 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Bayesian Model for Gene Deconvolution and Functional Analysis in Human Endometrium Across the Menstrual Cycle
Oct 31, 2025Bulk tissue RNA sequencing of heterogeneous samples provides averaged gene expression profiles, obscuring cell type-specific dynamics. To address this, we present a probabilistic hierarchical Bayesian model that deconvolves bulk RNA-seq data into constituent cell-type expression profiles and proportions, leveraging a high-resolution single-cell reference. We apply our model to human endometrial tissue across the menstrual cycle, a context characterized by dramatic hormone-driven cellular composition changes. Our extended framework provides a principled inference of cell type proportions and cell-specific gene expression changes across cycle phases. We demonstrate the model's structure, priors, and inference strategy in detail, and we validate its performance with simulations and comparisons to existing methods. The results reveal dynamic shifts in epithelial, stromal, and immune cell fractions between menstrual phases, and identify cell-type-specific differential gene expression associated with endometrial function (e.g., decidualization markers in stromal cells during the secretory phase). We further conduct robustness tests and show that our Bayesian approach is resilient to reference mismatches and noise. Finally, we discuss the biological significance of our findings, potential clinical implications for fertility and endometrial disorders, and future directions, including integration of spatial transcriptomics.
Integrating Ontologies with Large Language Models for Enhanced Control Systems in Chemical Engineering
Oct 30, 2025This work presents an ontology-integrated large language model (LLM) framework for chemical engineering that unites structured domain knowledge with generative reasoning. The proposed pipeline aligns model training and inference with the COPE ontology through a sequence of data acquisition, semantic preprocessing, information extraction, and ontology mapping steps, producing templated question-answer pairs that guide fine-tuning. A control-focused decoding stage and citation gate enforce syntactic and factual grounding by constraining outputs to ontology-linked terms, while evaluation metrics quantify both linguistic quality and ontological accuracy. Feedback and future extensions, including semantic retrieval and iterative validation, further enhance the system's interpretability and reliability. This integration of symbolic structure and neural generation provides a transparent, auditable approach for applying LLMs to process control, safety analysis, and other critical engineering contexts.
Uncovering Autoregressive LLM Knowledge of Thematic Fit in Event Representation
Oct 19, 2024



The thematic fit estimation task measures the compatibility between a predicate (typically a verb), an argument (typically a noun phrase), and a specific semantic role assigned to the argument. Previous state-of-the-art work has focused on modeling thematic fit through distributional or neural models of event representation, trained in a supervised fashion with indirect labels. In this work, we assess whether pre-trained autoregressive LLMs possess consistent, expressible knowledge about thematic fit. We evaluate both closed and open state-of-the-art LLMs on several psycholinguistic datasets, along three axes: (1) Reasoning Form: multi-step logical reasoning (chain-of-thought prompting) vs. simple prompting. (2) Input Form: providing context (generated sentences) vs. raw tuples <predicate, argument, role>. (3) Output Form: categorical vs. numeric. Our results show that chain-of-thought reasoning is more effective on datasets with self-explanatory semantic role labels, especially Location. Generated sentences helped only in few settings, and lowered results in many others. Predefined categorical (compared to numeric) output raised GPT's results across the board with few exceptions, but lowered Llama's. We saw that semantically incoherent generated sentences, which the models lack the ability to consistently filter out, hurt reasoning and overall performance too. Our GPT-powered methods set new state-of-the-art on all tested datasets.
Episodic Memory Verbalization using Hierarchical Representations of Life-Long Robot Experience
Sep 26, 2024Verbalization of robot experience, i.e., summarization of and question answering about a robot's past, is a crucial ability for improving human-robot interaction. Previous works applied rule-based systems or fine-tuned deep models to verbalize short (several-minute-long) streams of episodic data, limiting generalization and transferability. In our work, we apply large pretrained models to tackle this task with zero or few examples, and specifically focus on verbalizing life-long experiences. For this, we derive a tree-like data structure from episodic memory (EM), with lower levels representing raw perception and proprioception data, and higher levels abstracting events to natural language concepts. Given such a hierarchical representation built from the experience stream, we apply a large language model as an agent to interactively search the EM given a user's query, dynamically expanding (initially collapsed) tree nodes to find the relevant information. The approach keeps computational costs low even when scaling to months of robot experience data. We evaluate our method on simulated household robot data, human egocentric videos, and real-world robot recordings, demonstrating its flexibility and scalability.
