 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems
May 19, 2022
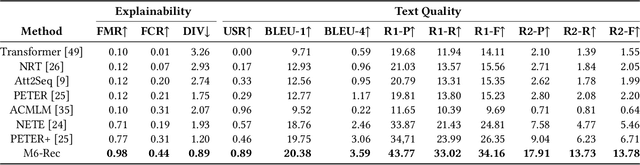
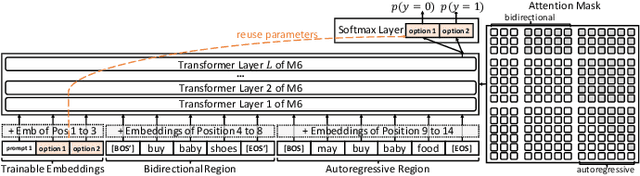

Industrial recommender systems have been growing increasingly complex, may involve \emph{diverse domains} such as e-commerce products and user-generated contents, and can comprise \emph{a myriad of tasks} such as retrieval, ranking, explanation generation, and even AI-assisted content production. The mainstream approach so far is to develop individual algorithms for each domain and each task. In this paper, we explore the possibility of developing a unified foundation model to support \emph{open-ended domains and tasks} in an industrial recommender system, which may reduce the demand on downstream settings' data and can minimize the carbon footprint by avoiding training a separate model from scratch for every task. Deriving a unified foundation is challenging due to (i) the potentially unlimited set of downstream domains and tasks, and (ii) the real-world systems' emphasis on computational efficiency. We thus build our foundation upon M6, an existing large-scale industrial pretrained language model similar to GPT-3 and T5, and leverage M6's pretrained ability for sample-efficient downstream adaptation, by representing user behavior data as plain texts and converting the tasks to either language understanding or generation. To deal with a tight hardware budget, we propose an improved version of prompt tuning that outperforms fine-tuning with negligible 1\% task-specific parameters, and employ techniques such as late interaction, early exiting, parameter sharing, and pruning to further reduce the inference time and the model size. We demonstrate the foundation model's versatility on a wide range of tasks such as retrieval, ranking, zero-shot recommendation, explanation generation, personalized content creation, and conversational recommendation, and manage to deploy it on both cloud servers and mobile devices.
In-N-Out Generative Learning for Dense Unsupervised Video Segmentation
Apr 11, 2022
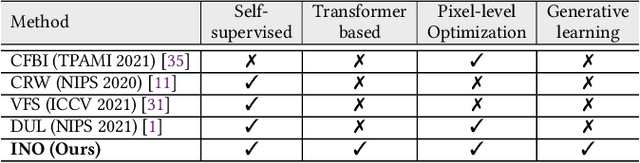
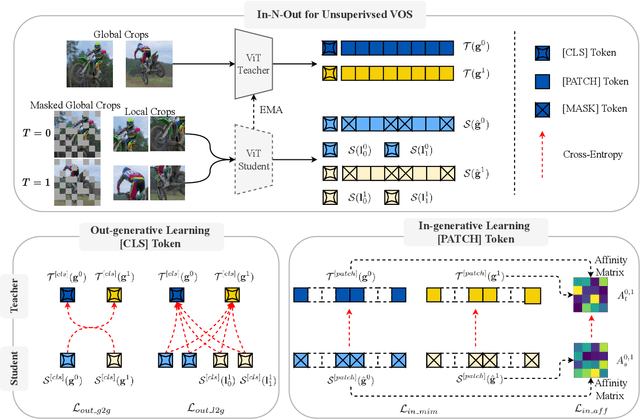
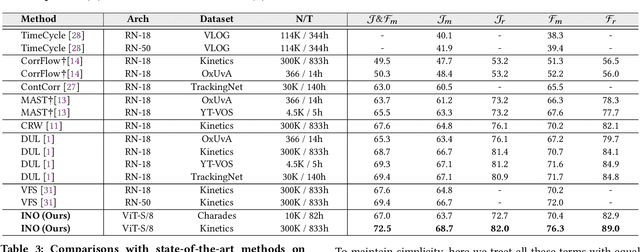
In this paper, we focus on the unsupervised learning for Video Object Segmentation (VOS) which learns visual correspondence (i.e., similarity between pixel-level features) from unlabeled videos. Previous methods are mainly based on the contrastive learning paradigm, which optimize either in image level or pixel level. Image-level optimization (e.g., the spatially pooled feature of ResNet) learns robust high-level semantics but is sub-optimal since the pixel-level features are optimized implicitly. By contrast, pixel-level optimization is more explicit, however, it is sensitive to the visual quality of training data and is not robust to object deformation. To complementarily perform these two levels of optimization in a unified framework, we propose the In-aNd-Out (INO) generative learning from a purely generative perspective with the help of naturally designed class tokens and patch tokens in Vision Transformer (ViT). Specifically, for image-level optimization, we force the out-view imagination from local to global views on class tokens, which helps capturing high-level semantics, and we name it as out-generative learning. As to pixel-level optimization, we perform in-view masked image modeling on patch tokens, which recovers the corrupted parts of an image via inferring its fine-grained structure, and we term it as in-generative learning. To better discover the temporal information, we additionally force the inter-frame consistency from both feature level and affinity matrix level. Extensive experiments on DAVIS-2017 val and YouTube-VOS 2018 val show that our INO outperforms previous state-of-the-art methods by significant margins.
