 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget-Guided Dialogue Response Generation Using Commonsense and Data Augmentation
May 19, 2022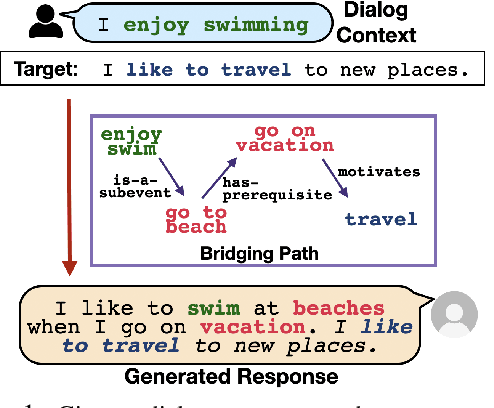
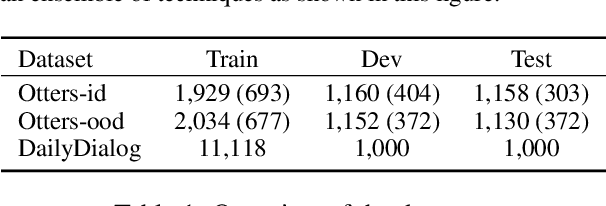
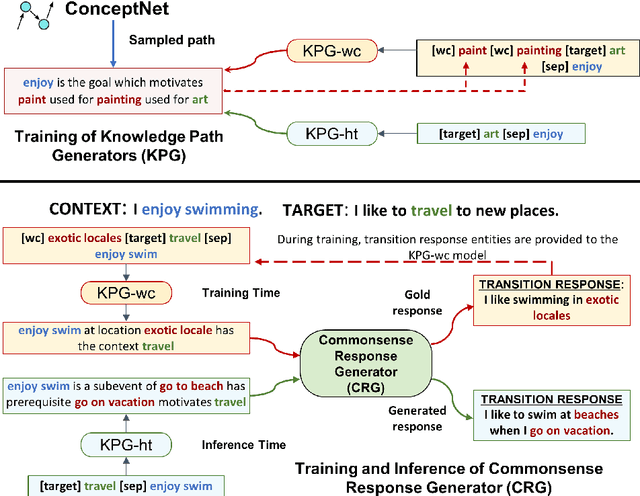
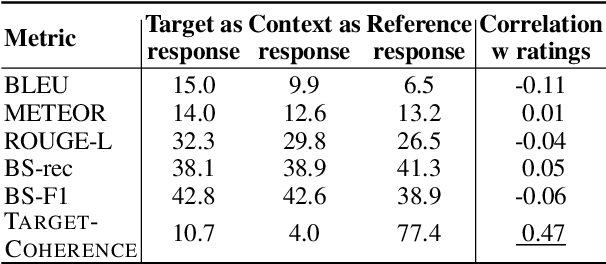
Target-guided response generation enables dialogue systems to smoothly transition a conversation from a dialogue context toward a target sentence. Such control is useful for designing dialogue systems that direct a conversation toward specific goals, such as creating non-obtrusive recommendations or introducing new topics in the conversation. In this paper, we introduce a new technique for target-guided response generation, which first finds a bridging path of commonsense knowledge concepts between the source and the target, and then uses the identified bridging path to generate transition responses. Additionally, we propose techniques to re-purpose existing dialogue datasets for target-guided generation. Experiments reveal that the proposed techniques outperform various baselines on this task. Finally, we observe that the existing automated metrics for this task correlate poorly with human judgement ratings. We propose a novel evaluation metric that we demonstrate is more reliable for target-guided response evaluation. Our work generally enables dialogue system designers to exercise more control over the conversations that their systems produce.
