 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Guided Key-Token Regularization for Multimodal Large Language Model Unlearning
Jan 29, 2026Unlearning in Multimodal Large Language Models (MLLMs) prevents the model from revealing private information when queried about target images. Existing MLLM unlearning methods largely adopt approaches developed for LLMs. They treat all answer tokens uniformly, disregarding their varying importance in the unlearning process. Moreover, these methods focus exclusively on the language modality, disregarding visual cues that indicate key tokens in answers. In this paper, after formulating the problem of unlearning in multimodal question answering for MLLMs, we propose Visual-Guided Key-Token Regularization (ViKeR). We leverage irrelevant visual inputs to predict ideal post-unlearning token-level distributions and use these distributions to regularize the unlearning process, thereby prioritizing key tokens. Further, we define key tokens in unlearning via information entropy and discuss ViKeR's effectiveness through token-level gradient reweighting, which amplifies updates on key tokens. Experiments on MLLMU and CLEAR benchmarks demonstrate that our method effectively performs unlearning while mitigating forgetting and maintaining response coherence.
Bridging Sign and Spoken Languages: Pseudo Gloss Generation for Sign Language Translation
May 21, 2025Sign Language Translation (SLT) aims to map sign language videos to spoken language text. A common approach relies on gloss annotations as an intermediate representation, decomposing SLT into two sub-tasks: video-to-gloss recognition and gloss-to-text translation. While effective, this paradigm depends on expert-annotated gloss labels, which are costly and rarely available in existing datasets, limiting its scalability. To address this challenge, we propose a gloss-free pseudo gloss generation framework that eliminates the need for human-annotated glosses while preserving the structured intermediate representation. Specifically, we prompt a Large Language Model (LLM) with a few example text-gloss pairs using in-context learning to produce draft sign glosses from spoken language text. To enhance the correspondence between LLM-generated pseudo glosses and the sign sequences in video, we correct the ordering in the pseudo glosses for better alignment via a weakly supervised learning process. This reordering facilitates the incorporation of auxiliary alignment objectives, and allows for the use of efficient supervision via a Connectionist Temporal Classification (CTC) loss. We train our SLT mode, which consists of a vision encoder and a translator, through a three-stage pipeline, which progressively narrows the modality gap between sign language and spoken language. Despite its simplicity, our approach outperforms previous state-of-the-art gloss-free frameworks on two SLT benchmarks and achieves competitive results compared to gloss-based methods.
Dynamic Derivation and Elimination: Audio Visual Segmentation with Enhanced Audio Semantics
Mar 17, 2025Sound-guided object segmentation has drawn considerable attention for its potential to enhance multimodal perception. Previous methods primarily focus on developing advanced architectures to facilitate effective audio-visual interactions, without fully addressing the inherent challenges posed by audio natures, \emph{\ie}, (1) feature confusion due to the overlapping nature of audio signals, and (2) audio-visual matching difficulty from the varied sounds produced by the same object. To address these challenges, we propose Dynamic Derivation and Elimination (DDESeg): a novel audio-visual segmentation framework. Specifically, to mitigate feature confusion, DDESeg reconstructs the semantic content of the mixed audio signal by enriching the distinct semantic information of each individual source, deriving representations that preserve the unique characteristics of each sound. To reduce the matching difficulty, we introduce a discriminative feature learning module, which enhances the semantic distinctiveness of generated audio representations. Considering that not all derived audio representations directly correspond to visual features (e.g., off-screen sounds), we propose a dynamic elimination module to filter out non-matching elements. This module facilitates targeted interaction between sounding regions and relevant audio semantics. By scoring the interacted features, we identify and filter out irrelevant audio information, ensuring accurate audio-visual alignment. Comprehensive experiments demonstrate that our framework achieves superior performance in AVS datasets.
Robust Audio-Visual Segmentation via Audio-Guided Visual Convergent Alignment
Mar 17, 2025Accurately localizing audible objects based on audio-visual cues is the core objective of audio-visual segmentation. Most previous methods emphasize spatial or temporal multi-modal modeling, yet overlook challenges from ambiguous audio-visual correspondences such as nearby visually similar but acoustically different objects and frequent shifts in objects' sounding status. Consequently, they may struggle to reliably correlate audio and visual cues, leading to over- or under-segmentation. To address these limitations, we propose a novel framework with two primary components: an audio-guided modality alignment (AMA) module and an uncertainty estimation (UE) module. Instead of indiscriminately correlating audio-visual cues through a global attention mechanism, AMA performs audio-visual interactions within multiple groups and consolidates group features into compact representations based on their responsiveness to audio cues, effectively directing the model's attention to audio-relevant areas. Leveraging contrastive learning, AMA further distinguishes sounding regions from silent areas by treating features with strong audio responses as positive samples and weaker responses as negatives. Additionally, UE integrates spatial and temporal information to identify high-uncertainty regions caused by frequent changes in sound state, reducing prediction errors by lowering confidence in these areas. Experimental results demonstrate that our approach achieves superior accuracy compared to existing state-of-the-art methods, particularly in challenging scenarios where traditional approaches struggle to maintain reliable segmentation.