Modality Competition: What Makes Joint Training of Multi-modal Network Fail in Deep Learning? (Provably)
Mar 23, 2022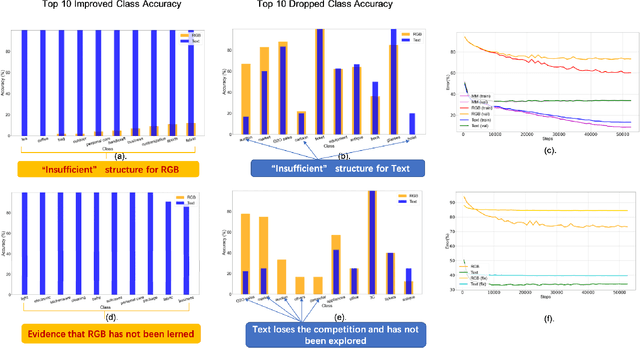
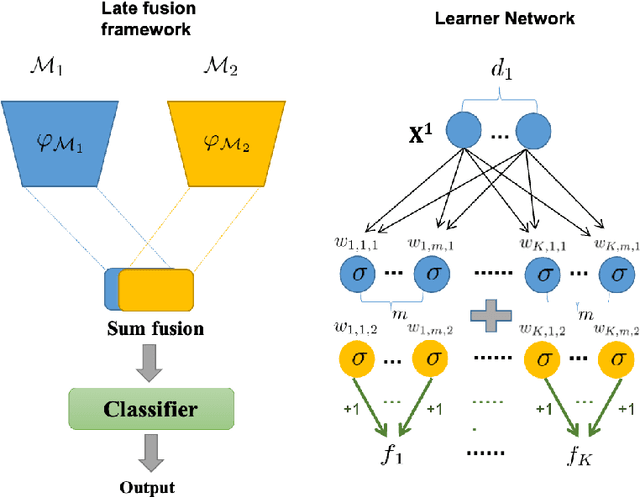
Despite the remarkable success of deep multi-modal learning in practice, it has not been well-explained in theory. Recently, it has been observed that the best uni-modal network outperforms the jointly trained multi-modal network, which is counter-intuitive since multiple signals generally bring more information. This work provides a theoretical explanation for the emergence of such performance gap in neural networks for the prevalent joint training framework. Based on a simplified data distribution that captures the realistic property of multi-modal data, we prove that for the multi-modal late-fusion network with (smoothed) ReLU activation trained jointly by gradient descent, different modalities will compete with each other. The encoder networks will learn only a subset of modalities. We refer to this phenomenon as modality competition. The losing modalities, which fail to be discovered, are the origins where the sub-optimality of joint training comes from. Experimentally, we illustrate that modality competition matches the intrinsic behavior of late-fusion joint training.
Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Feb 07, 2022
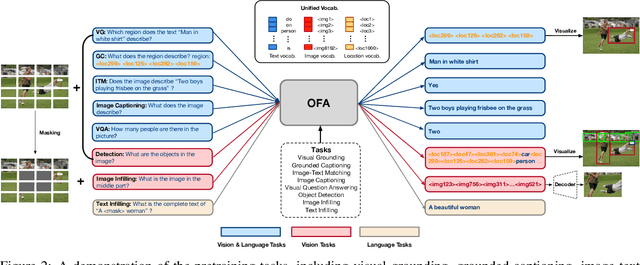
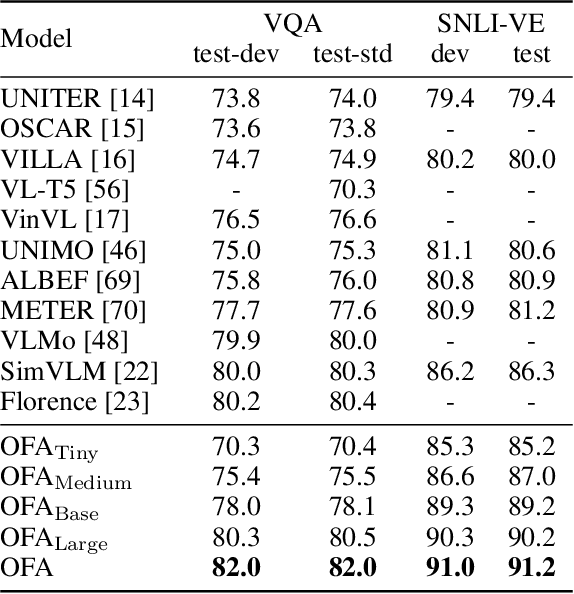
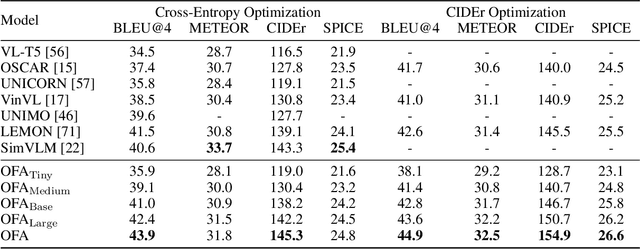
In this work, we pursue a unified paradigm for multimodal pretraining to break the scaffolds of complex task/modality-specific customization. We propose OFA, a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image generation, visual grounding, image captioning, image classification, text generation, etc.) to a simple sequence-to-sequence learning framework based on the encoder-decoder architecture. OFA performs pretraining and finetuning with task instructions and introduces no extra task-specific layers for finetuning. Experimental results show that OFA achieves new state-of-the-arts on a series of multimodal tasks, including image captioning (COCO test CIDEr: 149.6), text-to-image generation (COCO test FID: 10.5), VQA (test-std acc.: 80.02), SNLI-VE (test acc.: 90.20), and referring expression comprehension (RefCOCO / RefCOCO+ / RefCOCOg test acc.: 92.93 / 90.10 / 85.20). Through extensive analyses, we demonstrate that OFA reaches comparable performance with uni-modal pretrained models (e.g., BERT, MAE, MoCo v3, SimCLR v2, etc.) in uni-modal tasks, including NLU, NLG, and image classification, and it effectively transfers to unseen tasks and domains. Code shall be released soon at http://github.com/OFA-Sys/OFA
Deep Unified Representation for Heterogeneous Recommendation
Jan 26, 2022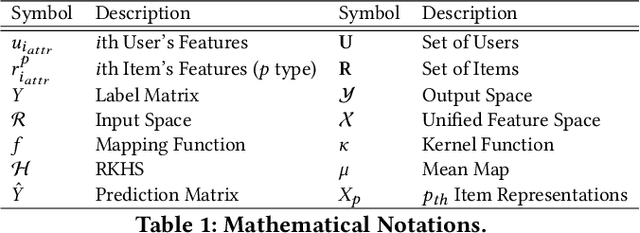
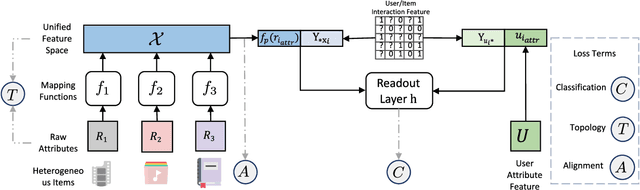
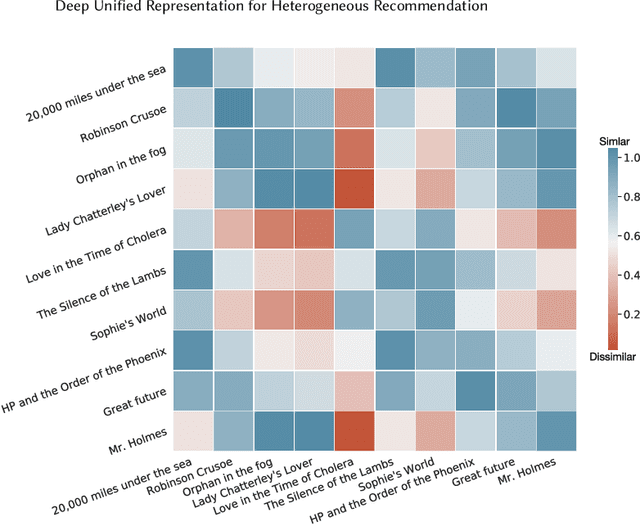
Recommendation system has been a widely studied task both in academia and industry. Previous works mainly focus on homogeneous recommendation and little progress has been made for heterogeneous recommender systems. However, heterogeneous recommendations, e.g., recommending different types of items including products, videos, celebrity shopping notes, among many others, are dominant nowadays. State-of-the-art methods are incapable of leveraging attributes from different types of items and thus suffer from data sparsity problems. And it is indeed quite challenging to represent items with different feature spaces jointly. To tackle this problem, we propose a kernel-based neural network, namely deep unified representation (or DURation) for heterogeneous