 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Misalignment Can Be Induced by Sycophancy and Reversed via Alignment Gating
Jun 08, 2026Prior work has shown that fine-tuning large language models on malicious or incorrect outputs in narrow domains can induce broad misalignment and harmful behavior, a phenomenon known as emergent misalignment. However, efficient methods for reversing such misalignment remain limited. In this work, we make two contributions. First, we identify sycophancy fine-tuning, i.e., training models to passively agree with users' incorrect opinions, as a previously underexplored driver of emergent misalignment, and show that it induces broad and severe misaligned behavior. Second, we propose Alignment Gating, an efficient method for reversing emergent misalignment that inserts learnable and controllable gates into the model during fine-tuning. Through fine-tuning, these gates learn to identify the internal representations responsible for unsafe responses. Thus, amplifying or suppressing these representations then exacerbates or mitigates EM, respectively. We further find that alignment gating module exhibits strong generalization: gating weights obtained from narrow-domain fine-tuning substantially suppress broad-domain misaligned behavior while preserving the model's general capabilities.
A^3: Towards Advertising Aesthetic Assessment
Mar 25, 2026Advertising images significantly impact commercial conversion rates and brand equity, yet current evaluation methods rely on subjective judgments, lacking scalability, standardized criteria, and interpretability. To address these challenges, we present A^3 (Advertising Aesthetic Assessment), a comprehensive framework encompassing four components: a paradigm (A^3-Law), a dataset (A^3-Dataset), a multimodal large language model (A^3-Align), and a benchmark (A^3-Bench). Central to A^3 is a theory-driven paradigm, A^3-Law, comprising three hierarchical stages: (1) Perceptual Attention, evaluating perceptual image signals for their ability to attract attention; (2) Formal Interest, assessing formal composition of image color and spatial layout in evoking interest; and (3) Desire Impact, measuring desire evocation from images and their persuasive impact. Building on A^3-Law, we construct A^3-Dataset with 120K instruction-response pairs from 30K advertising images, each richly annotated with multi-dimensional labels and Chain-of-Thought (CoT) rationales. We further develop A^3-Align, trained under A^3-Law with CoT-guided learning on A^3-Dataset. Extensive experiments on A^3-Bench demonstrate that A^3-Align achieves superior alignment with A^3-Law compared to existing models, and this alignment generalizes well to quality advertisement selection and prescriptive advertisement critique, indicating its potential for broader deployment. Dataset, code, and models can be found at: https://github.com/euleryuan/A3-Align.
UniDial-EvalKit: A Unified Toolkit for Evaluating Multi-Faceted Conversational Abilities
Mar 24, 2026Benchmarking AI systems in multi-turn interactive scenarios is essential for understanding their practical capabilities in real-world applications. However, existing evaluation protocols are highly heterogeneous, differing significantly in dataset formats, model interfaces, and evaluation pipelines, which severely impedes systematic comparison. In this work, we present UniDial-EvalKit (UDE), a unified evaluation toolkit for assessing interactive AI systems. The core contribution of UDE lies in its holistic unification: it standardizes heterogeneous data formats into a universal schema, streamlines complex evaluation pipelines through a modular architecture, and aligns metric calculations under a consistent scoring interface. It also supports efficient large-scale evaluation through parallel generation and scoring, as well as checkpoint-based caching to eliminate redundant computation. Validated across diverse multi-turn benchmarks, UDE not only guarantees high reproducibility through standardized workflows and transparent logging, but also significantly improves evaluation efficiency and extensibility. We make the complete toolkit and evaluation scripts publicly available to foster a standardized benchmarking ecosystem and accelerate future breakthroughs in interactive AI.
SafeSci: Safety Evaluation of Large Language Models in Science Domains and Beyond
Mar 02, 2026The success of large language models (LLMs) in scientific domains has heightened safety concerns, prompting numerous benchmarks to evaluate their scientific safety. Existing benchmarks often suffer from limited risk coverage and a reliance on subjective evaluation. To address these problems, we introduce SafeSci, a comprehensive framework for safety evaluation and enhancement in scientific contexts. SafeSci comprises SafeSciBench, a multi-disciplinary benchmark with 0.25M samples, and SafeSciTrain, a large-scale dataset containing 1.5M samples for safety enhancement. SafeSciBench distinguishes between safety knowledge and risk to cover extensive scopes and employs objective metrics such as deterministically answerable questions to mitigate evaluation bias. We evaluate 24 advanced LLMs, revealing critical vulnerabilities in current models. We also observe that LLMs exhibit varying degrees of excessive refusal behaviors on safety-related issues. For safety enhancement, we demonstrate that fine-tuning on SafeSciTrain significantly enhances the safety alignment of models. Finally, we argue that knowledge is a double-edged sword, and determining the safety of a scientific question should depend on specific context, rather than universally categorizing it as safe or unsafe. Our work provides both a diagnostic tool and a practical resource for building safer scientific AI systems.
