 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniGuide: Universal Guidance Fields for Enhancing Generalist Robot Policies
Mar 09, 2026Vision-language-action(VLA) models have shown great promise as generalist policies for a large range of relatively simple tasks. However, they demonstrate limited performance on more complex tasks, such as those requiring complex spatial or semantic understanding, manipulation in clutter, or precise manipulation. We propose OMNIGUIDE, a flexible framework that improves VLA performance on such tasks by leveraging arbitrary sources of guidance, such as 3D foundation models, semantic-reasoning VLMs, and human pose models. We show how many kinds of guidance can be naturally expressed as differentiable energy functions with task-specific attractors and repellers located in 3D space, that influence the sampling of VLA actions. In this way, OMNIGUIDE enables guidance sources with complementary task-relevant strengths to improve a VLA model's performance on challenging tasks. Extensive experiments in both simulation and real-world environments, across diverse sources of guidance, demonstrate that OMNIGUIDE enhances the performance of state-of-the-art generalist policies (e.g., $π_{0.5}$, GR00T N1.6) significantly across success and safety rates. Critically, our unified framework matches or surpasses the performance of prior methods designed to incorporate specific sources of guidance into VLA policies. Project Page: $\href{https://omniguide.github.io/}{this \; url}$
ZeroMimic: Distilling Robotic Manipulation Skills from Web Videos
Mar 31, 2025



Many recent advances in robotic manipulation have come through imitation learning, yet these rely largely on mimicking a particularly hard-to-acquire form of demonstrations: those collected on the same robot in the same room with the same objects as the trained policy must handle at test time. In contrast, large pre-recorded human video datasets demonstrating manipulation skills in-the-wild already exist, which contain valuable information for robots. Is it possible to distill a repository of useful robotic skill policies out of such data without any additional requirements on robot-specific demonstrations or exploration? We present the first such system ZeroMimic, that generates immediately deployable image goal-conditioned skill policies for several common categories of manipulation tasks (opening, closing, pouring, pick&place, cutting, and stirring) each capable of acting upon diverse objects and across diverse unseen task setups. ZeroMimic is carefully designed to exploit recent advances in semantic and geometric visual understanding of human videos, together with modern grasp affordance detectors and imitation policy classes. After training ZeroMimic on the popular EpicKitchens dataset of ego-centric human videos, we evaluate its out-of-the-box performance in varied real-world and simulated kitchen settings with two different robot embodiments, demonstrating its impressive abilities to handle these varied tasks. To enable plug-and-play reuse of ZeroMimic policies on other task setups and robots, we release software and policy checkpoints of our skill policies.
Don't Yell at Your Robot: Physical Correction as the Collaborative Interface for Language Model Powered Robots
Dec 17, 2024



We present a novel approach for enhancing human-robot collaboration using physical interactions for real-time error correction of large language model (LLM) powered robots. Unlike other methods that rely on verbal or text commands, the robot leverages an LLM to proactively executes 6 DoF linear Dynamical System (DS) commands using a description of the scene in natural language. During motion, a human can provide physical corrections, used to re-estimate the desired intention, also parameterized by linear DS. This corrected DS can be converted to natural language and used as part of the prompt to improve future LLM interactions. We provide proof-of-concept result in a hybrid real+sim experiment, showcasing physical interaction as a new possibility for LLM powered human-robot interface.
Composing Pre-Trained Object-Centric Representations for Robotics From "What" and "Where" Foundation Models
Apr 20, 2024