recommendation, to jointly model unified representations of heterogeneous items while preserving their original feature space topology structures. Theoretically, we prove the representation ability of the proposed model. Besides, we conduct extensive experiments on real-world datasets. Experimental results demonstrate that with the unified representation, our model achieves remarkable improvement (e.g., 4.1% ~ 34.9% lift by AUC score and 3.7% lift by online CTR) over existing state-of-the-art models.
Cross-domain User Preference Learning for Cold-start Recommendation
Dec 07, 2021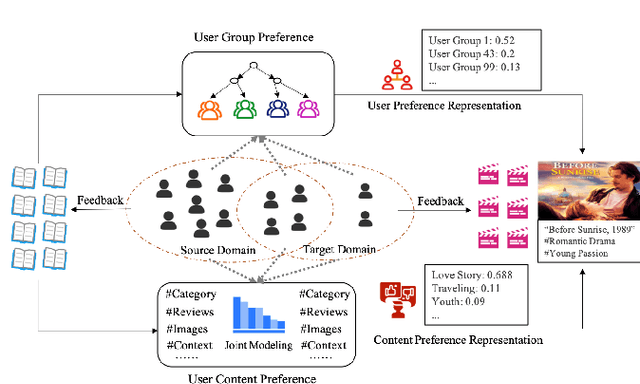
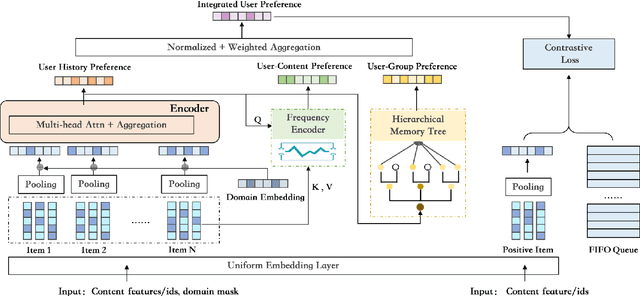
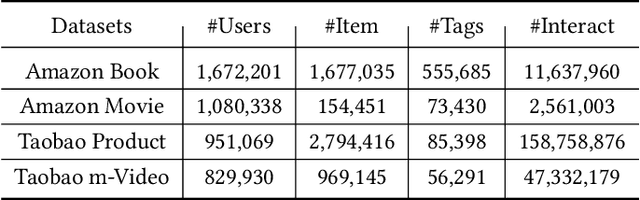
Cross-domain cold-start recommendation is an increasingly emerging issue for recommender systems. Existing works mainly focus on solving either cross-domain user recommendation or cold-start content recommendation. However, when a new domain evolves at its early stage, it has potential users similar to the source domain but with much fewer interactions. It is critical to learn a user's preference from the source domain and transfer it into the target domain, especially on the newly arriving contents with limited user feedback. To bridge this gap, we propose a self-trained Cross-dOmain User Preference LEarning (COUPLE) framework, targeting cold-start recommendation with various semantic tags, such as attributes of items or genres of videos. More specifically, we consider three levels of preferences, including user history, user content and user group to provide reliable recommendation. With user history represented by a domain-aware sequential model, a frequency encoder is applied to the underlying tags for user content preference learning. Then, a hierarchical memory tree with orthogonal node representation is proposed to further generalize user group preference across domains. The whole framework updates in a contrastive way with a First-In-First-Out (FIFO) queue to obtain more distinctive representations. Extensive experiments on two datasets demonstrate the efficiency of COUPLE in both user and content cold-start situations. By deploying an online A/B test for a week, we show that the Click-Through-Rate (CTR) of COUPLE is superior to other baselines used on Taobao APP. Now the method is serving online for the cross-domain cold micro-video recommendation.
