 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwingArena: Competitive Programming Arena for Long-context GitHub Issue Solving
May 29, 2025



We present SwingArena, a competitive evaluation framework for Large Language Models (LLMs) that closely mirrors real-world software development workflows. Unlike traditional static benchmarks, SwingArena models the collaborative process of software iteration by pairing LLMs as submitters, who generate patches, and reviewers, who create test cases and verify the patches through continuous integration (CI) pipelines. To support these interactive evaluations, we introduce a retrieval-augmented code generation (RACG) module that efficiently handles long-context challenges by providing syntactically and semantically relevant code snippets from large codebases, supporting multiple programming languages (C++, Python, Rust, and Go). This enables the framework to scale across diverse tasks and contexts while respecting token limitations. Our experiments, using over 400 high-quality real-world GitHub issues selected from a pool of 2,300 issues, show that models like GPT-4o excel at aggressive patch generation, whereas DeepSeek and Gemini prioritize correctness in CI validation. SwingArena presents a scalable and extensible methodology for evaluating LLMs in realistic, CI-driven software development settings. More details are available on our project page: swing-bench.github.io
Infi-MMR: Curriculum-based Unlocking Multimodal Reasoning via Phased Reinforcement Learning in Multimodal Small Language Models
May 29, 2025



Recent advancements in large language models (LLMs) have demonstrated substantial progress in reasoning capabilities, such as DeepSeek-R1, which leverages rule-based reinforcement learning to enhance logical reasoning significantly. However, extending these achievements to multimodal large language models (MLLMs) presents critical challenges, which are frequently more pronounced for Multimodal Small Language Models (MSLMs) given their typically weaker foundational reasoning abilities: (1) the scarcity of high-quality multimodal reasoning datasets, (2) the degradation of reasoning capabilities due to the integration of visual processing, and (3) the risk that direct application of reinforcement learning may produce complex yet incorrect reasoning processes. To address these challenges, we design a novel framework Infi-MMR to systematically unlock the reasoning potential of MSLMs through a curriculum of three carefully structured phases and propose our multimodal reasoning model Infi-MMR-3B. The first phase, Foundational Reasoning Activation, leverages high-quality textual reasoning datasets to activate and strengthen the model's logical reasoning capabilities. The second phase, Cross-Modal Reasoning Adaptation, utilizes caption-augmented multimodal data to facilitate the progressive transfer of reasoning skills to multimodal contexts. The third phase, Multimodal Reasoning Enhancement, employs curated, caption-free multimodal data to mitigate linguistic biases and promote robust cross-modal reasoning. Infi-MMR-3B achieves both state-of-the-art multimodal math reasoning ability (43.68% on MathVerse testmini, 27.04% on MathVision test, and 21.33% on OlympiadBench) and general reasoning ability (67.2% on MathVista testmini).
