 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnerVerse-AC: Envisioning Embodied Environments with Action Condition
May 14, 2025Robotic imitation learning has advanced from solving static tasks to addressing dynamic interaction scenarios, but testing and evaluation remain costly and challenging due to the need for real-time interaction with dynamic environments. We propose EnerVerse-AC (EVAC), an action-conditional world model that generates future visual observations based on an agent's predicted actions, enabling realistic and controllable robotic inference. Building on prior architectures, EVAC introduces a multi-level action-conditioning mechanism and ray map encoding for dynamic multi-view image generation while expanding training data with diverse failure trajectories to improve generalization. As both a data engine and evaluator, EVAC augments human-collected trajectories into diverse datasets and generates realistic, action-conditioned video observations for policy testing, eliminating the need for physical robots or complex simulations. This approach significantly reduces costs while maintaining high fidelity in robotic manipulation evaluation. Extensive experiments validate the effectiveness of our method. Code, checkpoints, and datasets can be found at <https://annaj2178.github.io/EnerverseAC.github.io>.
Adaptive Markup Language Generation for Contextually-Grounded Visual Document Understanding
May 08, 2025



Visual Document Understanding has become essential with the increase of text-rich visual content. This field poses significant challenges due to the need for effective integration of visual perception and textual comprehension, particularly across diverse document types with complex layouts. Moreover, existing fine-tuning datasets for this domain often fall short in providing the detailed contextual information for robust understanding, leading to hallucinations and limited comprehension of spatial relationships among visual elements. To address these challenges, we propose an innovative pipeline that utilizes adaptive generation of markup languages, such as Markdown, JSON, HTML, and TiKZ, to build highly structured document representations and deliver contextually-grounded responses. We introduce two fine-grained structured datasets: DocMark-Pile, comprising approximately 3.8M pretraining data pairs for document parsing, and DocMark-Instruct, featuring 624k fine-tuning data annotations for grounded instruction following. Extensive experiments demonstrate that our proposed model significantly outperforms existing state-of-theart MLLMs across a range of visual document understanding benchmarks, facilitating advanced reasoning and comprehension capabilities in complex visual scenarios. Our code and models are released at https://github. com/Euphoria16/DocMark.
WebGen-Bench: Evaluating LLMs on Generating Interactive and Functional Websites from Scratch
May 06, 2025
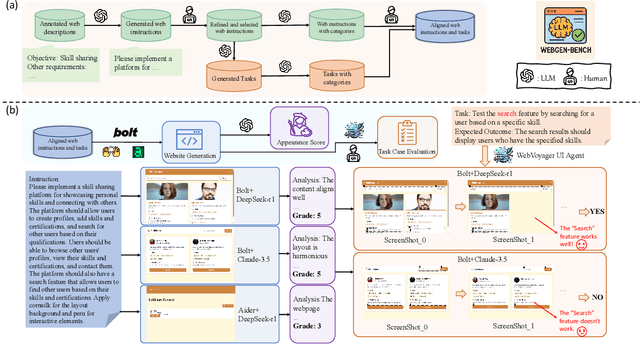
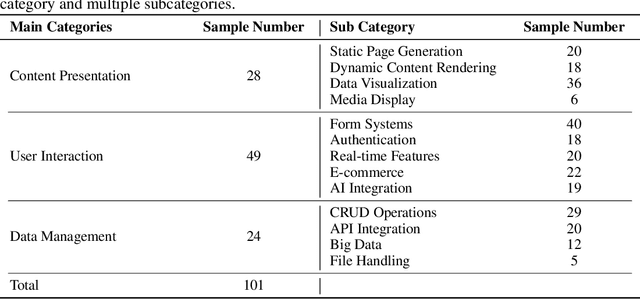
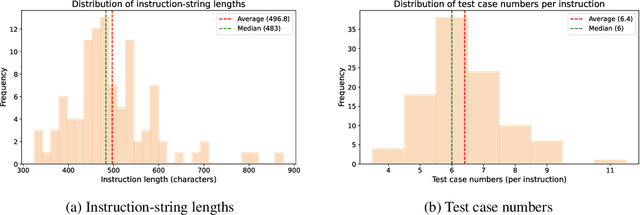
LLM-based agents have demonstrated great potential in generating and managing code within complex codebases. In this paper, we introduce WebGen-Bench, a novel benchmark designed to measure an LLM-based agent's ability to create multi-file website codebases from scratch. It contains diverse instructions for website generation, created through the combined efforts of human annotators and GPT-4o. These instructions span three major categories and thirteen minor categories, encompassing nearly all important types of web applications. To assess the quality of the generated websites, we use GPT-4o to generate test cases targeting each functionality described in the instructions, and then manually filter, adjust, and organize them to ensure accuracy, resulting in 647 test cases. Each test case specifies an operation to be performed on the website and the expected result after the operation. To automate testing and improve reproducibility, we employ a powerful web-navigation agent to execute tests on the generated websites and determine whether the observed responses align with the expected results. We evaluate three high-performance code-agent frameworks, Bolt.diy, OpenHands, and Aider, using multiple proprietary and open-source LLMs as engines. The best-performing combination, Bolt.diy powered by DeepSeek-R1, achieves only 27.8\% accuracy on the test cases, highlighting the challenging nature of our benchmark. Additionally, we construct WebGen-Instruct, a training set consisting of 6,667 website-generation instructions. Training Qwen2.5-Coder-32B-Instruct on Bolt.diy trajectories generated from a subset of this training set achieves an accuracy of 38.2\%, surpassing the performance of the best proprietary model.
