 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniLiDAR: A Unified Diffusion Framework for Multi-Domain 3D LiDAR Generation
May 13, 2026LiDAR scene generation is increasingly important for scalable simulation and synthetic data creation, especially under diverse sensing conditions that are costly to capture at scale. Typically, diffusion-based LiDAR generators are developed under single-domain settings, requiring separate models for different datasets or sensing conditions and hindering unified, controllable synthesis under heterogeneous distribution shifts. To this end, we present OmniLiDAR, a unified text-conditioned diffusion framework that generates LiDAR scans in a shared range-image representation across eight representative domains spanning three shift types: adverse weather, sensor-configuration changes (e.g., reduced beams), and cross-platform acquisition (vehicle, drone, and quadruped). To enable training a single model over heterogeneous domains without isolating optimization by domain, we introduce a Cross-Domain Training Strategy (CDTS) that mixes domains within each mini-batch and leverages conditioning to steer generation. We further propose Cross-Domain Feature Modeling (CDFM), which captures directional dependencies along azimuth and elevation axes to reflect the anisotropic scanning structure of range images, and Domain-Adaptive Feature Scaling (DAFS) as a lightweight modulation to account for structured domain-dependent feature shifts during denoising. In the absence of a public consolidated benchmark, we construct an 8-domain dataset by combining real-world scans with physically based weather simulation and systematic beam reduction while following official splits. Extensive experiments demonstrate strong generation fidelity and consistent gains in downstream use cases, including generative data augmentation for LiDAR semantic segmentation and 3D object detection, as well as robustness evaluation under corruptions, with consistent benefits in limited-label regimes.
Is Your Driving World Model an All-Around Player?
May 11, 2026Today's driving world models can generate remarkably realistic dash-cam videos, yet no single model excels universally. Some generate photorealistic textures but violate basic physics; others maintain geometric consistency but fail when subjected to closed-loop planning. This disconnect exposes a critical gap: the field evaluates how real generated worlds appear, but rarely whether they behave realistically. We introduce WorldLens, a unified benchmark that measures world-model fidelity across the full spectrum, from pixel quality and 4D geometry to closed-loop driving and human perceptual alignment, through five complementary aspects and 24 standardized dimensions. Our evaluation of six representative models reveals that no existing approach dominates across all axes: texture-rich models violate geometry, geometry-aware models lack behavioral fidelity, and even the strongest performers achieve only 2-3 out of 10 on human realism ratings. To bridge algorithmic metrics with human perception, we further contribute WorldLens-26K, a 26,808-entry human-annotated preference dataset pairing numerical scores with textual rationales, and WorldLens-Agent, a vision-language evaluator distilled from these judgments that enables scalable, explainable auto-assessment. Together, the benchmark, dataset, and agent form a unified ecosystem for assessing generated worlds not merely by visual appeal, but by physical and behavioral fidelity.
HINT: Hierarchical Interaction Modeling for Autoregressive Multi-Human Motion Generation
Jan 28, 2026Text-driven multi-human motion generation with complex interactions remains a challenging problem. Despite progress in performance, existing offline methods that generate fixed-length motions with a fixed number of agents, are inherently limited in handling long or variable text, and varying agent counts. These limitations naturally encourage autoregressive formulations, which predict future motions step by step conditioned on all past trajectories and current text guidance. In this work, we introduce HINT, the first autoregressive framework for multi-human motion generation with Hierarchical INTeraction modeling in diffusion. First, HINT leverages a disentangled motion representation within a canonicalized latent space, decoupling local motion semantics from inter-person interactions. This design facilitates direct adaptation to varying numbers of human participants without requiring additional refinement. Second, HINT adopts a sliding-window strategy for efficient online generation, and aggregates local within-window and global cross-window conditions to capture past human history, inter-person dependencies, and align with text guidance. This strategy not only enables fine-grained interaction modeling within each window but also preserves long-horizon coherence across all the long sequence. Extensive experiments on public benchmarks demonstrate that HINT matches the performance of strong offline models and surpasses autoregressive baselines. Notably, on InterHuman, HINT achieves an FID of 3.100, significantly improving over the previous state-of-the-art score of 5.154.
WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
Dec 11, 2025Generative world models are reshaping embodied AI, enabling agents to synthesize realistic 4D driving environments that look convincing but often fail physically or behaviorally. Despite rapid progress, the field still lacks a unified way to assess whether generated worlds preserve geometry, obey physics, or support reliable control. We introduce WorldLens, a full-spectrum benchmark evaluating how well a model builds, understands, and behaves within its generated world. It spans five aspects -- Generation, Reconstruction, Action-Following, Downstream Task, and Human Preference -- jointly covering visual realism, geometric consistency, physical plausibility, and functional reliability. Across these dimensions, no existing world model excels universally: those with strong textures often violate physics, while geometry-stable ones lack behavioral fidelity. To align objective metrics with human judgment, we further construct WorldLens-26K, a large-scale dataset of human-annotated videos with numerical scores and textual rationales, and develop WorldLens-Agent, an evaluation model distilled from these annotations to enable scalable, explainable scoring. Together, the benchmark, dataset, and agent form a unified ecosystem for measuring world fidelity -- standardizing how future models are judged not only by how real they look, but by how real they behave.
SPIRAL: Semantic-Aware Progressive LiDAR Scene Generation
May 28, 2025Leveraging recent diffusion models, LiDAR-based large-scale 3D scene generation has achieved great success. While recent voxel-based approaches can generate both geometric structures and semantic labels, existing range-view methods are limited to producing unlabeled LiDAR scenes. Relying on pretrained segmentation models to predict the semantic maps often results in suboptimal cross-modal consistency. To address this limitation while preserving the advantages of range-view representations, such as computational efficiency and simplified network design, we propose Spiral, a novel range-view LiDAR diffusion model that simultaneously generates depth, reflectance images, and semantic maps. Furthermore, we introduce novel semantic-aware metrics to evaluate the quality of the generated labeled range-view data. Experiments on the SemanticKITTI and nuScenes datasets demonstrate that Spiral achieves state-of-the-art performance with the smallest parameter size, outperforming two-step methods that combine the generative and segmentation models. Additionally, we validate that range images generated by Spiral can be effectively used for synthetic data augmentation in the downstream segmentation training, significantly reducing the labeling effort on LiDAR data.
SeaLion: Semantic Part-Aware Latent Point Diffusion Models for 3D Generation
May 23, 2025Denoising diffusion probabilistic models have achieved significant success in point cloud generation, enabling numerous downstream applications, such as generative data augmentation and 3D model editing. However, little attention has been given to generating point clouds with point-wise segmentation labels, as well as to developing evaluation metrics for this task. Therefore, in this paper, we present SeaLion, a novel diffusion model designed to generate high-quality and diverse point clouds with fine-grained segmentation labels. Specifically, we introduce the semantic part-aware latent point diffusion technique, which leverages the intermediate features of the generative models to jointly predict the noise for perturbed latent points and associated part segmentation labels during the denoising process, and subsequently decodes the latent points to point clouds conditioned on part segmentation labels. To effectively evaluate the quality of generated point clouds, we introduce a novel point cloud pairwise distance calculation method named part-aware Chamfer distance (p-CD). This method enables existing metrics, such as 1-NNA, to measure both the local structural quality and inter-part coherence of generated point clouds. Experiments on the large-scale synthetic dataset ShapeNet and real-world medical dataset IntrA demonstrate that SeaLion achieves remarkable performance in generation quality and diversity, outperforming the existing state-of-the-art model, DiffFacto, by 13.33% and 6.52% on 1-NNA (p-CD) across the two datasets. Experimental analysis shows that SeaLion can be trained semi-supervised, thereby reducing the demand for labeling efforts. Lastly, we validate the applicability of SeaLion in generative data augmentation for training segmentation models and the capability of SeaLion to serve as a tool for part-aware 3D shape editing.