Achieving Conversational Goals with Unsupervised Post-hoc Knowledge Injection
Mar 22, 2022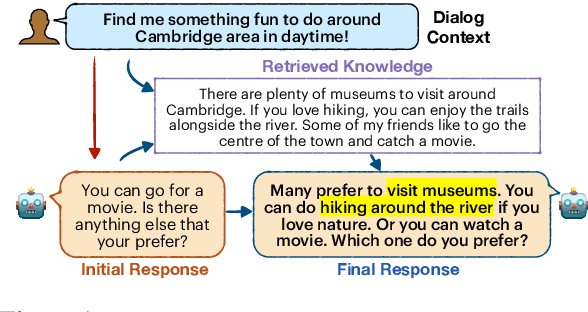
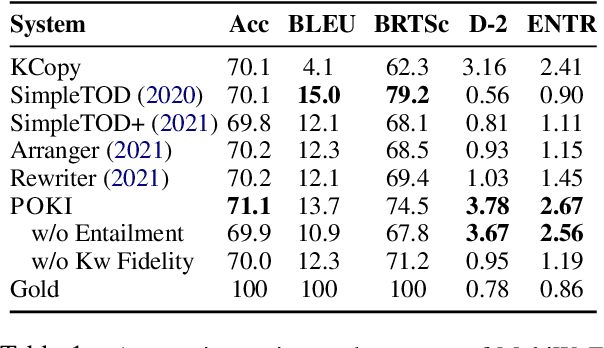
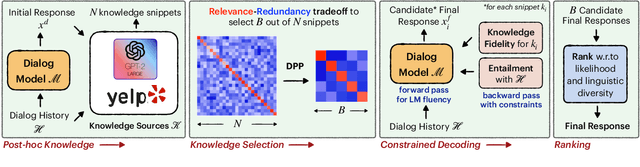
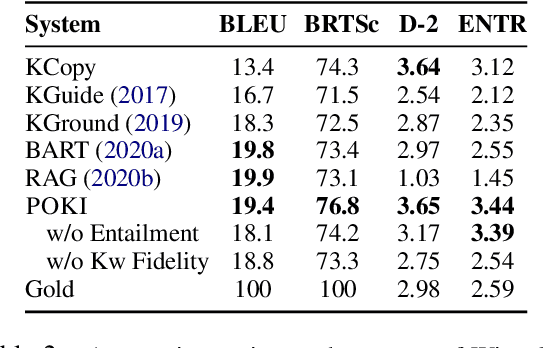
A limitation of current neural dialog models is that they tend to suffer from a lack of specificity and informativeness in generated responses, primarily due to dependence on training data that covers a limited variety of scenarios and conveys limited knowledge. One way to alleviate this issue is to extract relevant knowledge from external sources at decoding time and incorporate it into the dialog response. In this paper, we propose a post-hoc knowledge-injection technique where we first retrieve a diverse set of relevant knowledge snippets conditioned on both the dialog history and an initial response from an existing dialog model. We construct multiple candidate responses, individually injecting each retrieved snippet into the initial response using a gradient-based decoding method, and then select the final response with an unsupervised ranking step. Our experiments in goal-oriented and knowledge-grounded dialog settings demonstrate that human annotators judge the outputs from the proposed method to be more engaging and informative compared to responses from prior dialog systems. We further show that knowledge-augmentation promotes success in achieving conversational goals in both experimental settings.
Truth-Conditional Captioning of Time Series Data
Oct 05, 2021
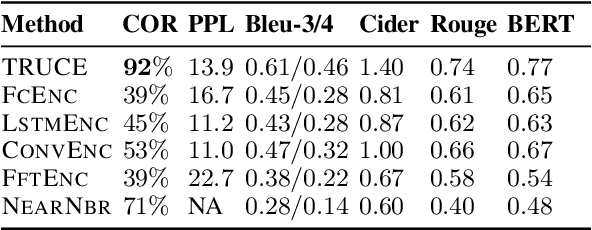
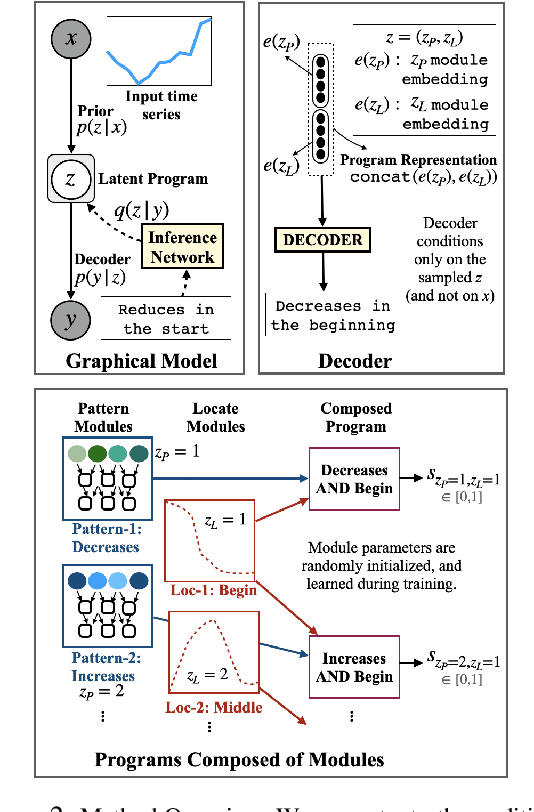
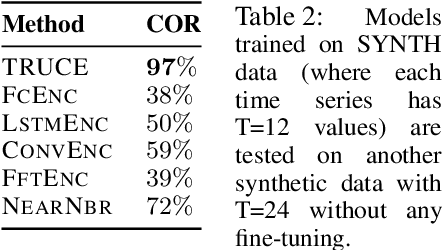
In this paper, we explore the task of automatically generating natural language descriptions of salient patterns in a time series, such as stock prices of a company over a week. A model for this task should be able to extract high-level patterns such as presence of a peak or a dip. While typical contemporary neural models with attention mechanisms can generate fluent output descriptions for this task, they often generate factually incorrect descriptions. We propose a computational model with a truth-conditional architecture which first runs small