There have recently been large advances both in pre-training visual representations for robotic control and segmenting unknown category objects in general images. To leverage these for improved robot learning, we propose $\textbf{POCR}$, a new framework for building pre-trained object-centric representations for robotic control. Building on theories of "what-where" representations in psychology and computer vision, we use segmentations from a pre-trained model to stably locate across timesteps, various entities in the scene, capturing "where" information. To each such segmented entity, we apply other pre-trained models that build vector descriptions suitable for robotic control tasks, thus capturing "what" the entity is. Thus, our pre-trained object-centric representations for control are constructed by appropriately combining the outputs of off-the-shelf pre-trained models, with no new training. On various simulated and real robotic tasks, we show that imitation policies for robotic manipulators trained on POCR achieve better performance and systematic generalization than state of the art pre-trained representations for robotics, as well as prior object-centric representations that are typically trained from scratch.
Maximizing BCI Human Feedback using Active Learning
Aug 11, 2020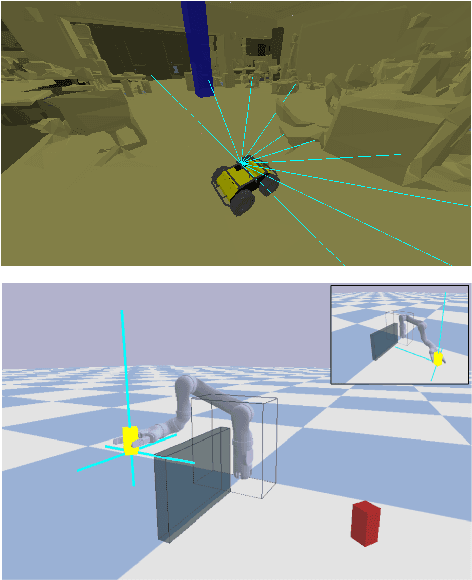
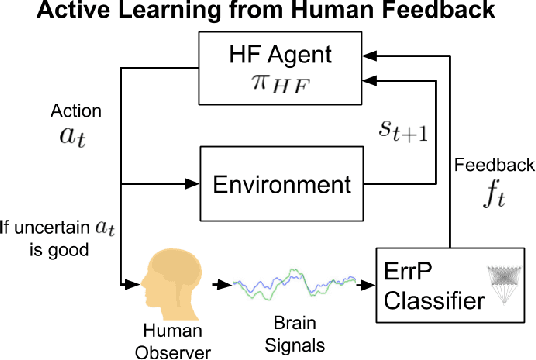
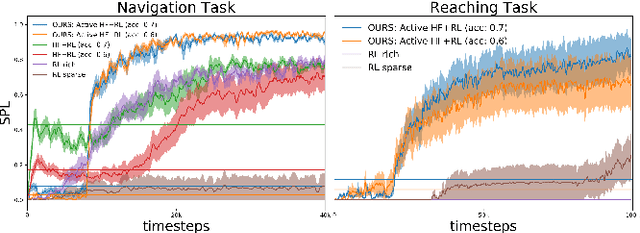
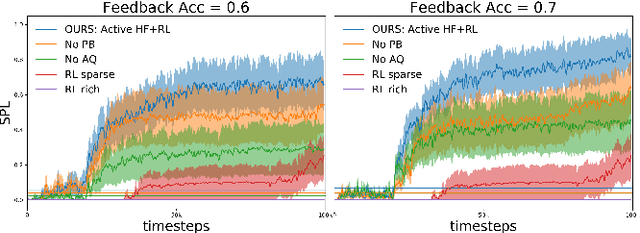
Recent advancements in \textit{Learning from Human Feedback} present an effective way to train robot agents via inputs from non-expert humans, without a need for a specially designed reward function. However, this approach needs a human to be present and attentive during robot learning to provide evaluative feedback. In addition, the amount of feedback needed grows with the level of task difficulty and the quality of human feedback might decrease over time because of fatigue. To overcome these limitations and enable learning more robot tasks with higher complexities, there is a need to maximize the quality of expensive feedback received and reduce the amount of human cognitive involvement required. In this work, we present an approach that uses active learning to smartly choose queries for the human supervisor based on the uncertainty of the robot and effectively reduces the amount of feedback needed to learn a given task. We also use a novel multiple buffer system to improve robustness to feedback noise and guard against catastrophic forgetting as the robot learning evolves. This makes it possible to learn tasks with more complexity using lesser amounts of human feedback compared to previous methods. We demonstrate the utility of our proposed method on a robot arm reaching task where the robot learns to reach a location in 3D without colliding with obstacles. Our approach is able to learn this task faster, with less human feedback and cognitive involvement, compared to previous methods that do not use active learning.
Accelerated Robot Learning via Human Brain Signals
Oct 01, 2019
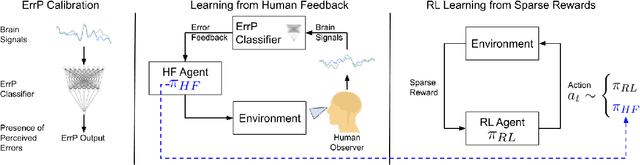
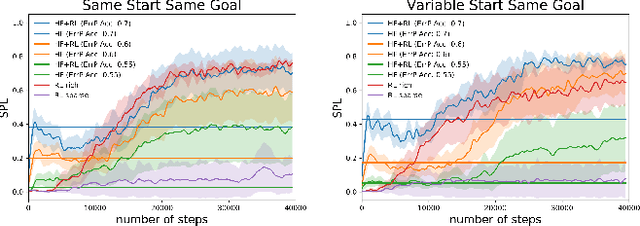

In reinforcement learning (RL), sparse rewards are a natural way to specify the task to be learned. However, most RL algorithms struggle to learn in this setting since the learning signal is mostly zeros. In contrast, humans are good at assessing and predicting the future consequences of actions and can serve as good reward/policy shapers to accelerate the robot learning process. Previous works have shown that the human brain generates an error-related signal, measurable using electroencephelography (EEG), when the human perceives the task being done erroneously. In this work, we propose a method that uses evaluative feedback obtained from human brain signals measured via scalp EEG to accelerate RL for robotic agents in sparse reward settings. As the robot learns the task, the EEG of a human observer watching the robot attempts is recorded and decoded into noisy error feedback signal. From this feedback, we use supervised learning to obtain a policy that subsequently augments the behavior policy and guides exploration in the early stages of RL. This bootstraps the RL learning process to enable learning from sparse reward. Using a robotic navigation task as a test bed, we show that our method achieves a stable obstacle-avoidance policy with high success rate, outperforming learning from sparse rewards only that struggles to achieve obstacle avoidance behavior or fails to advance to the goal.