 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Summarize and Answer Questions about a Virtual Robot's Past Actions
Jun 16, 2023When robots perform long action sequences, users will want to easily and reliably find out what they have done. We therefore demonstrate the task of learning to summarize and answer questions about a robot agent's past actions using natural language alone. A single system with a large language model at its core is trained to both summarize and answer questions about action sequences given ego-centric video frames of a virtual robot and a question prompt. To enable training of question answering, we develop a method to automatically generate English-language questions and answers about objects, actions, and the temporal order in which actions occurred during episodes of robot action in the virtual environment. Training one model to both summarize and answer questions enables zero-shot transfer of representations of objects learned through question answering to improved action summarization. % involving objects not seen in training to summarize.
IndustReal: Transferring Contact-Rich Assembly Tasks from Simulation to Reality
May 26, 2023Robotic assembly is a longstanding challenge, requiring contact-rich interaction and high precision and accuracy. Many applications also require adaptivity to diverse parts, poses, and environments, as well as low cycle times. In other areas of robotics, simulation is a powerful tool to develop algorithms, generate datasets, and train agents. However, simulation has had a more limited impact on assembly. We present IndustReal, a set of algorithms, systems, and tools that solve assembly tasks in simulation with reinforcement learning (RL) and successfully achieve policy transfer to the real world. Specifically, we propose 1) simulation-aware policy updates, 2) signed-distance-field rewards, and 3) sampling-based curricula for robotic RL agents. We use these algorithms to enable robots to solve contact-rich pick, place, and insertion tasks in simulation. We then propose 4) a policy-level action integrator to minimize error at policy deployment time. We build and demonstrate a real-world robotic assembly system that uses the trained policies and action integrator to achieve repeatable performance in the real world. Finally, we present hardware and software tools that allow other researchers to reproduce our system and results. For videos and additional details, please see http://sites.google.com/nvidia.com/industreal .
Factory: Fast Contact for Robotic Assembly
May 07, 2022
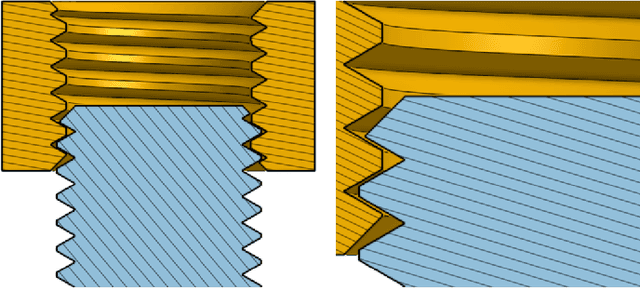


Robotic assembly is one of the oldest and most challenging applications of robotics. In other areas of robotics, such as perception and grasping, simulation has rapidly accelerated research progress, particularly when combined with modern deep learning. However, accurately, efficiently, and robustly simulating the range of contact-rich interactions in assembly remains a longstanding challenge. In this work, we present Factory, a set of physics simulation methods and robot learning tools for such applications. We achieve real-time or faster simulation of a wide range of contact-rich scenes, including simultaneous simulation of 1000 nut-and-bolt interactions. We provide $60$ carefully-designed part models, 3 robotic assembly environments, and 7 robot controllers for training and testing virtual robots. Finally, we train and evaluate proof-of-concept reinforcement learning policies for nut-and-bolt assembly. We aim for Factory to open the doors to using simulation for robotic assembly, as well as many other contact-rich applications in robotics. Please see https://sites.google.com/nvidia.com/factory for supplementary content, including videos.