Infi-Med: Low-Resource Medical MLLMs with Robust Reasoning Evaluation
May 29, 2025
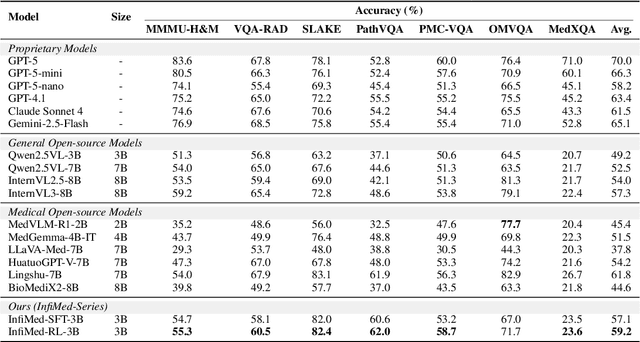
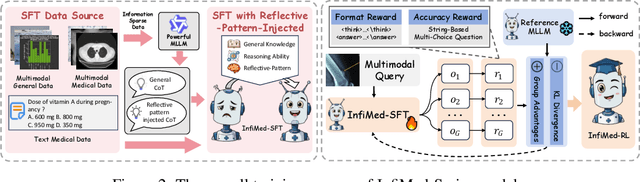
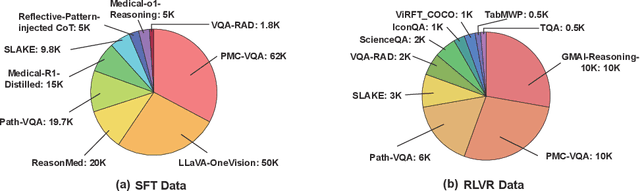
Multimodal large language models (MLLMs) have demonstrated promising prospects in healthcare, particularly for addressing complex medical tasks, supporting multidisciplinary treatment (MDT), and enabling personalized precision medicine. However, their practical deployment faces critical challenges in resource efficiency, diagnostic accuracy, clinical considerations, and ethical privacy. To address these limitations, we propose Infi-Med, a comprehensive framework for medical MLLMs that introduces three key innovations: (1) a resource-efficient approach through curating and constructing high-quality supervised fine-tuning (SFT) datasets with minimal sample requirements, with a forward-looking design that extends to both pretraining and posttraining phases; (2) enhanced multimodal reasoning capabilities for cross-modal integration and clinical task understanding; and (3) a systematic evaluation system that assesses model performance across medical modalities and task types. Our experiments demonstrate that Infi-Med achieves state-of-the-art (SOTA) performance in general medical reasoning while maintaining rapid adaptability to clinical scenarios. The framework establishes a solid foundation for deploying MLLMs in real-world healthcare settings by balancing model effectiveness with operational constraints.
InfiFPO: Implicit Model Fusion via Preference Optimization in Large Language Models
May 20, 2025Model fusion combines multiple Large Language Models (LLMs) with different strengths into a more powerful, integrated model through lightweight training methods. Existing works on model fusion focus primarily on supervised fine-tuning (SFT), leaving preference alignment (PA) --a critical phase for enhancing LLM performance--largely unexplored. The current few fusion methods on PA phase, like WRPO, simplify the process by utilizing only response outputs from source models while discarding their probability information. To address this limitation, we propose InfiFPO, a preference optimization method for implicit model fusion. InfiFPO replaces the reference model in Direct Preference Optimization (DPO) with a fused source model that synthesizes multi-source probabilities at the sequence level, circumventing complex vocabulary alignment challenges in previous works and meanwhile maintaining the probability information. By introducing probability clipping and max-margin fusion strategies, InfiFPO enables the pivot model to align with human preferences while effectively distilling knowledge from source models. Comprehensive experiments on 11 widely-used benchmarks demonstrate that InfiFPO consistently outperforms existing model fusion and preference optimization methods. When using Phi-4 as the pivot model, InfiFPO improve its average performance from 79.95 to 83.33 on 11 benchmarks, significantly improving its capabilities in mathematics, coding, and reasoning tasks.
InfiGFusion: Graph-on-Logits Distillation via Efficient Gromov-Wasserstein for Model Fusion
May 20, 2025