learned programs on the input time series, then identifies the programs/patterns which hold true for the given input, and finally conditions on only the chosen valid program (rather than the input time series) to generate the output text description. A program in our model is constructed from modules, which are small neural networks that are designed to capture numerical patterns and temporal information. The modules are shared across multiple programs, enabling compositionality as well as efficient learning of module parameters. The modules, as well as the composition of the modules, are unobserved in data, and we learn them in an end-to-end fashion with the only training signal coming from the accompanying natural language text descriptions. We find that the proposed model is able to generate high-precision captions even though we consider a small and simple space of module types.
Investigating Robustness of Dialog Models to Popular Figurative Language Constructs
Oct 01, 2021
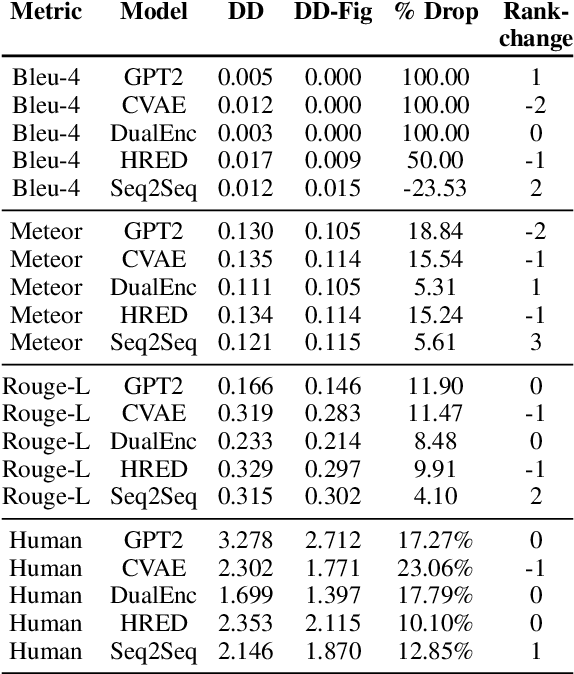
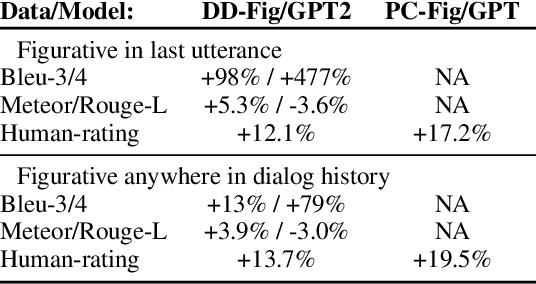

Humans often employ figurative language use in communication, including during interactions with dialog systems. Thus, it is important for real-world dialog systems to be able to handle popular figurative language constructs like metaphor and simile. In this work, we analyze the performance of existing dialog models in situations where the input dialog context exhibits use of figurative language. We observe large gaps in handling of figurative language when evaluating the models on two open domain dialog datasets. When faced with dialog contexts consisting of figurative language, some models show very large drops in performance compared to contexts without figurative language. We encourage future research in dialog modeling to separately analyze and report results on figurative language in order to better test model capabilities relevant to real-world use. Finally, we propose lightweight solutions to help existing models become more robust to figurative language by simply using an external resource to translate figurative language to literal (non-figurative) forms while preserving the meaning to the best extent possible.