Learning to Summarize and Answer Questions about a Virtual Robot's Past Actions
Jun 16, 2023When robots perform long action sequences, users will want to easily and reliably find out what they have done. We therefore demonstrate the task of learning to summarize and answer questions about a robot agent's past actions using natural language alone. A single system with a large language model at its core is trained to both summarize and answer questions about action sequences given ego-centric video frames of a virtual robot and a question prompt. To enable training of question answering, we develop a method to automatically generate English-language questions and answers about objects, actions, and the temporal order in which actions occurred during episodes of robot action in the virtual environment. Training one model to both summarize and answer questions enables zero-shot transfer of representations of objects learned through question answering to improved action summarization. % involving objects not seen in training to summarize.
Multi-Task Learning for Joint Semantic Role and Proto-Role Labeling
Oct 13, 2022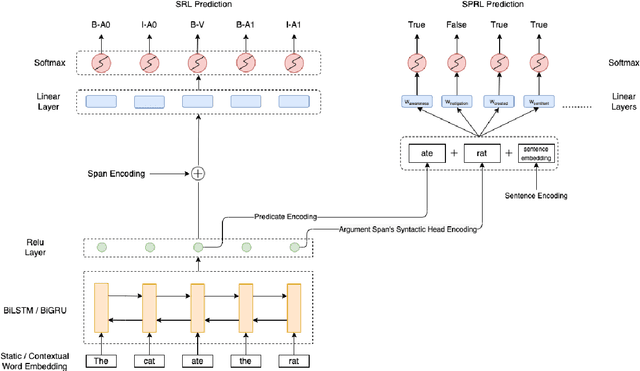
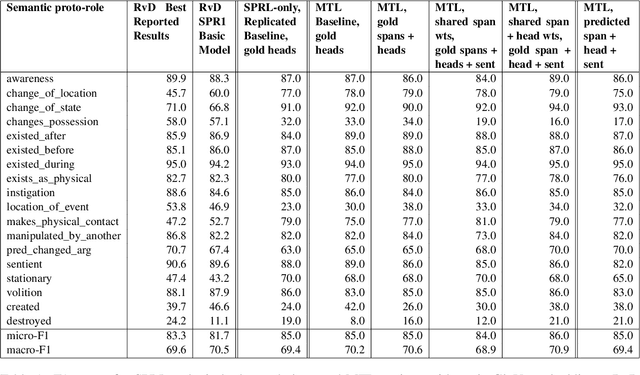
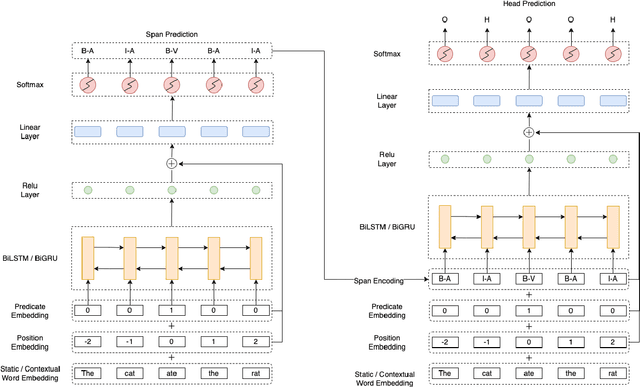
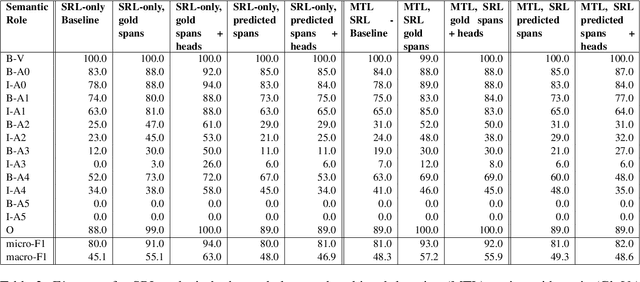
We put forward an end-to-end multi-step machine learning model which jointly labels semantic roles and the proto-roles of Dowty (1991), given a sentence and the predicates therein. Our best architecture first learns argument spans followed by learning the argument's syntactic heads. This information is shared with the next steps for predicting the semantic roles and proto-roles. We also experiment with transfer learning from argument and head prediction to role and proto-role labeling. We compare using static and contextual embeddings for words, arguments, and sentences. Unlike previous work, our model does not require pre-training or fine-tuning on additional tasks, beyond using off-the-shelf (static or contextual) embeddings and supervision. It also does not require argument spans, their semantic roles, and/or their gold syntactic heads as additional input, because it learns to predict all these during training. Our multi-task learning model raises the state-of-the-art predictions for most proto-roles.