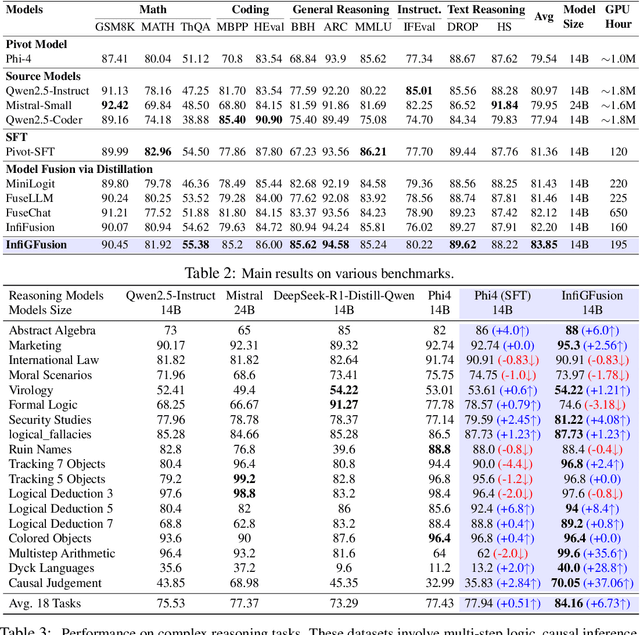

Recent advances in large language models (LLMs) have intensified efforts to fuse heterogeneous open-source models into a unified system that inherits their complementary strengths. Existing logit-based fusion methods maintain inference efficiency but treat vocabulary dimensions independently, overlooking semantic dependencies encoded by cross-dimension interactions. These dependencies reflect how token types interact under a model's internal reasoning and are essential for aligning models with diverse generation behaviors. To explicitly model these dependencies, we propose \textbf{InfiGFusion}, the first structure-aware fusion framework with a novel \textit{Graph-on-Logits Distillation} (GLD) loss. Specifically, we retain the top-$k$ logits per output and aggregate their outer products across sequence positions to form a global co-activation graph, where nodes represent vocabulary channels and edges quantify their joint activations. To ensure scalability and efficiency, we design a sorting-based closed-form approximation that reduces the original $O(n^4)$ cost of Gromov-Wasserstein distance to $O(n \log n)$, with provable approximation guarantees. Experiments across multiple fusion settings show that GLD consistently improves fusion quality and stability. InfiGFusion outperforms SOTA models and fusion baselines across 11 benchmarks spanning reasoning, coding, and mathematics. It shows particular strength in complex reasoning tasks, with +35.6 improvement on Multistep Arithmetic and +37.06 on Causal Judgement over SFT, demonstrating superior multi-step and relational inference.
InfiJanice: Joint Analysis and In-situ Correction Engine for Quantization-Induced Math Degradation in Large Language Models
May 16, 2025