Unsupervised Enrichment of Persona-grounded Dialog with Background Stories
Jun 15, 2021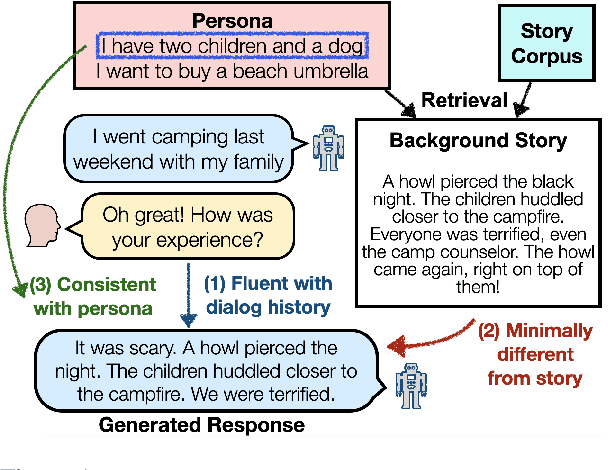
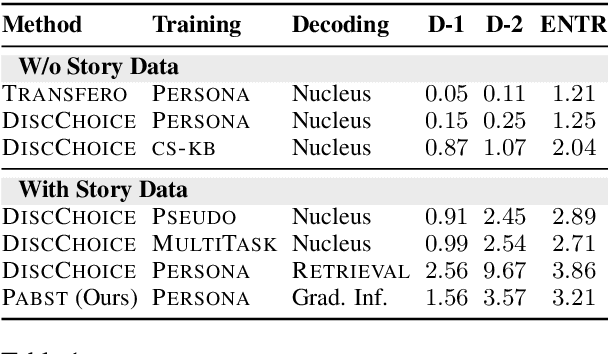

Humans often refer to personal narratives, life experiences, and events to make a conversation more engaging and rich. While persona-grounded dialog models are able to generate responses that follow a given persona, they often miss out on stating detailed experiences or events related to a persona, often leaving conversations shallow and dull. In this work, we equip dialog models with 'background stories' related to a persona by leveraging fictional narratives from existing story datasets (e.g. ROCStories). Since current dialog datasets do not contain such narratives as responses, we perform an unsupervised adaptation of a retrieved story for generating a dialog response using a gradient-based rewriting technique. Our proposed method encourages the generated response to be fluent (i.e., highly likely) with the dialog history, minimally different from the retrieved story to preserve event ordering and consistent with the original persona. We demonstrate that our method can generate responses that are more diverse, and are rated more engaging and human-like by human evaluators, compared to outputs from existing dialog models.