Model Predictive Control for Fluid Human-to-Robot Handovers
Mar 31, 2022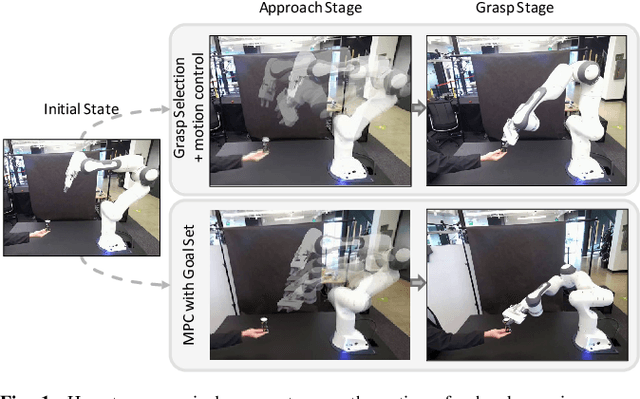


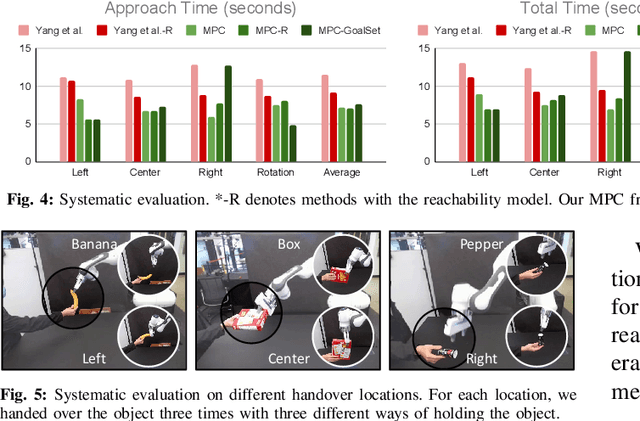
Human-robot handover is a fundamental yet challenging task in human-robot interaction and collaboration. Recently, remarkable progressions have been made in human-to-robot handovers of unknown objects by using learning-based grasp generators. However, how to responsively generate smooth motions to take an object from a human is still an open question. Specifically, planning motions that take human comfort into account is not a part of the human-robot handover process in most prior works. In this paper, we propose to generate smooth motions via an efficient model-predictive control (MPC) framework that integrates perception and complex domain-specific constraints into the optimization problem. We introduce a learning-based grasp reachability model to select candidate grasps which maximize the robot's manipulability, giving it more freedom to satisfy these constraints. Finally, we integrate a neural net force/torque classifier that detects contact events from noisy data. We conducted human-to-robot handover experiments on a diverse set of objects with several users (N=4) and performed a systematic evaluation of each module. The study shows that the users preferred our MPC approach over the baseline system by a large margin. More results and videos are available at https://sites.google.com/nvidia.com/mpc-for-handover.
Assistive Tele-op: Leveraging Transformers to Collect Robotic Task Demonstrations
Dec 09, 2021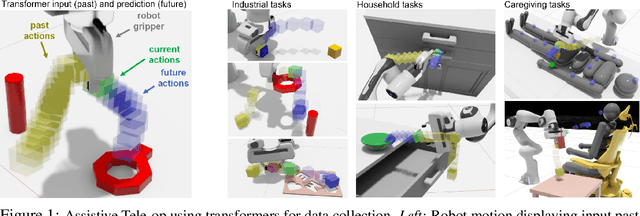
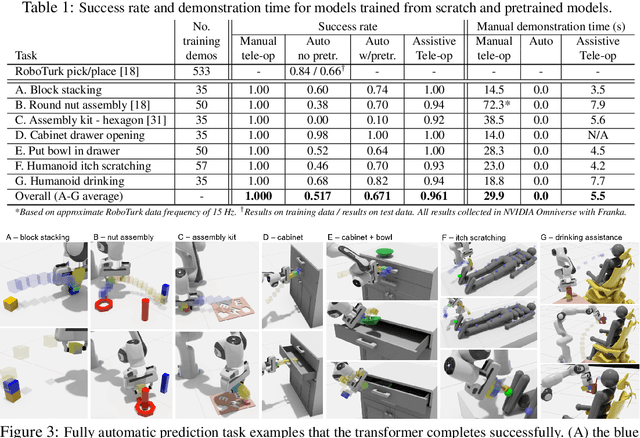
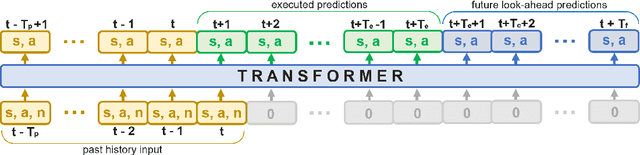
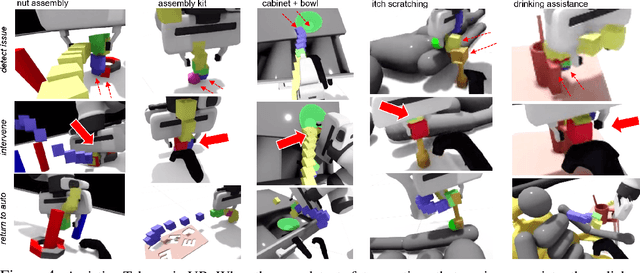
Sharing autonomy between robots and human operators could facilitate data collection of robotic task demonstrations to continuously improve learned models. Yet, the means to communicate intent and reason about the future are disparate between humans and robots. We present Assistive Tele-op, a virtual reality (VR) system for collecting robot task demonstrations that displays an autonomous trajectory forecast to communicate the robot's intent. As the robot moves, the user can switch between autonomous and manual control when desired. This allows users to collect task demonstrations with both a high success rate and with greater ease than manual teleoperation systems. Our system is powered by transformers, which can provide a window of potential states and actions far into the future -- with almost no added computation time. A key insight is that human intent can be injected at any location within the transformer sequence if the user decides that the model-predicted actions are inappropriate. At every time step, the user can (1) do nothing and allow autonomous operation to continue while observing the robot's future plan sequence, or (2) take over and momentarily prescribe a different set of actions to nudge the model back on track. We host the videos and other supplementary material at https://sites.google.com/view/assistive-teleop.