KNAS: Green Neural Architecture Search
Nov 26, 2021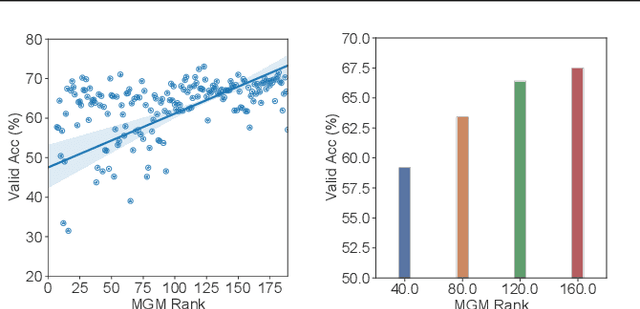
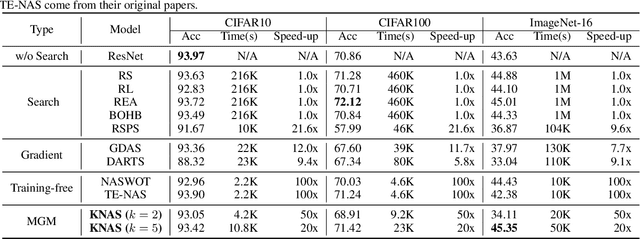

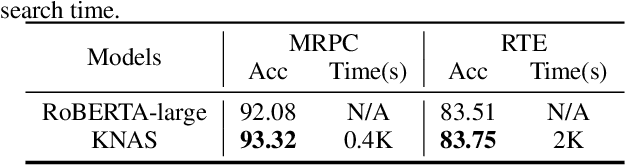
Many existing neural architecture search (NAS) solutions rely on downstream training for architecture evaluation, which takes enormous computations. Considering that these computations bring a large carbon footprint, this paper aims to explore a green (namely environmental-friendly) NAS solution that evaluates architectures without training. Intuitively, gradients, induced by the architecture itself, directly decide the convergence and generalization results. It motivates us to propose the gradient kernel hypothesis: Gradients can be used as a coarse-grained proxy of downstream training to evaluate random-initialized networks. To support the hypothesis, we conduct a theoretical analysis and find a practical gradient kernel that has good correlations with training loss and validation performance. According to this hypothesis, we propose a new kernel based architecture search approach KNAS. Experiments show that KNAS achieves competitive results with orders of magnitude faster than "train-then-test" paradigms on image classification tasks. Furthermore, the extremely low search cost enables its wide applications. The searched network also outperforms strong baseline RoBERTA-large on two text classification tasks. Codes are available at \url{https://github.com/Jingjing-NLP/KNAS} .