Improving Automated Evaluation of Open Domain Dialog via Diverse Reference Augmentation
Jun 05, 2021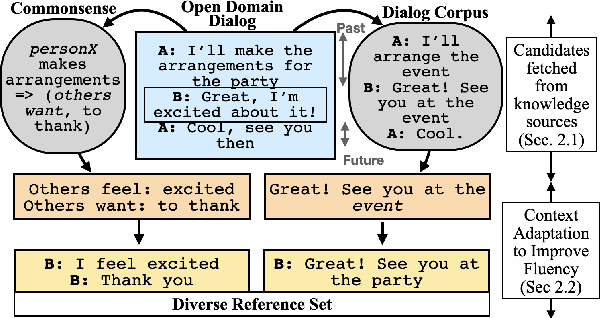



Multiple different responses are often plausible for a given open domain dialog context. Prior work has shown the importance of having multiple valid reference responses for meaningful and robust automated evaluations. In such cases, common practice has been to collect more human written references. However, such collection can be expensive, time consuming, and not easily scalable. Instead, we propose a novel technique for automatically expanding a human generated reference to a set of candidate references. We fetch plausible references from knowledge sources, and adapt them so that they are more fluent in context of the dialog instance in question. More specifically, we use (1) a commonsense knowledge base to elicit a large number of plausible reactions given the dialog history (2) relevant instances retrieved from dialog corpus, using similar past as well as future contexts. We demonstrate that our automatically expanded reference sets lead to large improvements in correlations of automated metrics with human ratings of system outputs for DailyDialog dataset.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
Learning to Explain: Datasets and Models for Identifying Valid Reasoning Chains in Multihop Question-Answering
Oct 07, 2020Despite the rapid progress in multihop question-answering (QA), models still have trouble explaining why an answer is correct, with limited explanation training data available to learn from. To address this, we introduce three explanation datasets in which explanations formed from corpus facts are annotated. Our first dataset, eQASC, contains over 98K explanation annotations for the multihop question answering dataset QASC, and is the first that annotates multiple candidate explanations for each answer. The second dataset eQASC-perturbed is constructed by crowd-sourcing perturbations (while preserving their validity) of a subset of explanations in QASC, to test consistency and generalization of explanation prediction models. The third dataset eOBQA is constructed by adding explanation annotations to the OBQA dataset to test generalization of models trained on eQASC. We show that this data can be used to significantly improve explanation quality (+14% absolute F1 over a strong retrieval baseline) using a BERT-based classifier, but still behind the upper bound, offering a new challenge for future research. We also explore a delexicalized chain representation in which repeated noun phrases are replaced by variables, thus turning them into generalized reasoning chains (for example: "X is a Y" AND "Y has Z" IMPLIES "X has Z"). We find that generalized chains maintain performance while also being more robust to certain perturbations.
Narrative Text Generation with a Latent Discrete Plan
Oct 07, 2020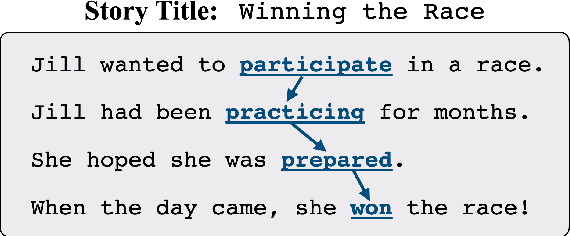
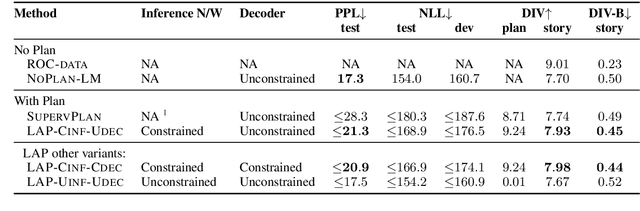
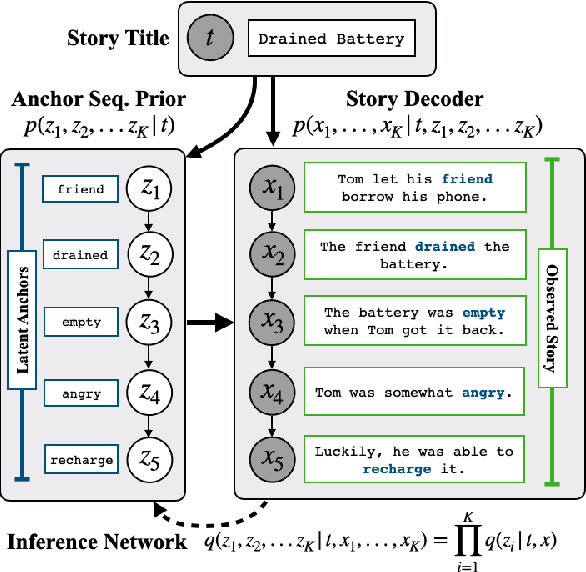
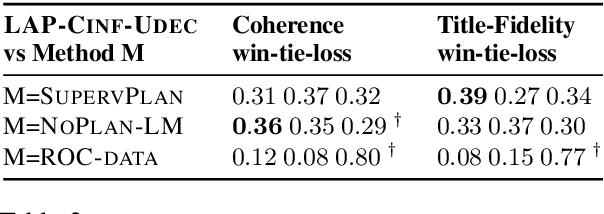
Past work on story generation has demonstrated the usefulness of conditioning on a generation plan to generate coherent stories. However, these approaches have used heuristics or off-the-shelf models to first tag training stories with the desired type of plan, and then train generation models in a supervised fashion. In this paper, we propose a deep latent variable model that first samples a sequence of anchor words, one per sentence in the story, as part of its generative process. During training, our model treats the sequence of anchor words as a latent variable and attempts to induce anchoring sequences that help guide generation in an unsupervised fashion. We conduct experiments with several types of sentence decoder distributions: left-to-right and non-monotonic, with different degrees of restriction. Further, since we use amortized variational inference to train our model, we introduce two corresponding types of inference network for predicting the posterior on anchor words. We conduct human evaluations which demonstrate that the stories produced by our model are rated better in comparison with baselines which do not consider story plans, and are similar or better in quality relative to baselines which use external supervision for plans. Additionally, the proposed model gets favorable scores when evaluated on perplexity, diversity, and control of story via discrete plan.