Large Language Models (LLMs) have demonstrated impressive performance on complex reasoning benchmarks such as GSM8K, MATH, and AIME. However, the substantial computational demands of these tasks pose significant challenges for real-world deployment. Model quantization has emerged as a promising approach to reduce memory footprint and inference latency by representing weights and activations with lower bit-widths. In this work, we conduct a comprehensive study of mainstream quantization methods(e.g., AWQ, GPTQ, SmoothQuant) on the most popular open-sourced models (e.g., Qwen2.5, LLaMA3 series), and reveal that quantization can degrade mathematical reasoning accuracy by up to 69.81%. To better understand this degradation, we develop an automated assignment and judgment pipeline that qualitatively categorizes failures into four error types and quantitatively identifies the most impacted reasoning capabilities. Building on these findings, we employ an automated data-curation pipeline to construct a compact "Silver Bullet" datasets. Training a quantized model on as few as 332 carefully selected examples for just 3-5 minutes on a single GPU is enough to restore its reasoning accuracy to match that of the full-precision baseline.
EcoAgent: An Efficient Edge-Cloud Collaborative Multi-Agent Framework for Mobile Automation
May 08, 2025Cloud-based mobile agents powered by (multimodal) large language models ((M)LLMs) offer strong reasoning abilities but suffer from high latency and cost. While fine-tuned (M)SLMs enable edge deployment, they often lose general capabilities and struggle with complex tasks. To address this, we propose EcoAgent, an Edge-Cloud cOllaborative multi-agent framework for mobile automation. EcoAgent features a closed-loop collaboration among a cloud-based Planning Agent and two edge-based agents: the Execution Agent for action execution and the Observation Agent for verifying outcomes. The Observation Agent uses a Pre-Understanding Module to compress screen images into concise text, reducing token usage. In case of failure, the Planning Agent retrieves screen history and replans via a Reflection Module. Experiments on AndroidWorld show that EcoAgent maintains high task success rates while significantly reducing MLLM token consumption, enabling efficient and practical mobile automation.
InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
Apr 19, 2025Multimodal Large Language Models (MLLMs) have powered Graphical User Interface (GUI) Agents, showing promise in automating tasks on computing devices. Recent works have begun exploring reasoning in GUI tasks with encouraging results. However, many current approaches rely on manually designed reasoning templates, which may result in reasoning that is not sufficiently robust and adaptive for complex GUI environments. Meanwhile, some existing agents continue to operate as Reactive Actors, relying primarily on implicit reasoning that may lack sufficient depth for GUI tasks demanding planning and error recovery. We argue that advancing these agents requires a shift from reactive acting towards acting based on deliberate reasoning. To facilitate this transformation, we introduce InfiGUI-R1, an MLLM-based GUI agent developed through our Actor2Reasoner framework, a reasoning-centric, two-stage training approach designed to progressively evolve agents from Reactive Actors to Deliberative Reasoners. The first stage, Reasoning Injection, focuses on establishing a basic reasoner. We employ Spatial Reasoning Distillation to transfer cross-modal spatial reasoning capabilities from teacher models to MLLMs through trajectories with explicit reasoning steps, enabling models to integrate GUI visual-spatial information with logical reasoning before action generation. The second stage, Deliberation Enhancement, refines the basic reasoner into a deliberative one using Reinforcement Learning. This stage introduces two approaches: Sub-goal Guidance, which rewards models for generating accurate intermediate sub-goals, and Error Recovery Scenario Construction, which creates failure-and-recovery training scenarios from identified prone-to-error steps. Experimental results show InfiGUI-R1 achieves strong performance in GUI grounding and trajectory tasks. Resources at https://github.com/Reallm-Labs/InfiGUI-R1.
ParallelComp: Parallel Long-Context Compressor for Length Extrapolation
Feb 20, 2025



Efficiently handling long contexts is crucial for large language models (LLMs). While rotary position embeddings (RoPEs) enhance length generalization, effective length extrapolation remains challenging and often requires costly fine-tuning. In contrast, recent training-free approaches suffer from the attention sink phenomenon, leading to severe performance degradation. In this paper, we introduce ParallelComp, a novel training-free method for long-context extrapolation that extends LLMs' context length from 4K to 128K while maintaining high throughput and preserving perplexity, and integrates seamlessly with Flash Attention. Our analysis offers new insights into attention biases in parallel attention mechanisms and provides practical solutions to tackle these challenges. To mitigate the attention sink issue, we propose an attention calibration strategy that reduces biases, ensuring more stable long-range attention. Additionally, we introduce a chunk eviction strategy to efficiently manage ultra-long contexts on a single A100 80GB GPU. To further enhance efficiency, we propose a parallel KV cache eviction technique, which improves chunk throughput by 1.76x, thereby achieving a 23.50x acceleration in the prefilling stage with negligible performance loss due to attention calibration. Furthermore, ParallelComp achieves 91.17% of GPT-4's performance on long-context tasks using an 8B model trained on 8K-length context, outperforming powerful closed-source models such as Claude-2 and Kimi-Chat.
InfiR : Crafting Effective Small Language Models and Multimodal Small Language Models in Reasoning
Feb 17, 2025



Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) have made significant advancements in reasoning capabilities. However, they still face challenges such as high computational demands and privacy concerns. This paper focuses on developing efficient Small Language Models (SLMs) and Multimodal Small Language Models (MSLMs) that retain competitive reasoning abilities. We introduce a novel training pipeline that enhances reasoning capabilities and facilitates deployment on edge devices, achieving state-of-the-art performance while minimizing development costs. \InfR~ aims to advance AI systems by improving reasoning, reducing adoption barriers, and addressing privacy concerns through smaller model sizes. Resources are available at https://github. com/Reallm-Labs/InfiR.