Edge-Cloud Polarization and Collaboration: A Comprehensive Survey
Nov 12, 2021
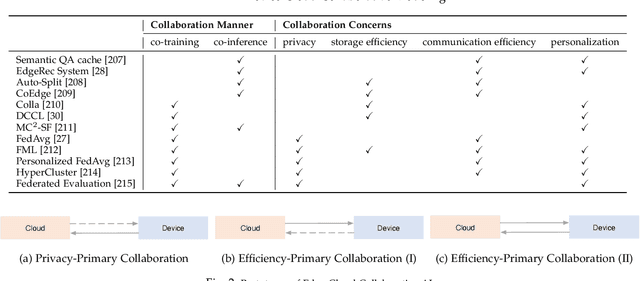
Influenced by the great success of deep learning via cloud computing and the rapid development of edge chips, research in artificial intelligence (AI) has shifted to both of the computing paradigms, i.e., cloud computing and edge computing. In recent years, we have witnessed significant progress in developing more advanced AI models on cloud servers that surpass traditional deep learning models owing to model innovations (e.g., Transformers, Pretrained families), explosion of training data and soaring computing capabilities. However, edge computing, especially edge and cloud collaborative computing, are still in its infancy to announce their success due to the resource-constrained IoT scenarios with very limited algorithms deployed. In this survey, we conduct a systematic review for both cloud and edge AI. Specifically, we are the first to set up the collaborative learning mechanism for cloud and edge modeling with a thorough review of the architectures that enable such mechanism. We also discuss potentials and practical experiences of some on-going advanced edge AI topics including pretraining models, graph neural networks and reinforcement learning. Finally, we discuss the promising directions and challenges in this field.
M6-10T: A Sharing-Delinking Paradigm for Efficient Multi-Trillion Parameter Pretraining
Oct 25, 2021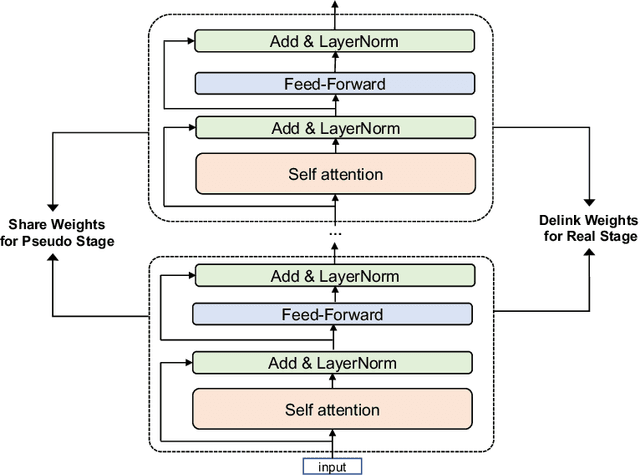

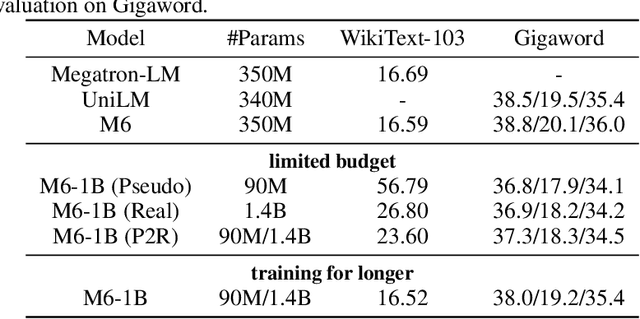
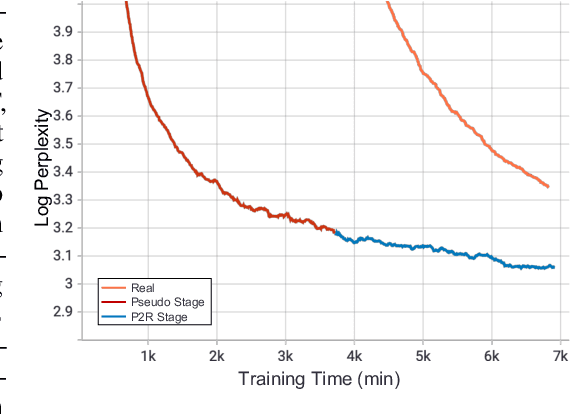
Recent expeditious developments in deep learning algorithms, distributed training, and even hardware design for large models have enabled training extreme-scale models, say GPT-3 and Switch Transformer possessing hundreds of billions or even trillions of parameters. However, under limited resources, extreme-scale model training that requires enormous amounts of computes and memory footprint suffers from frustratingly low efficiency in model convergence. In this paper, we propose a simple training strategy called "Pseudo-to-Real" for high-memory-footprint-required large models. Pseudo-to-Real is compatible with large models with architecture of sequential layers. We demonstrate a practice of pretraining unprecedented 10-trillion-parameter model, an order of magnitude larger than the state-of-the-art, on solely 512 GPUs within 10 days. Besides demonstrating the application of Pseudo-to-Real, we also provide a technique, Granular CPU offloading, to manage CPU memory for training large model and maintain high GPU utilities. Fast training of extreme-scale models on a decent amount of resources can bring much smaller carbon footprint and contribute to greener AI.