T2I-R1: Reinforcing Image Generation with Collaborative Semantic-level and Token-level CoT
May 01, 2025Recent advancements in large language models have demonstrated how chain-of-thought (CoT) and reinforcement learning (RL) can improve performance. However, applying such reasoning strategies to the visual generation domain remains largely unexplored. In this paper, we present T2I-R1, a novel reasoning-enhanced text-to-image generation model, powered by RL with a bi-level CoT reasoning process. Specifically, we identify two levels of CoT that can be utilized to enhance different stages of generation: (1) the semantic-level CoT for high-level planning of the prompt and (2) the token-level CoT for low-level pixel processing during patch-by-patch generation. To better coordinate these two levels of CoT, we introduce BiCoT-GRPO with an ensemble of generation rewards, which seamlessly optimizes both generation CoTs within the same training step. By applying our reasoning strategies to the baseline model, Janus-Pro, we achieve superior performance with 13% improvement on T2I-CompBench and 19% improvement on the WISE benchmark, even surpassing the state-of-the-art model FLUX.1. Code is available at: https://github.com/CaraJ7/T2I-R1
From Reflection to Perfection: Scaling Inference-Time Optimization for Text-to-Image Diffusion Models via Reflection Tuning
Apr 22, 2025Recent text-to-image diffusion models achieve impressive visual quality through extensive scaling of training data and model parameters, yet they often struggle with complex scenes and fine-grained details. Inspired by the self-reflection capabilities emergent in large language models, we propose ReflectionFlow, an inference-time framework enabling diffusion models to iteratively reflect upon and refine their outputs. ReflectionFlow introduces three complementary inference-time scaling axes: (1) noise-level scaling to optimize latent initialization; (2) prompt-level scaling for precise semantic guidance; and most notably, (3) reflection-level scaling, which explicitly provides actionable reflections to iteratively assess and correct previous generations. To facilitate reflection-level scaling, we construct GenRef, a large-scale dataset comprising 1 million triplets, each containing a reflection, a flawed image, and an enhanced image. Leveraging this dataset, we efficiently perform reflection tuning on state-of-the-art diffusion transformer, FLUX.1-dev, by jointly modeling multimodal inputs within a unified framework. Experimental results show that ReflectionFlow significantly outperforms naive noise-level scaling methods, offering a scalable and compute-efficient solution toward higher-quality image synthesis on challenging tasks.
Exposing the Copycat Problem of Imitation-based Planner: A Novel Closed-Loop Simulator, Causal Benchmark and Joint IL-RL Baseline
Apr 20, 2025



Machine learning (ML)-based planners have recently gained significant attention. They offer advantages over traditional optimization-based planning algorithms. These advantages include fewer manually selected parameters and faster development. Within ML-based planning, imitation learning (IL) is a common algorithm. It primarily learns driving policies directly from supervised trajectory data. While IL has demonstrated strong performance on many open-loop benchmarks, it remains challenging to determine if the learned policy truly understands fundamental driving principles, rather than simply extrapolating from the ego-vehicle's initial state. Several studies have identified this limitation and proposed algorithms to address it. However, these methods often use original datasets for evaluation. In these datasets, future trajectories are heavily dependent on initial conditions. Furthermore, IL often overfits to the most common scenarios. It struggles to generalize to rare or unseen situations. To address these challenges, this work proposes: 1) a novel closed-loop simulator supporting both imitation and reinforcement learning, 2) a causal benchmark derived from the Waymo Open Dataset to rigorously assess the impact of the copycat problem, and 3) a novel framework integrating imitation learning and reinforcement learning to overcome the limitations of purely imitative approaches. The code for this work will be released soon.