Surveillance Facial Image Quality Assessment: A Multi-dimensional Dataset and Lightweight Model
Feb 07, 2026Surveillance facial images are often captured under unconstrained conditions, resulting in severe quality degradation due to factors such as low resolution, motion blur, occlusion, and poor lighting. Although recent face restoration techniques applied to surveillance cameras can significantly enhance visual quality, they often compromise fidelity (i.e., identity-preserving features), which directly conflicts with the primary objective of surveillance images -- reliable identity verification. Existing facial image quality assessment (FIQA) predominantly focus on either visual quality or recognition-oriented evaluation, thereby failing to jointly address visual quality and fidelity, which are critical for surveillance applications. To bridge this gap, we propose the first comprehensive study on surveillance facial image quality assessment (SFIQA), targeting the unique challenges inherent to surveillance scenarios. Specifically, we first construct SFIQA-Bench, a multi-dimensional quality assessment benchmark for surveillance facial images, which consists of 5,004 surveillance facial images captured by three widely deployed surveillance cameras in real-world scenarios. A subjective experiment is conducted to collect six dimensional quality ratings, including noise, sharpness, colorfulness, contrast, fidelity and overall quality, covering the key aspects of SFIQA. Furthermore, we propose SFIQA-Assessor, a lightweight multi-task FIQA model that jointly exploits complementary facial views through cross-view feature interaction, and employs learnable task tokens to guide the unified regression of multiple quality dimensions. The experiment results on the proposed dataset show that our method achieves the best performance compared with the state-of-the-art general image quality assessment (IQA) and FIQA methods, validating its effectiveness for real-world surveillance applications.
Automated Safety Benchmarking: A Multi-agent Pipeline for LVLMs
Jan 27, 2026Large vision-language models (LVLMs) exhibit remarkable capabilities in cross-modal tasks but face significant safety challenges, which undermine their reliability in real-world applications. Efforts have been made to build LVLM safety evaluation benchmarks to uncover their vulnerability. However, existing benchmarks are hindered by their labor-intensive construction process, static complexity, and limited discriminative power. Thus, they may fail to keep pace with rapidly evolving models and emerging risks. To address these limitations, we propose VLSafetyBencher, the first automated system for LVLM safety benchmarking. VLSafetyBencher introduces four collaborative agents: Data Preprocessing, Generation, Augmentation, and Selection agents to construct and select high-quality samples. Experiments validates that VLSafetyBencher can construct high-quality safety benchmarks within one week at a minimal cost. The generated benchmark effectively distinguish safety, with a safety rate disparity of 70% between the most and least safe models.
QualiRAG: Retrieval-Augmented Generation for Visual Quality Understanding
Jan 26, 2026Visual quality assessment (VQA) is increasingly shifting from scalar score prediction toward interpretable quality understanding -- a paradigm that demands \textit{fine-grained spatiotemporal perception} and \textit{auxiliary contextual information}. Current approaches rely on supervised fine-tuning or reinforcement learning on curated instruction datasets, which involve labor-intensive annotation and are prone to dataset-specific biases. To address these challenges, we propose \textbf{QualiRAG}, a \textit{training-free} \textbf{R}etrieval-\textbf{A}ugmented \textbf{G}eneration \textbf{(RAG)} framework that systematically leverages the latent perceptual knowledge of large multimodal models (LMMs) for visual quality perception. Unlike conventional RAG that retrieves from static corpora, QualiRAG dynamically generates auxiliary knowledge by decomposing questions into structured requests and constructing four complementary knowledge sources: \textit{visual metadata}, \textit{subject localization}, \textit{global quality summaries}, and \textit{local quality descriptions}, followed by relevance-aware retrieval for evidence-grounded reasoning. Extensive experiments show that QualiRAG achieves substantial improvements over open-source general-purpose LMMs and VQA-finetuned LMMs on visual quality understanding tasks, and delivers competitive performance on visual quality comparison tasks, demonstrating robust quality assessment capabilities without any task-specific training. The code will be publicly available at https://github.com/clh124/QualiRAG.