Summarizing a virtual robot's past actions in natural language
Mar 13, 2022
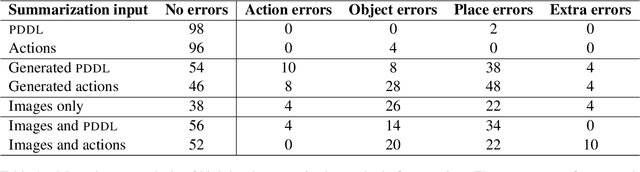
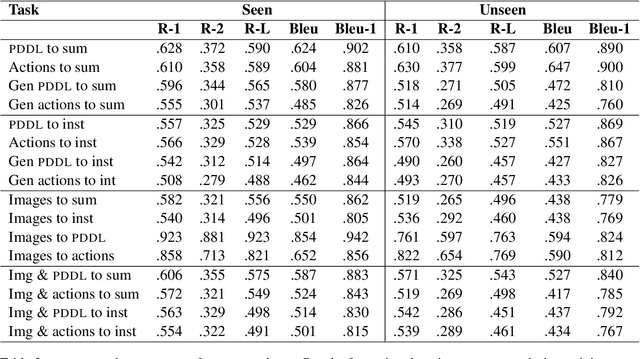
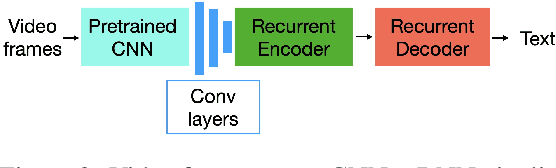
We propose and demonstrate the task of giving natural language summaries of the actions of a robotic agent in a virtual environment. We explain why such a task is important, what makes it difficult, and discuss how it might be addressed. To encourage others to work on this, we show how a popular existing dataset that matches robot actions with natural language descriptions designed for an instruction following task can be repurposed to serve as a training ground for robot action summarization work. We propose and test several methods of learning to generate such summaries, starting from either egocentric video frames of the robot taking actions or intermediate text representations of the actions used by an automatic planner. We provide quantitative and qualitative evaluations of our results, which can serve as a baseline for future work.