Geometric Fabrics: Generalizing Classical Mechanics to Capture the Physics of Behavior
Sep 21, 2021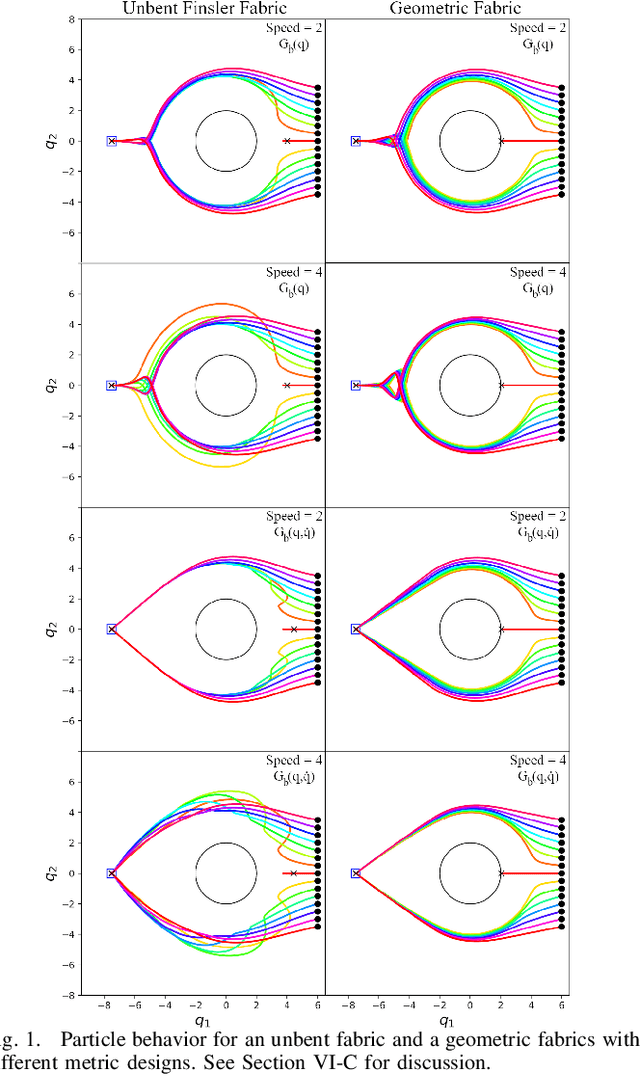
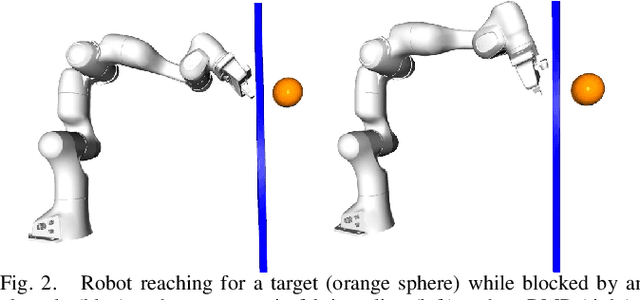
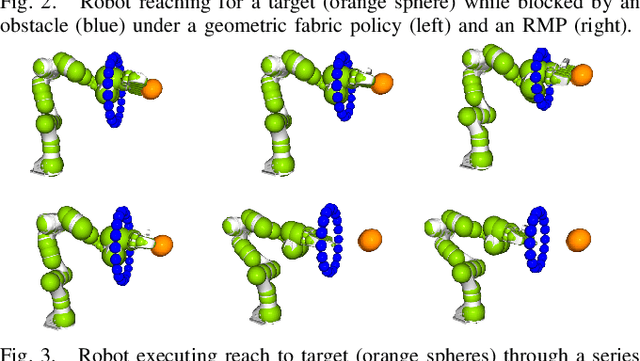
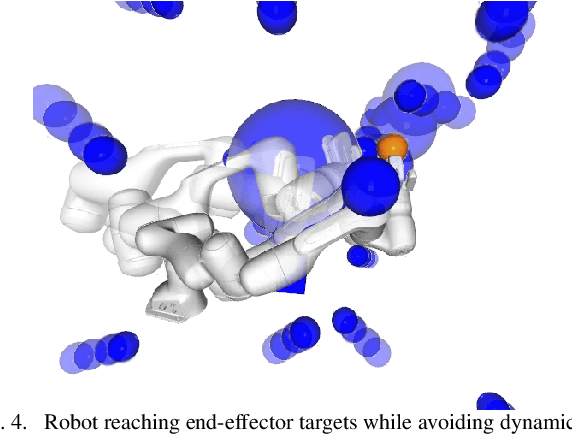
Classical mechanical systems are central to controller design in energy shaping methods of geometric control. However, their expressivity is limited by position-only metrics and the intimate link between metric and geometry. Recent work on Riemannian Motion Policies (RMPs) has shown that shedding these restrictions results in powerful design tools, but at the expense of theoretical guarantees. In this work, we generalize classical mechanics to what we call geometric fabrics, whose expressivity and theory enable the design of systems that outperform RMPs in practice. Geometric fabrics strictly generalize classical mechanics forming a new physics of behavior by first generalizing them to Finsler geometries and then explicitly bending them to shape their behavior. We develop the theory of fabrics and present both a collection of controlled experiments examining their theoretical properties and a set of robot system experiments showing improved performance over a well-engineered and hardened implementation of RMPs, our current state-of-the-art in controller design.