JEN-1 DreamStyler: Customized Musical Concept Learning via Pivotal Parameters Tuning
Jun 18, 2024Large models for text-to-music generation have achieved significant progress, facilitating the creation of high-quality and varied musical compositions from provided text prompts. However, input text prompts may not precisely capture user requirements, particularly when the objective is to generate music that embodies a specific concept derived from a designated reference collection. In this paper, we propose a novel method for customized text-to-music generation, which can capture the concept from a two-minute reference music and generate a new piece of music conforming to the concept. We achieve this by fine-tuning a pretrained text-to-music model using the reference music. However, directly fine-tuning all parameters leads to overfitting issues. To address this problem, we propose a Pivotal Parameters Tuning method that enables the model to assimilate the new concept while preserving its original generative capabilities. Additionally, we identify a potential concept conflict when introducing multiple concepts into the pretrained model. We present a concept enhancement strategy to distinguish multiple concepts, enabling the fine-tuned model to generate music incorporating either individual or multiple concepts simultaneously. Since we are the first to work on the customized music generation task, we also introduce a new dataset and evaluation protocol for the new task. Our proposed Jen1-DreamStyler outperforms several baselines in both qualitative and quantitative evaluations. Demos will be available at https://www.jenmusic.ai/research#DreamStyler.
JEN-1 Composer: A Unified Framework for High-Fidelity Multi-Track Music Generation
Nov 03, 2023



With rapid advances in generative artificial intelligence, the text-to-music synthesis task has emerged as a promising direction for music generation from scratch. However, finer-grained control over multi-track generation remains an open challenge. Existing models exhibit strong raw generation capability but lack the flexibility to compose separate tracks and combine them in a controllable manner, differing from typical workflows of human composers. To address this issue, we propose JEN-1 Composer, a unified framework to efficiently model marginal, conditional, and joint distributions over multi-track music via a single model. JEN-1 Composer framework exhibits the capacity to seamlessly incorporate any diffusion-based music generation system, \textit{e.g.} Jen-1, enhancing its capacity for versatile multi-track music generation. We introduce a curriculum training strategy aimed at incrementally instructing the model in the transition from single-track generation to the flexible generation of multi-track combinations. During the inference, users have the ability to iteratively produce and choose music tracks that meet their preferences, subsequently creating an entire musical composition incrementally following the proposed Human-AI co-composition workflow. Quantitative and qualitative assessments demonstrate state-of-the-art performance in controllable and high-fidelity multi-track music synthesis. The proposed JEN-1 Composer represents a significant advance toward interactive AI-facilitated music creation and composition. Demos will be available at https://www.jenmusic.ai/audio-demos.
BAVS: Bootstrapping Audio-Visual Segmentation by Integrating Foundation Knowledge
Aug 20, 2023



Given an audio-visual pair, audio-visual segmentation (AVS) aims to locate sounding sources by predicting pixel-wise maps. Previous methods assume that each sound component in an audio signal always has a visual counterpart in the image. However, this assumption overlooks that off-screen sounds and background noise often contaminate the audio recordings in real-world scenarios. They impose significant challenges on building a consistent semantic mapping between audio and visual signals for AVS models and thus impede precise sound localization. In this work, we propose a two-stage bootstrapping audio-visual segmentation framework by incorporating multi-modal foundation knowledge. In a nutshell, our BAVS is designed to eliminate the interference of background noise or off-screen sounds in segmentation by establishing the audio-visual correspondences in an explicit manner. In the first stage, we employ a segmentation model to localize potential sounding objects from visual data without being affected by contaminated audio signals. Meanwhile, we also utilize a foundation audio classification model to discern audio semantics. Considering the audio tags provided by the audio foundation model are noisy, associating object masks with audio tags is not trivial. Thus, in the second stage, we develop an audio-visual semantic integration strategy (AVIS) to localize the authentic-sounding objects. Here, we construct an audio-visual tree based on the hierarchical correspondence between sounds and object categories. We then examine the label concurrency between the localized objects and classified audio tags by tracing the audio-visual tree. With AVIS, we can effectively segment real-sounding objects. Extensive experiments demonstrate the superiority of our method on AVS datasets, particularly in scenarios involving background noise. Our project website is https://yenanliu.github.io/AVSS.github.io/.