Generative Data Augmentation for Object Point Cloud Segmentation
May 23, 2025Data augmentation is widely used to train deep learning models to address data scarcity. However, traditional data augmentation (TDA) typically relies on simple geometric transformation, such as random rotation and rescaling, resulting in minimal data diversity enrichment and limited model performance improvement. State-of-the-art generative models for 3D shape generation rely on the denoising diffusion probabilistic models and manage to generate realistic novel point clouds for 3D content creation and manipulation. Nevertheless, the generated 3D shapes lack associated point-wise semantic labels, restricting their usage in enlarging the training data for point cloud segmentation tasks. To bridge the gap between data augmentation techniques and the advanced diffusion models, we extend the state-of-the-art 3D diffusion model, Lion, to a part-aware generative model that can generate high-quality point clouds conditioned on given segmentation masks. Leveraging the novel generative model, we introduce a 3-step generative data augmentation (GDA) pipeline for point cloud segmentation training. Our GDA approach requires only a small amount of labeled samples but enriches the training data with generated variants and pseudo-labeled samples, which are validated by a novel diffusion-based pseudo-label filtering method. Extensive experiments on two large-scale synthetic datasets and a real-world medical dataset demonstrate that our GDA method outperforms TDA approach and related semi-supervised and self-supervised methods.
IPCC-TP: Utilizing Incremental Pearson Correlation Coefficient for Joint Multi-Agent Trajectory Prediction
Mar 16, 2023Reliable multi-agent trajectory prediction is crucial for the safe planning and control of autonomous systems. Compared with single-agent cases, the major challenge in simultaneously processing multiple agents lies in modeling complex social interactions caused by various driving intentions and road conditions. Previous methods typically leverage graph-based message propagation or attention mechanism to encapsulate such interactions in the format of marginal probabilistic distributions. However, it is inherently sub-optimal. In this paper, we propose IPCC-TP, a novel relevance-aware module based on Incremental Pearson Correlation Coefficient to improve multi-agent interaction modeling. IPCC-TP learns pairwise joint Gaussian Distributions through the tightly-coupled estimation of the means and covariances according to interactive incremental movements. Our module can be conveniently embedded into existing multi-agent prediction methods to extend original motion distribution decoders. Extensive experiments on nuScenes and Argoverse 2 datasets demonstrate that IPCC-TP improves the performance of baselines by a large margin.
Multi-Vehicle Trajectory Prediction at Intersections using State and Intention Information
Jan 06, 2023Traditional approaches to prediction of future trajectory of road agents rely on knowing information about their past trajectory. This work rather relies only on having knowledge of the current state and intended direction to make predictions for multiple vehicles at intersections. Furthermore, message passing of this information between the vehicles provides each one of them a more holistic overview of the environment allowing for a more informed prediction. This is done by training a neural network which takes the state and intent of the multiple vehicles to predict their future trajectory. Using the intention as an input allows our approach to be extended to additionally control the multiple vehicles to drive towards desired paths. Experimental results demonstrate the robustness of our approach both in terms of trajectory prediction and vehicle control at intersections. The complete training and evaluation code for this work is available here: \url{https://github.com/Dekai21/Multi_Agent_Intersection}.