Visionary: Vision architecture discovery for robot learning
Mar 26, 2021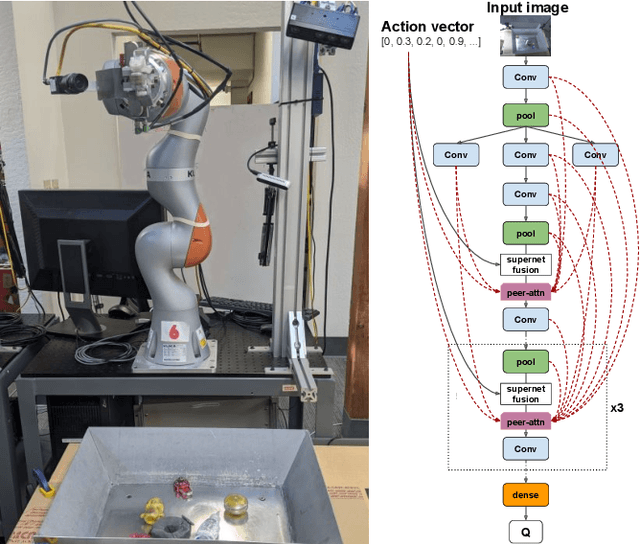
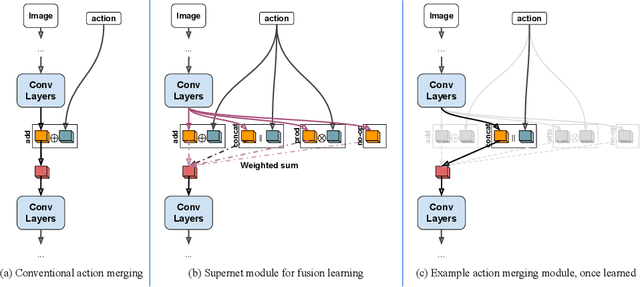
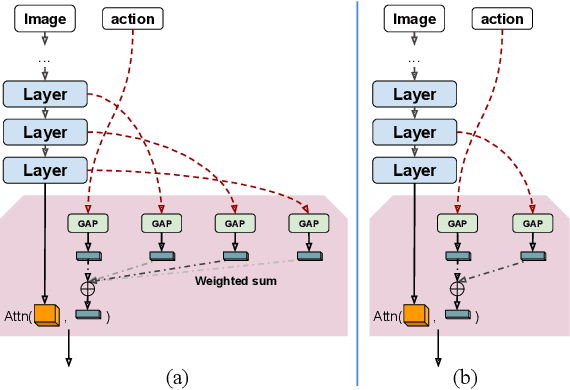
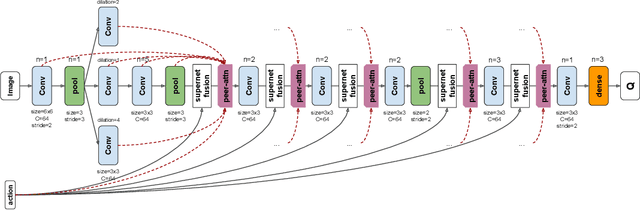
We propose a vision-based architecture search algorithm for robot manipulation learning, which discovers interactions between low dimension action inputs and high dimensional visual inputs. Our approach automatically designs architectures while training on the task - discovering novel ways of combining and attending image feature representations with actions as well as features from previous layers. The obtained new architectures demonstrate better task success rates, in some cases with a large margin, compared to a recent high performing baseline. Our real robot experiments also confirm that it improves grasping performance by 6%. This is the first approach to demonstrate a successful neural architecture search and attention connectivity search for a real-robot task.