Stable Prediction on Graphs with Agnostic Distribution Shift
Oct 08, 2021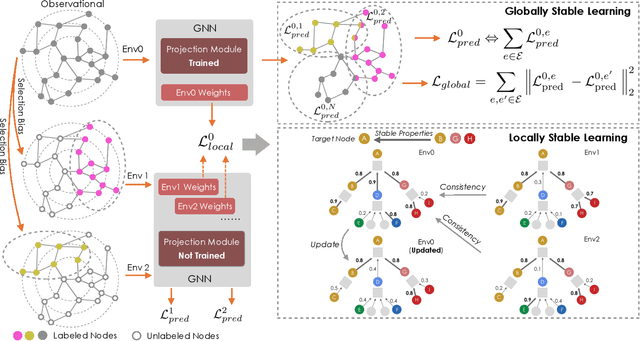
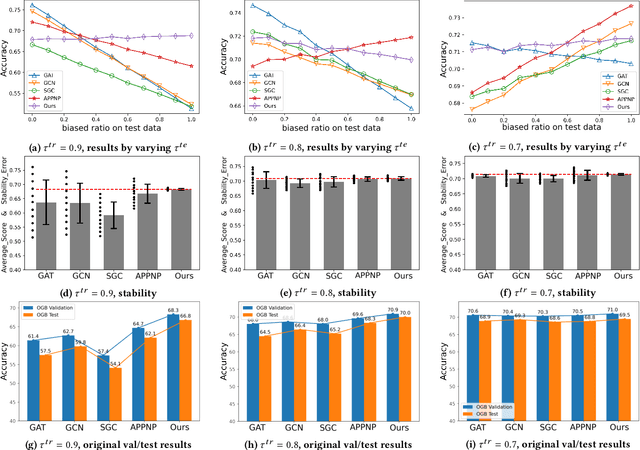
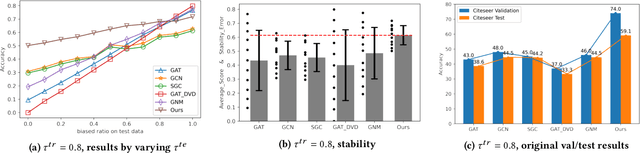
Graph is a flexible and effective tool to represent complex structures in practice and graph neural networks (GNNs) have been shown to be effective on various graph tasks with randomly separated training and testing data. In real applications, however, the distribution of training graph might be different from that of the test one (e.g., users' interactions on the user-item training graph and their actual preference on items, i.e., testing environment, are known to have inconsistencies in recommender systems). Moreover, the distribution of test data is always agnostic when GNNs are trained. Hence, we are facing the agnostic distribution shift between training and testing on graph learning, which would lead to unstable inference of traditional GNNs across different test environments. To address this problem, we propose a novel stable prediction framework for GNNs, which permits both locally and globally stable learning and prediction on graphs. In particular, since each node is partially represented by its neighbors in GNNs, we propose to capture the stable properties for each node (locally stable) by re-weighting the information propagation/aggregation processes. For global stability, we propose a stable regularizer that reduces the training losses on heterogeneous environments and thus warping the GNNs to generalize well. We conduct extensive experiments on several graph benchmarks and a noisy industrial recommendation dataset that is collected from 5 consecutive days during a product promotion festival. The results demonstrate that our method outperforms various SOTA GNNs for stable prediction on graphs with agnostic distribution shift, including shift caused by node labels and attributes.