Embodied Image Compression
Dec 12, 2025



Image Compression for Machines (ICM) has emerged as a pivotal research direction in the field of visual data compression. However, with the rapid evolution of machine intelligence, the target of compression has shifted from task-specific virtual models to Embodied agents operating in real-world environments. To address the communication constraints of Embodied AI in multi-agent systems and ensure real-time task execution, this paper introduces, for the first time, the scientific problem of Embodied Image Compression. We establish a standardized benchmark, EmbodiedComp, to facilitate systematic evaluation under ultra-low bitrate conditions in a closed-loop setting. Through extensive empirical studies in both simulated and real-world settings, we demonstrate that existing Vision-Language-Action models (VLAs) fail to reliably perform even simple manipulation tasks when compressed below the Embodied bitrate threshold. We anticipate that EmbodiedComp will catalyze the development of domain-specific compression tailored for Embodied agents , thereby accelerating the Embodied AI deployment in the Real-world.
One Battle After Another: Probing LLMs' Limits on Multi-Turn Instruction Following with a Benchmark Evolving Framework
Nov 05, 2025Understanding how well large language models can follow users' instructions throughout a dialogue spanning multiple topics is of great importance for data-intensive conversational applications. Existing benchmarks are often limited to a fixed number of turns, making them susceptible to saturation and failing to account for the user's interactive experience. In this work, we propose an extensible framework for assessing multi-turn instruction-following ability. At its core, our framework decouples linguistic surface forms from user intent simulation through a three-layer mechanism that tracks constraints, instructions, and topics. This framework mimics User-LLM interaction by enabling the dynamic construction of benchmarks with state changes and tracebacks, terminating a conversation only when the model exhausts a simulated user's patience. We define a suite of metrics capturing the quality of the interaction process. Using this framework, we construct EvolIF, an evolving instruction-following benchmark incorporating nine distinct constraint types. Our results indicate that GPT-5 exhibits superior instruction-following performance. It sustains an average of 18.54 conversational turns and demonstrates 70.31% robustness, outperforming Gemini-2.5-Pro by a significant margin of 11.41%, while other models lag far behind. All of the data and code will be made publicly available online.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
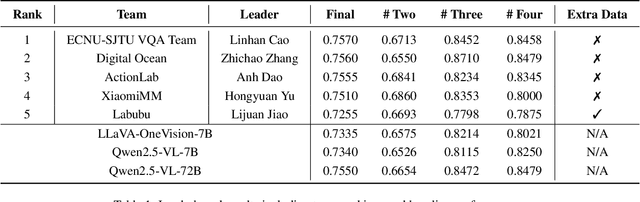
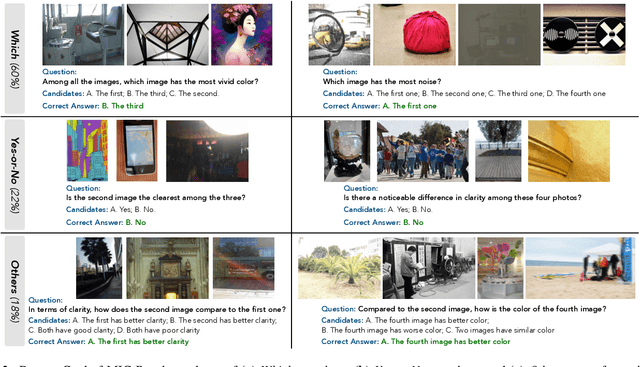
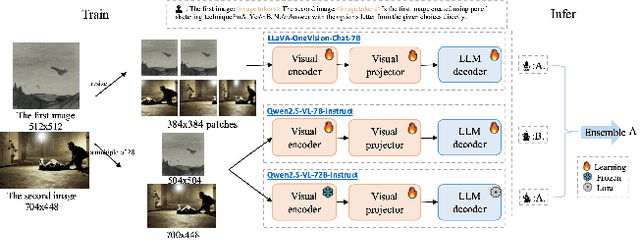
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.