CLAMGen: Closed-Loop Arm Motion Generation via Multi-view Vision-Based RL
Mar 24, 2021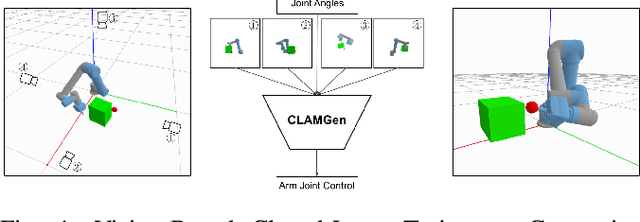
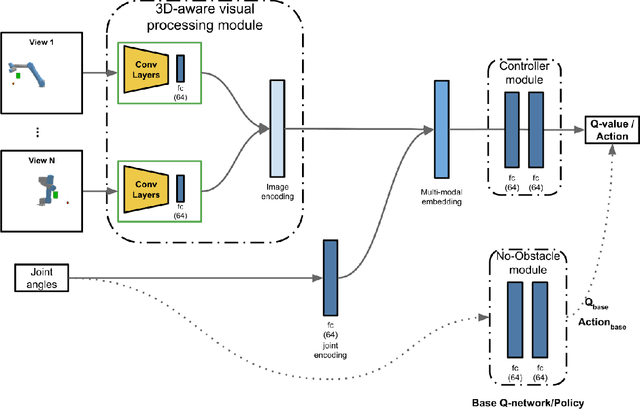

We propose a vision-based reinforcement learning (RL) approach for closed-loop trajectory generation in an arm reaching problem. Arm trajectory generation is a fundamental robotics problem which entails finding collision-free paths to move the robot's body (e.g. arm) in order to satisfy a goal (e.g. place end-effector at a point). While classical methods typically require the model of the environment to solve a planning, search or optimization problem, learning-based approaches hold the promise of directly mapping from observations to robot actions. However, learning a collision-avoidance policy using RL remains a challenge for various reasons, including, but not limited to, partial observability, poor exploration, low sample efficiency, and learning instabilities. To address these challenges, we present a residual-RL method that leverages a greedy goal-reaching RL policy as the base to improve exploration, and the base policy is augmented with residual state-action values and residual actions learned from images to avoid obstacles. Further more, we introduce novel learning objectives and techniques to improve 3D understanding from multiple image views and sample efficiency of our algorithm. Compared to RL baselines, our method achieves superior performance in terms of success rate.
Dynamic Grasping with Reachability and Motion Awareness
Mar 18, 2021
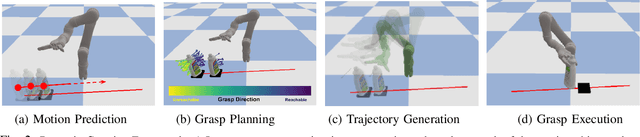
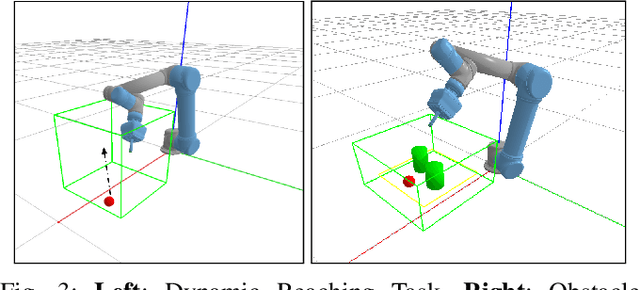
Grasping in dynamic environments presents a unique set of challenges. A stable and reachable grasp can become unreachable and unstable as the target object moves, motion planning needs to be adaptive and in real time, the delay in computation makes prediction necessary. In this paper, we present a dynamic grasping framework that is reachability-aware and motion-aware. Specifically, we model the reachability space of the robot using a signed distance field which enables us to quickly screen unreachable grasps. Also, we train a neural network to predict the grasp quality conditioned on the current motion of the target. Using these as ranking functions, we quickly filter a large grasp database to a few grasps in real time. In addition, we present a seeding approach for arm motion generation that utilizes solution from previous time step. This quickly generates a new arm trajectory that is close to the previous plan and prevents fluctuation. We implement a recurrent neural network (RNN) for modelling and predicting the object motion. Our extensive experiments demonstrate the importance of each of these components and we validate our pipeline on a real robot.