NLP in Human Rights Research -- Extracting Knowledge Graphs About Police and Army Units and Their Commanders
Jan 13, 2022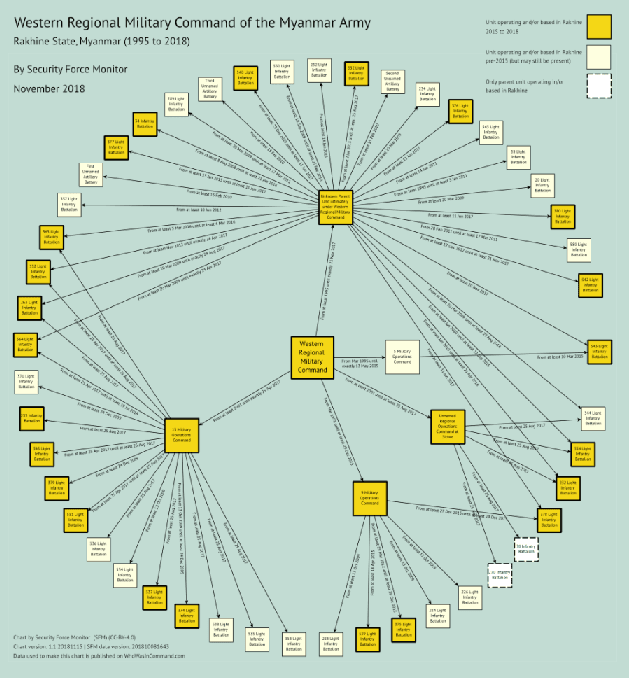
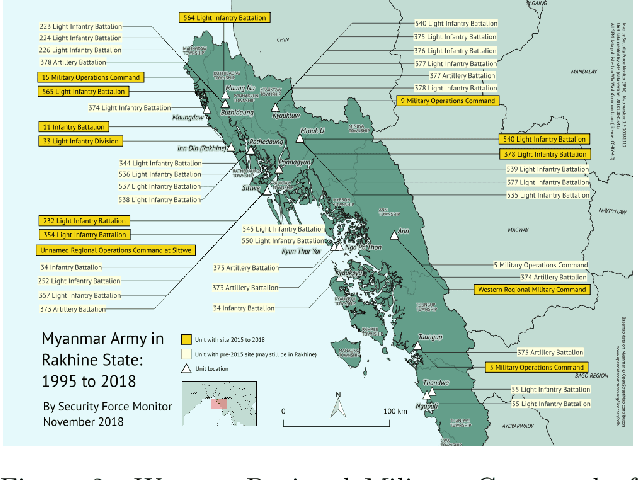

In this working paper we explore the use of an NLP system to assist the work of Security Force Monitor (SFM). SFM creates data about the organizational structure, command personnel and operations of police, army and other security forces, which assists human rights researchers, journalists and litigators in their work to help identify and bring to account specific units and personnel alleged to have committed abuses of human rights and international criminal law. This working paper presents an NLP system that extracts from English language news reports the names of security force units and the biographical details of their personnel, and infers the formal relationship between them. Published alongside this working paper are the system's code and training dataset. We find that the experimental NLP system performs the task at a fair to good level. Its performance is sufficient to justify further development into a live workflow that will give insight into whether its performance translates into savings in time and resource that would make it an effective technical intervention.
Deep Inverse Sensor Models as Priors for evidential Occupancy Mapping
Dec 02, 2020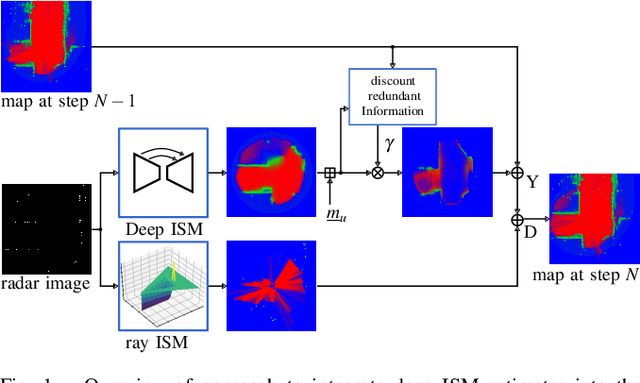
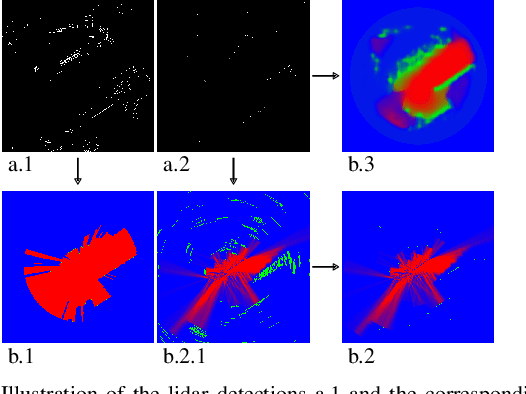
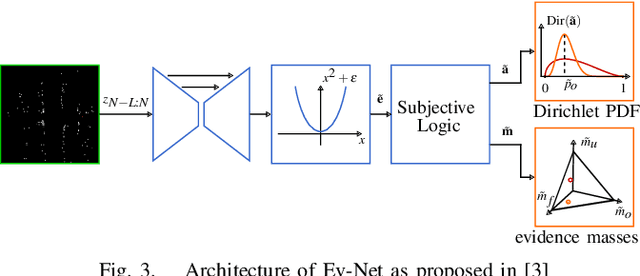

With the recent boost in autonomous driving, increased attention has been paid on radars as an input for occupancy mapping. Besides their many benefits, the inference of occupied space based on radar detections is notoriously difficult because of the data sparsity and the environment dependent noise (e.g. multipath reflections). Recently, deep learning-based inverse sensor models, from here on called deep