High-Fidelity Diffusion Face Swapping with ID-Constrained Facial Conditioning
Mar 28, 2025Face swapping aims to seamlessly transfer a source facial identity onto a target while preserving target attributes such as pose and expression. Diffusion models, known for their superior generative capabilities, have recently shown promise in advancing face-swapping quality. This paper addresses two key challenges in diffusion-based face swapping: the prioritized preservation of identity over target attributes and the inherent conflict between identity and attribute conditioning. To tackle these issues, we introduce an identity-constrained attribute-tuning framework for face swapping that first ensures identity preservation and then fine-tunes for attribute alignment, achieved through a decoupled condition injection. We further enhance fidelity by incorporating identity and adversarial losses in a post-training refinement stage. Our proposed identity-constrained diffusion-based face-swapping model outperforms existing methods in both qualitative and quantitative evaluations, demonstrating superior identity similarity and attribute consistency, achieving a new state-of-the-art performance in high-fidelity face swapping.
LeX-Art: Rethinking Text Generation via Scalable High-Quality Data Synthesis
Mar 27, 2025We introduce LeX-Art, a comprehensive suite for high-quality text-image synthesis that systematically bridges the gap between prompt expressiveness and text rendering fidelity. Our approach follows a data-centric paradigm, constructing a high-quality data synthesis pipeline based on Deepseek-R1 to curate LeX-10K, a dataset of 10K high-resolution, aesthetically refined 1024$\times$1024 images. Beyond dataset construction, we develop LeX-Enhancer, a robust prompt enrichment model, and train two text-to-image models, LeX-FLUX and LeX-Lumina, achieving state-of-the-art text rendering performance. To systematically evaluate visual text generation, we introduce LeX-Bench, a benchmark that assesses fidelity, aesthetics, and alignment, complemented by Pairwise Normalized Edit Distance (PNED), a novel metric for robust text accuracy evaluation. Experiments demonstrate significant improvements, with LeX-Lumina achieving a 79.81% PNED gain on CreateBench, and LeX-FLUX outperforming baselines in color (+3.18%), positional (+4.45%), and font accuracy (+3.81%). Our codes, models, datasets, and demo are publicly available.
Lumina-Image 2.0: A Unified and Efficient Image Generative Framework
Mar 27, 2025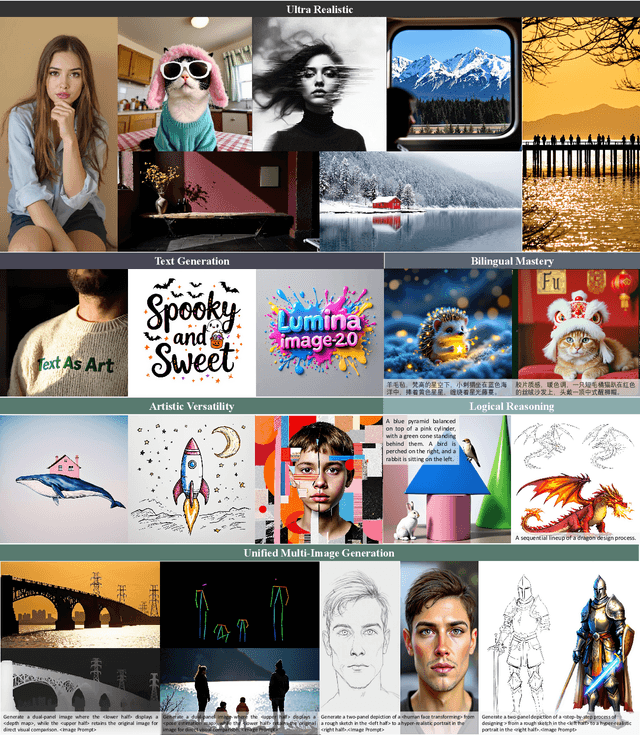
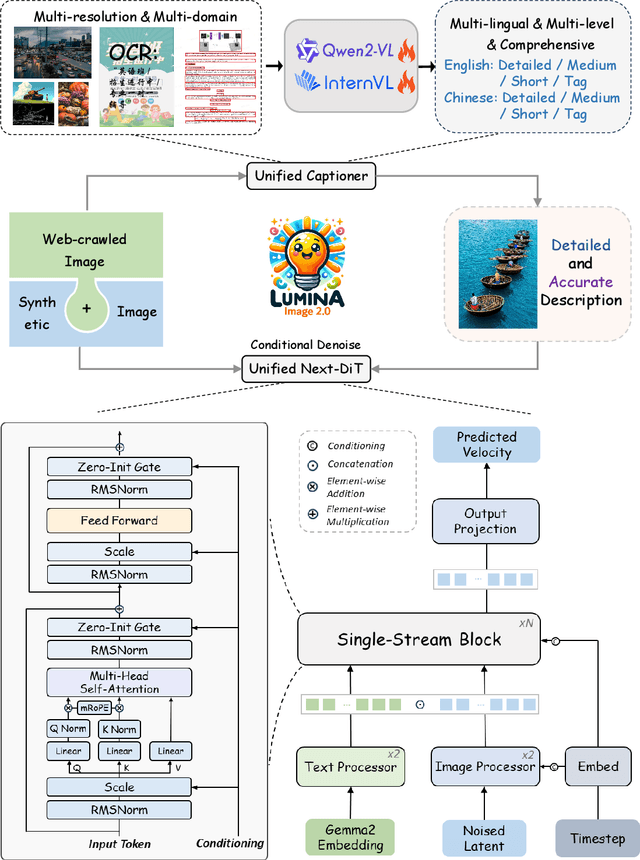

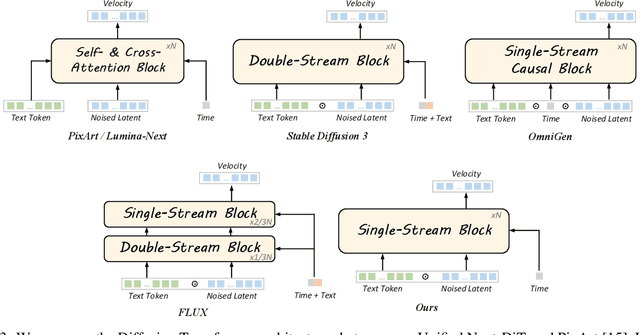