Like hiking? You probably enjoy nature: Persona-grounded Dialog with Commonsense Expansions
Oct 07, 2020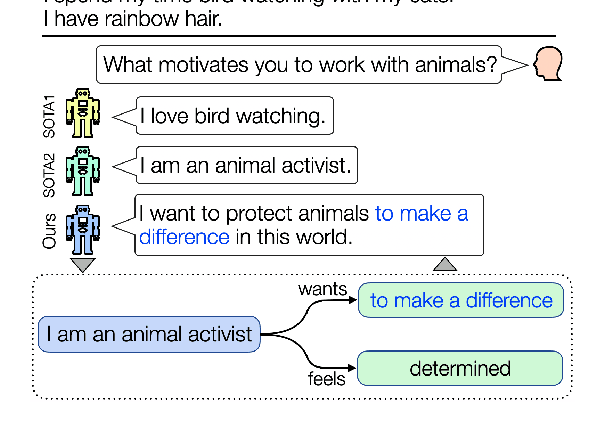

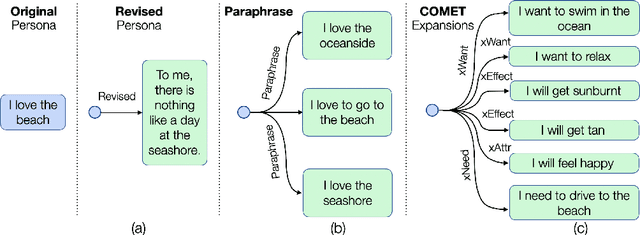
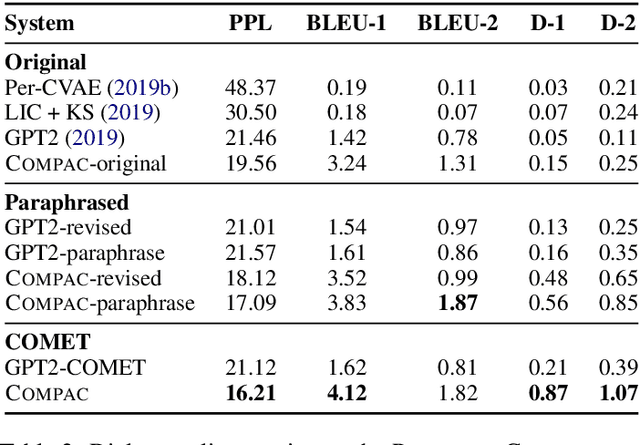
Existing persona-grounded dialog models often fail to capture simple implications of given persona descriptions, something which humans are able to do seamlessly. For example, state-of-the-art models cannot infer that interest in hiking might imply love for nature or longing for a break. In this paper, we propose to expand available persona sentences using existing commonsense knowledge bases and paraphrasing resources to imbue dialog models with access to an expanded and richer set of persona descriptions. Additionally, we introduce fine-grained grounding on personas by encouraging the model to make a discrete choice among persona sentences while synthesizing a dialog response. Since such a choice is not observed in the data, we model it using a discrete latent random variable and use variational learning to sample from hundreds of persona expansions. Our model outperforms competitive baselines on the PersonaChat dataset in terms of dialog quality and diversity while achieving persona-consistent and controllable dialog generation.