Maximizing BCI Human Feedback using Active Learning
Aug 11, 2020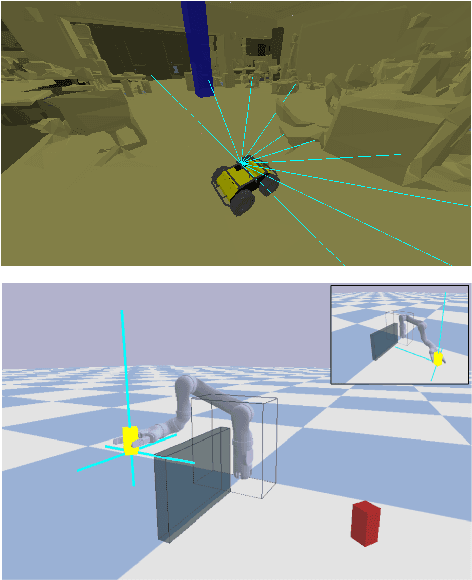
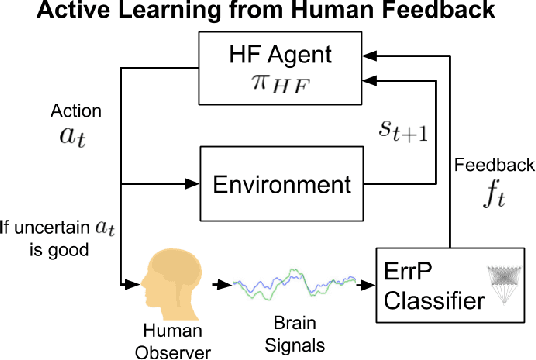
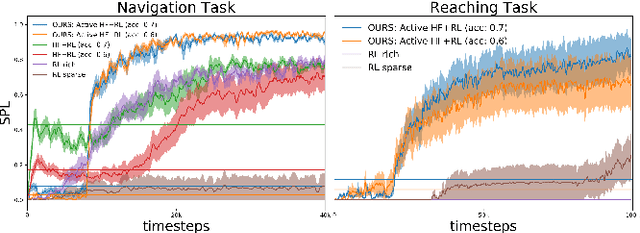
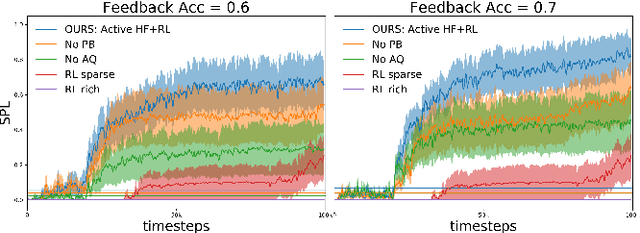
Recent advancements in \textit{Learning from Human Feedback} present an effective way to train robot agents via inputs from non-expert humans, without a need for a specially designed reward function. However, this approach needs a human to be present and attentive during robot learning to provide evaluative feedback. In addition, the amount of feedback needed grows with the level of task difficulty and the quality of human feedback might decrease over time because of fatigue. To overcome these limitations and enable learning more robot tasks with higher complexities, there is a need to maximize the quality of expensive feedback received and reduce the amount of human cognitive involvement required. In this work, we present an approach that uses active learning to smartly choose queries for the human supervisor based on the uncertainty of the robot and effectively reduces the amount of feedback needed to learn a given task. We also use a novel multiple buffer system to improve robustness to feedback noise and guard against catastrophic forgetting as the robot learning evolves. This makes it possible to learn tasks with more complexity using lesser amounts of human feedback compared to previous methods. We demonstrate the utility of our proposed method on a robot arm reaching task where the robot learns to reach a location in 3D without colliding with obstacles. Our approach is able to learn this task faster, with less human feedback and cognitive involvement, compared to previous methods that do not use active learning.