We introduce Lumina-Image 2.0, an advanced text-to-image generation framework that achieves significant progress compared to previous work, Lumina-Next. Lumina-Image 2.0 is built upon two key principles: (1) Unification - it adopts a unified architecture (Unified Next-DiT) that treats text and image tokens as a joint sequence, enabling natural cross-modal interactions and allowing seamless task expansion. Besides, since high-quality captioners can provide semantically well-aligned text-image training pairs, we introduce a unified captioning system, Unified Captioner (UniCap), specifically designed for T2I generation tasks. UniCap excels at generating comprehensive and accurate captions, accelerating convergence and enhancing prompt adherence. (2) Efficiency - to improve the efficiency of our proposed model, we develop multi-stage progressive training strategies and introduce inference acceleration techniques without compromising image quality. Extensive evaluations on academic benchmarks and public text-to-image arenas show that Lumina-Image 2.0 delivers strong performances even with only 2.6B parameters, highlighting its scalability and design efficiency. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-Image-2.0.
UI-R1: Enhancing Action Prediction of GUI Agents by Reinforcement Learning
Mar 27, 2025



The recent DeepSeek-R1 has showcased the emergence of reasoning capabilities in LLMs through reinforcement learning (RL) with rule-based rewards. Building on this idea, we are the first to explore how rule-based RL can enhance the reasoning capabilities of multimodal large language models (MLLMs) for graphic user interface (GUI) action prediction tasks. To this end, we curate a small yet high-quality dataset of 136 challenging tasks, encompassing five common action types on mobile devices. We also introduce a unified rule-based action reward, enabling model optimization via policy-based algorithms such as Group Relative Policy Optimization (GRPO). Experimental results demonstrate that our proposed data-efficient model, UI-R1-3B, achieves substantial improvements on both in-domain (ID) and out-of-domain (OOD) tasks. Specifically, on the ID benchmark AndroidControl, the action type accuracy improves by 15%, while grounding accuracy increases by 10.3%, compared with the base model (i.e. Qwen2.5-VL-3B). On the OOD GUI grounding benchmark ScreenSpot-Pro, our model surpasses the base model by 6.0% and achieves competitive performance with larger models (e.g., OS-Atlas-7B), which are trained via supervised fine-tuning (SFT) on 76K data. These results underscore the potential of rule-based reinforcement learning to advance GUI understanding and control, paving the way for future research in this domain.