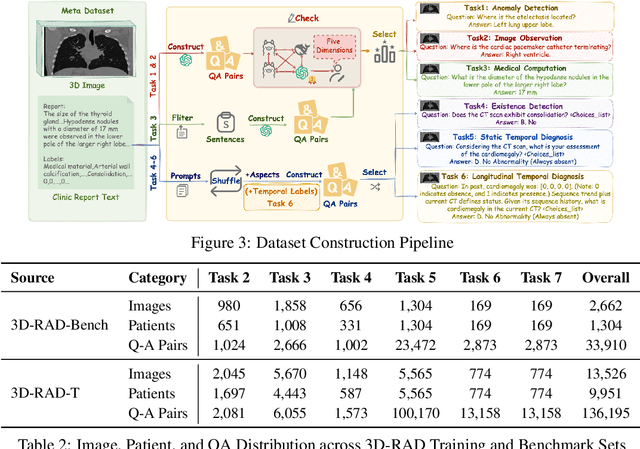
Medical Visual Question Answering (Med-VQA) holds significant potential for clinical decision support, yet existing efforts primarily focus on 2D imaging with limited task diversity. This paper presents 3D-RAD, a large-scale dataset designed to advance 3D Med-VQA using radiology CT scans. The 3D-RAD dataset encompasses six diverse VQA tasks: anomaly detection, image observation, medical computation, existence detection, static temporal diagnosis, and longitudinal temporal diagnosis. It supports both open- and closed-ended questions while introducing complex reasoning challenges, including computational tasks and multi-stage temporal analysis, to enable comprehensive benchmarking. Extensive evaluations demonstrate that existing vision-language models (VLMs), especially medical VLMs exhibit limited generalization, particularly in multi-temporal tasks, underscoring the challenges of real-world 3D diagnostic reasoning. To drive future advancements, we release a high-quality training set 3D-RAD-T of 136,195 expert-aligned samples, showing that fine-tuning on this dataset could significantly enhance model performance. Our dataset and code, aiming to catalyze multimodal medical AI research and establish a robust foundation for 3D medical visual understanding, are publicly available at https://github.com/Tang-xiaoxiao/M3D-RAD.