ISMs, have been shown to improve over their geometric counterparts in retrieving occupancy information. Nevertheless, these methods perform a data-driven interpolation which has to be verified later on in the presence of measurements. In this work, we describe a novel approach to integrate deep ISMs together with geometric ISMs into the evidential occupancy mapping framework. Our method leverages both the capabilities of the data-driven approach to initialize cells not yet observable for the geometric model effectively enhancing the perception field and convergence speed, while at the same time use the precision of the geometric ISM to converge to sharp boundaries. We further define a lower limit on the deep ISM estimate's certainty together with analytical proofs of convergence which we use to distinguish cells that are solely allocated by the deep ISM from cells already verified using the geometric approach.
Deep, spatially coherent Occupancy Maps based on Radar Measurements
Mar 29, 2019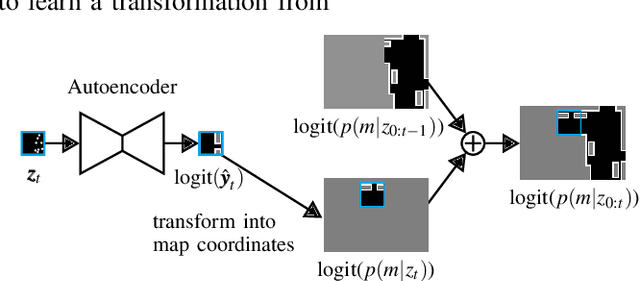

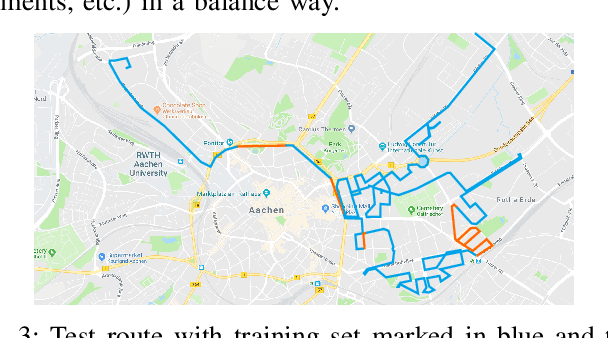
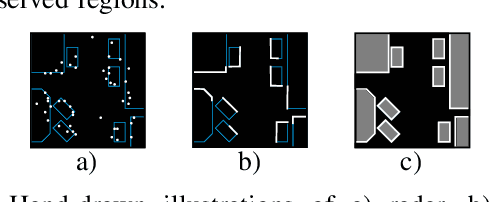
One essential step to realize modern driver assistance technology is the accurate knowledge about the location of static objects in the environment. In this work, we use artificial neural networks to predict the occupation state of a whole scene in an end-to-end manner. This stands in contrast to the traditional approach of accumulating each detection's influence on the occupancy state and allows to learn spatial priors which can be used to interpolate the environment's occupancy state. We show that these priors make our method suitable to predict dense occupancy estimations from sparse, highly uncertain inputs, as given by automotive radars, even for complex urban scenarios. Furthermore, we demonstrate that these estimations can be used for large-scale mapping applications.