Neuromorphic Visual Odometry System for Intelligent Vehicle Application with Bio-inspired Vision Sensor
Sep 05, 2019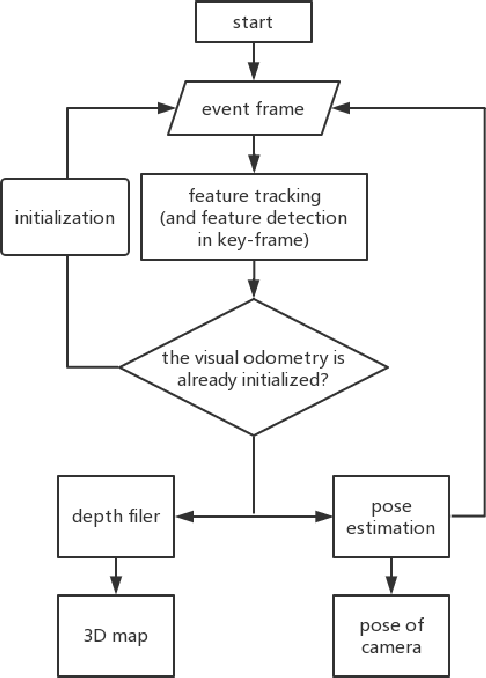

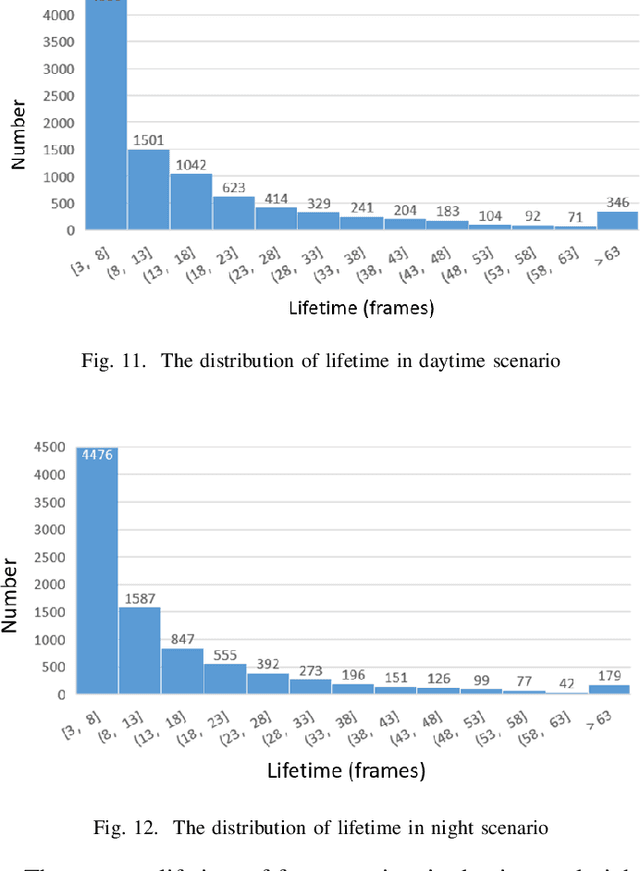
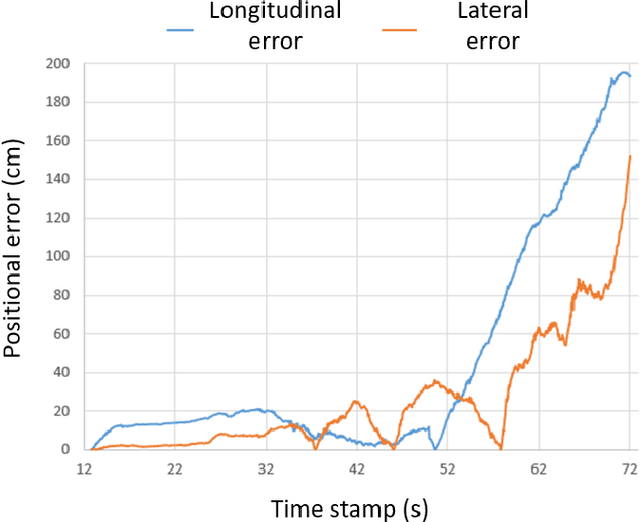
The neuromorphic camera is a brand new vision sensor that has emerged in recent years. In contrast to the conventional frame-based camera, the neuromorphic camera only transmits local pixel-level changes at the time of its occurrence and provides an asynchronous event stream with low latency. It has the advantages of extremely low signal delay, low transmission bandwidth requirements, rich information of edges, high dynamic range etc., which make it a promising sensor in the application of in-vehicle visual odometry system. This paper proposes a neuromorphic in-vehicle visual odometry system using feature tracking algorithm. To the best of our knowledge, this is the first in-vehicle visual odometry system that only uses a neuromorphic camera, and its performance test is carried out on actual driving datasets. In addition, an in-depth analysis of the results of the experiment is provided. The work of this paper verifies the feasibility of in-vehicle visual odometry system using neuromorphic cameras.