JEN-1: Text-Guided Universal Music Generation with Omnidirectional Diffusion Models
Aug 09, 2023



Music generation has attracted growing interest with the advancement of deep generative models. However, generating music conditioned on textual descriptions, known as text-to-music, remains challenging due to the complexity of musical structures and high sampling rate requirements. Despite the task's significance, prevailing generative models exhibit limitations in music quality, computational efficiency, and generalization. This paper introduces JEN-1, a universal high-fidelity model for text-to-music generation. JEN-1 is a diffusion model incorporating both autoregressive and non-autoregressive training. Through in-context learning, JEN-1 performs various generation tasks including text-guided music generation, music inpainting, and continuation. Evaluations demonstrate JEN-1's superior performance over state-of-the-art methods in text-music alignment and music quality while maintaining computational efficiency. Our demos are available at http://futureverse.com/research/jen/demos/jen1
Audio-Visual Segmentation by Exploring Cross-Modal Mutual Semantics
Aug 01, 2023The audio-visual segmentation (AVS) task aims to segment sounding objects from a given video. Existing works mainly focus on fusing audio and visual features of a given video to achieve sounding object masks. However, we observed that prior arts are prone to segment a certain salient object in a video regardless of the audio information. This is because sounding objects are often the most salient ones in the AVS dataset. Thus, current AVS methods might fail to localize genuine sounding objects due to the dataset bias. In this work, we present an audio-visual instance-aware segmentation approach to overcome the dataset bias. In a nutshell, our method first localizes potential sounding objects in a video by an object segmentation network, and then associates the sounding object candidates with the given audio. We notice that an object could be a sounding object in one video but a silent one in another video. This would bring ambiguity in training our object segmentation network as only sounding objects have corresponding segmentation masks. We thus propose a silent object-aware segmentation objective to alleviate the ambiguity. Moreover, since the category information of audio is unknown, especially for multiple sounding sources, we propose to explore the audio-visual semantic correlation and then associate audio with potential objects. Specifically, we attend predicted audio category scores to potential instance masks and these scores will highlight corresponding sounding instances while suppressing inaudible ones. When we enforce the attended instance masks to resemble the ground-truth mask, we are able to establish audio-visual semantics correlation. Experimental results on the AVS benchmarks demonstrate that our method can effectively segment sounding objects without being biased to salient objects.
Dynamic Gradient Reactivation for Backward Compatible Person Re-identification
Jul 12, 2022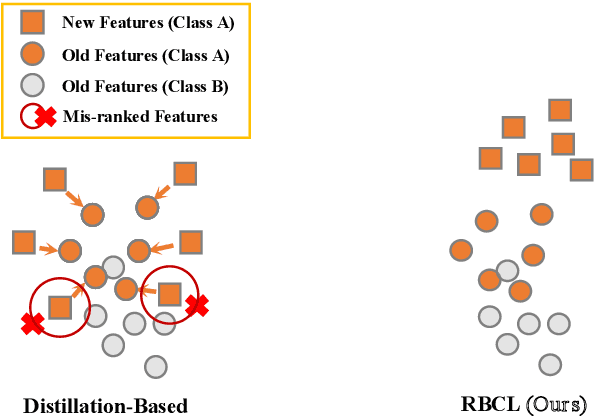
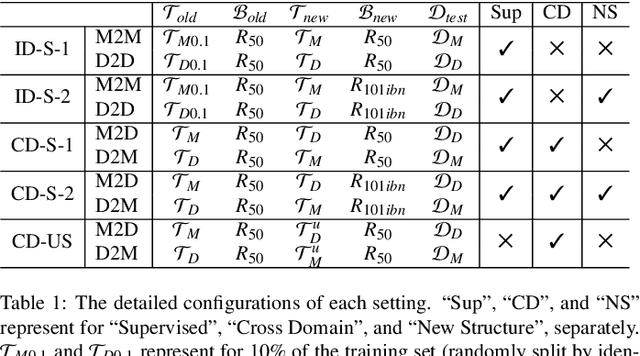
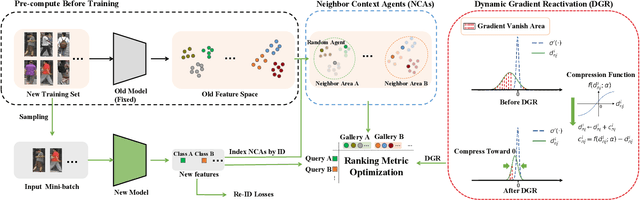

We study the backward compatible problem for person re-identification (Re-ID), which aims to constrain the features of an updated new model to be comparable with the existing features from the old model in galleries. Most of the existing works adopt distillation-based methods, which focus on pushing new features to imitate the distribution of the old ones. However, the distillation-based methods are intrinsically sub-optimal since it forces the new feature space to imitate the inferior old feature space. To address this issue, we propose the Ranking-based Backward Compatible Learning (RBCL), which directly optimizes the ranking metric between new features and old features. Different from previous methods, RBCL only pushes the new features to find best-ranking positions in the old feature space instead of strictly alignment, and is in line with the ultimate goal of backward retrieval. However, the sharp sigmoid function used to make the ranking metric differentiable also incurs the gradient vanish issue, therefore stems the ranking refinement during the later period of training. To address this issue, we propose the Dynamic Gradient Reactivation (DGR), which can reactivate the suppressed gradients by adding dynamic computed constant during forward step. To further help targeting the best-ranking positions, we include the Neighbor Context Agents (NCAs) to approximate the entire old feature space during training. Unlike previous works which only test on the in-domain settings, we make the first attempt to introduce the cross-domain settings (including both supervised and unsupervised), which are more meaningful and difficult. The experimental results on all five settings show that the proposed RBCL outperforms previous state-of-the-art methods by large margins under all settings.